Learning Mixed Membership Community Models in Social Tagging Networks through Tensor Methods
Community detection in graphs has been extensively studied both in theory and in applications. However, detecting communities in hypergraphs is more challenging. In this paper, we propose a tensor decomposition approach for guaranteed learning of com…
Authors: Anima An, kumar, Hanie Sedghi
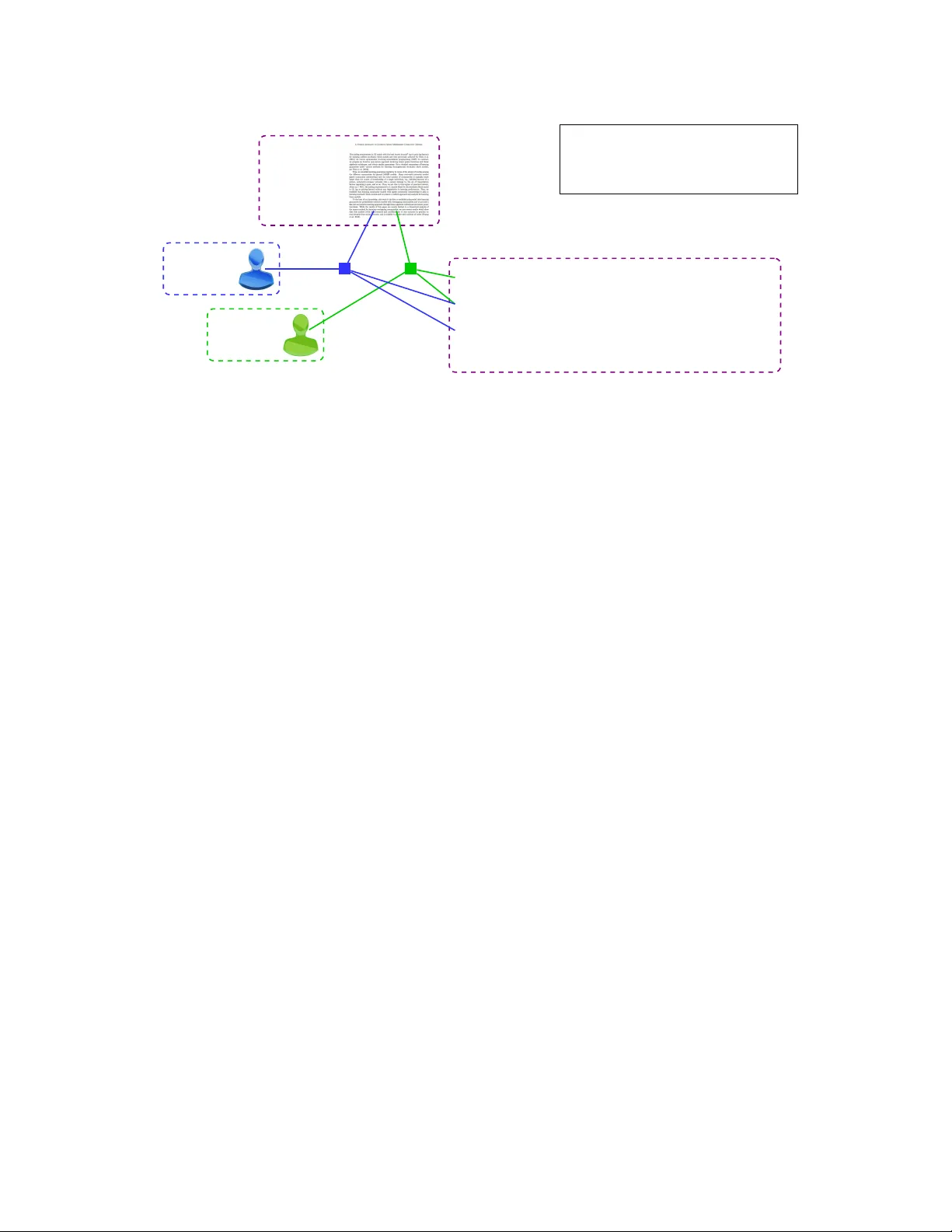
Learning Mixed Members hip Communit y Models in Social T agging Networks through T ensor Me thods Anima Anandkumar ∗ Hanie Sedghi † September 19, 2018 Abstract Community detection in gra phs has b een extensiv ely studied bo th in theo ry and in applicatio ns. Howe ver , d etecting commun ities in hypergra phs is mo re ch allenging . In th is paper, we prop ose a ten - sor decomp osition app roach for guaran teed lea rning of comm unities in a special class o f hy pergraph s modeling social tag ging systems o r folksono mies . A folkson omy is a tripartite 3- unifor m hypergr aph consisting of (user, tag, resourc e) h yperedg es. W e posit a probab ilistic mixe d membership co mmunity model, and prove that the tensor method consistently learns the co mmunities under efficient sample complexity and separation requirements. Ke ywords: Community models, social tagg ing systems/folk sonomie s, mixed members hip models, tensor decompo sition m ethods . 1 Introd uction Folks onomies or s ocial tagging s ystems (Chakrabort y et al., 2012) hav e been h ugely popular i n recent years. These are tripar tite ne tworks consis ting of users, resour ces and tags. The resources can var y according to the system. For instance, in Delicious, the UR Ls are t he re source s, in F lickr , the y ar e t he images, in LastFm, the y a re the m usic files, i n M ovi eLens, they are the re vie ws, and so on. The co llabor ati v e annota tion of these resour ces by users with descripti ve key words , ena bles fast er search and retrie v al (Chakrabort y and Ghosh, 2013). The role of community detection in folksono mies cannot be ov erstate d. Online social tagging systems are growin g rapi dly an d it is important to group the nod es (i.e. users, resources an d tags) for scalable operat ions in a number of app licatio ns such as pe rsonal ized search (X u et al., 2008), resource and frien d recommend ations (K onstas et al., 2009), and so on. Moreo ver , learni ng communiti es can prov ide an under - standi ng of community format ion beha vior of human s, and the role of communities in human interactio n and collab oration in online systems. Folks onomies are special instances of hyper grap hs. A folksonomy is a tripart ite 3 -uniform hyperg raph consis ting of hypere dges between users, resour ces and tags. Scalable community detection in hyper graphs is in general challenging , and most pre vious works are limited to pure membership models, where a node belong s to at most one group . This is highly unrealistic since users ha ve multi ple intere sts, and the tags ∗ Univ ersity of California, Irvine, Email: a.anandku mar@uci.edu † Univ ersity of Southern California, Email: hsedghi@usc.edu 1 and resources hav e multiple contexts or topics . A fe w works which do consi der over lappin g communities in folksonomies are heuris tic without any guarante es and do not incorporat e any statistic al modeling (s ee Section 1.2 for details) . In this paper , we propose a no v el probabilist ic approach for mode ling folksonomies, and propose a guaran teed approach for dete cting ov erlap ping communities in them. A nai ve model for folksnomies would result in a larg e number of model parameters, and make le arning intractable. Here we pres ent a more scalab le approa ch where realistic co nditio nal indepen dence constrai nts are imposed, lead ing to scalabl e modeling and tracta ble learni ng. Our model i s a hyper grap h exten sion of th e popular mixed member shi p stoc hasti c bloc kmodel (MMSB), introd uced by Airoldi et. al (Airoldi et al., 2008). W e impose additio nal condition al independen ce co n- straint s, which are natural for social tagging systems. W e term our model as mixed membership stocha stic folkso nomy (MMSF). When hyper graphs are ge nerate d from such a clas s of MMS Fs, w e sho w that the hyper -edges can be much mor e informativ e about the underlying communities, than in the gra ph setting. Intuiti vely , this is becau se the hyper -ed ges represe nt multiple views of the the hidden communities. In this paper , w e sho w that these proper ties can be exp loited for learning via spectral approaches . 1.1 Summary of Results W e de v elop a prac tically rele v ant mix ed members hip hype r graph model and pro pose nov el metho ds to learn them w ith guarant ees. W e posit a probabilist ic model for generati on of hyper -edges { r , u, t } between resour ces r , us ers u and tags t . W e impose natural condi tional indepe ndence assumption s t hat cond itione d on the community membership s of indivi dual nodes, the hypere dge genera tions are indepe ndent . In addition, we assume that the users select tags for a giv en resource, bas ed on the context in which the resou rce is access ed. For instance, con sider the resource as a paper that falls both in theoretica l and applied machine learnin g, as shown in F igure 2. If a user accesses the resource under the contex t of theory , he/she uses tags that are indicati ve of theory . Note that we allo w the users and tags to be in multiple communities; ho we ve r , the actual realization of an hyper -edg e depends only on the conte xt in which the resource was access ed. Depend ing on what kin d of user i s tag ging the paper , the like lihood of choo sing va rious tags su ch as ap plicati on, latent v ariab le model etc changes. T he conditional indepe ndence assumption states th at o nce a user accesses the paper in certain conte xt (e.g. looking for applicatio ns), the probability of using tags in a cate gory (e.g. applications , expe riments) only depends on that conte xt. There are many other such examples . For e xample, a movie can be a drama about a political fi gure. A person who is mostly in to politics will watch this mo vie i n the c onte xt of po litics and us e politi cal tags (for e xampl e name o f the p erson, speci fic politic al e ven ts that w here illustrated in the movie ), while a person w ho is more into drama genre will use drama to tag the movie. While community models on genera l hyper grap hs is N P hard, our setting is geared to wards the setting of folkso nomies with users, resource s and tags, and the assumption s we make naturall y hold in this set- ting. Importantly , w e allow for general distrib utio ns for mixed community memberships. The earlier work by Anandku mar et al. (2014a) on MMSB models on gra phs is limited to the Dirichl et distrib utio n. Note that the Dirichlet assu mption for communi ty memberships can be limiting an d cannot m odel general cor - relatio ns in memberships. W ith out the Dirichlet assumption, the earlie r technique s, when applied directly , would yield tensors in the T uck er form, which do not possess a unique de composi tion an d thus, the co m- munities cannot be learnt from the tensor forms. In additio n, our moment forms are dif fere nt since it is the hyper graph setting and conditiona l in depen dence assumptions are dif feren t. Thus, earlier work on MMSB canno t be directl y applied here. In addit ion, we impose weak assumption s on the distrib ution of the community memberships. This is 2 requir ed since the memberships are in gener al not identi fiable when the y are mixed. Whil e the original MMSB model (Airoldi et al., 2008) assumes that the communities are drawn from a Dirichlet distrib ution, here, we do not requi re such a strong parametri c assump tion. Here, we impose a weak assumption that a certain fractio n of reso urce nodes a re “p ure” and belong to a single communit y . This is reasonable to e xpec t in practic e. W e establish that the communities are identifiable under these natural assumptions , and can be learnt ef ficiently using spectral approa ches. Here, we propose a nov el algorithm to detect pure nod es be longin g to a sing le co mmunity . The presence of pure nodes is natur al to expect in practic e and does not require the Dirichlet assu mption. Our method consis ts of two main routines . First, we design a simple rank test to identify pure resource nodes. The algori thm in v olv es first projecting hy pered ges to sub space o f top-k eigen vecto rs. It then in volv es p erformin g rank tes t on the matriciz ation of con necti vity vectors of each re source nod e, where ro w s c orresp ond to users and columns correspo nd to tags. W e can then exploit these detected pure nodes to form tensors that can be decompo sed efficien tly to yield the communiti es for all the nodes (and not just the pure nodes). W e prove that our propo sed method correctl y recove rs the parameters of the MMSF model when exac t moments are input. T his two stage algorith m is expec ted to ha ve much wider applicab ility than the M MSB model which is limited to the Dirichle t d istrib ution. For this general model, we show a tight sample comple xity that n > k 3 can reco ver the communi ties. For the first step, we construc t a matrix for each resource node, consistin g of its edges to users and tags. W e sho w that this matrix i s rank- 1 in expe ctation (ov er the hyper edges) for a pure res ource node. This proper ty enables us to ide ntify such pure no des. W e then co nstruc t a 3 -star count tens or using these estimate d pure resour ce nodes. W e count the pure resource nodes, which are common to triplets of (user ,tag) tuples to form the tens or . W e sho w that in ex pectat ion this tensor has a CP decomposit ion form, and requirin g this decompo sition yields the community membership s after some simple pos t-proce ssing steps. W e the n carefully analy ze the perturb ation bound s unde r empiric al moments , and sho w that the com- munities ca n be accurately reco vere d under some natural assumpt ions. The pertu rbation analysi s for this step is nov el sinc e it requires analyzi ng the ef fect of standar d spectral pertu rbatio ns on m atriciz ation and the subsequ ent rank test. W e use sube xpone ntial Hanson Wright inequali ties to obtain tight guarante es for this ste p. These assump tions determine ho w the number of nodes n is relate d to the nu mber of communities k , an d a lo wer bo und on the se paratio n p − q , where p denote s the conne cti vity within the same commu- nity , w hile q denotes the conne cti vity across dif feren t communities. Such requirements hav e been imposed before in the graph setting, for stochastic block models (Y udong et al., 2012) and mixed membership mod- els (Anandku mar et al., 2014a). Here, w e show that for MMSF , the require ment is stronge r , since in tuiti vely , we require conce ntratio n on a hy per grap h instead of a gr aph. W e empl oy sub-exp onent ial forms of Han- son Wright’ s ineq uality to get tight bou nds in the sparse re gime, where the connecti vity proba bilities p, q are small. Thus, we obtain efficien t guarante es for recov erin g mixed membership communities from social taggin g networks. W e establish that for the success of ra nk test, if p ≃ q , we need the ne twork size to scale as n = ˜ Ω k 3 (when the correlation matrix of community m embership distrib uti on is well-condi tioned ). For the case where q < p/k , w e require n = ˜ Ω k 2 . This is intuiti ve as the role of q is to make the dif ferent community compone nts non-orth ogona l for the rank test, i.e., q acts as noise. Therefore , a smaller q results in better guarantee s. For the success of ten sor decompositio n method, w e require n = ˜ Ω k 3 , w hen p, q are constants, in the w ell-con dition ed settin g. N ote that in comparison, for learnin g m ixed membership stocha stic block model graphs, we requir e n = ˜ Ω k 2 , from A nandk umar et al. (2014a ), which is lo wer sample complex ity . This is because we need to learn m ore number of parameters in the hyper grap h setting. Moreo ver , for sparse graphs, the parameters p, q decay with n , and we also handle this setting, and provid e 3 the precise bound s in Section 4. 1.2 Related W ork There is an ext ensi v e body of work for co mmunity detection in graphs. Popular methods with guarante es includ e spectral clustering (McSherry, 2001) and con vex optimizatio n (Y udong et al., 2012). For a detailed surv ey , see (Anan dkumar et al., 2014 a). H o we ver , the se meth ods can not handle mix ed membership models, where a node can belon g to more than one community . Our algorith m is based on the tensor decomposit ion approach of (Anandkuma r et al., 2013) for pair- wise MMSB model in graph s. The m ethod has been implement ed for many real-wo rld datasets and has sho wn significant improve ment in running times and accuracy over the state of art stocha stic v ariatio nal techni ques (Huang et al. , 2013). The tensor consists of third order m oments in the form of count s of 3 -star subgra phs, i.e., a star subgrap h consi sting of three lea v es, for each triplet of leav es. The MMS B model as- sumes a D irichle t distrib ution for community membership s, and in this case, a modified 3 -star count tensor is us ed. It is sho wn th at this tensor has a CP -decomposi tion form, and the compone nts of th e dec ompositi on can be used to learn the parameter s of the MMS B model. H o wev er , this method cannot be extende d easily to gen eral distr ib ution s, be yo nd the Diric hlet assump tion, since for gene ral distri b utions , the 3 -star count tensor only has a T ucker decompositi on form, and not a CP form. In general, the model parameters are not identi fiable from a T uck er form. Thus, in graphs, mixed membership m odels cannot be easily learnt when genera l distrib utions (be yond the Dirichlet distrib ution) for mixed members hips are assumed. In this paper , we sho w that in the h yper graph setting , more gene ral d istrib utions of community memberships can be l earnt, when certain conditi onal indepe ndence relationship s are assumed for hyper- edge generation . Another limitati on of t he MMSB model is that due to the Diri chlet assumpt ion, only norma lized commu- nity m embershi ps can be incorpora ted. Howe ver , in t his c ase, the m ixed nodes ( i.e. those bel ongin g to more than one community ) are less densely connected t han the p ure nodes, a s pointed ou t by (Y ang and Lesko v ec, 2013). In contra st, in our paper , we can handle un-n ormalize d community membership s vectors (in a weighted gr aph), since we do not make the Dirichlet assumptio n, and thus , this limita tion is no t present . Ho wev er , for simplicity , we present the results in the normalize d setting . Scalable community detection in hyperg raphs is in general challengin g and most pre viou s work s are limited to pure membership mode ls, where a node belongs to at most one group (Brinkmeier et al., 2007; Lin et al., 2009; M urata, 2010; N eubaue r and O bermayer, 2009; V azquez, 2009). Clustering in multipart ite hyper graphs can be seen as exte nsion s of the co-cluster ing of matrices , where ro ws and columns are simul- taneou sly clustere d. In (Je gelka et al., 2009), extensio ns of co-clusteri ng to the tensor setting is considered . Ho wev er , this setting ca n only handle pure co mmunities, w here a node belongs to a t most one community . A fe w works which do consider mixed communitie s in hyperg raphs are heuristic without any guarantees, and do not inc orpora te an y statistical modeling (W ang et al., 2010; Chakrabo rty et al., 201 2; Papado poulos et al., 2010). T hey mostly use modularity bas ed scores witho ut providin g an y guarantees. In th is paper , we present the first guaran teed method for learnin g communities in mixed membership hyper graphs. 2 Mixed Membership Model f or F olksonom ies Setup: W e consider folksonomies modeled as tripartite 3 -uniform hyper graph s ove r three sets of nodes, viz., set of users U , set of tags T and set of resources R . An hyperedg e { u, t, r } occurs when user u tags resour ce r with tag t . For con ven ience, we will consider a matricized versio n of the { 0 , 1 } hyper -adjacenc y tensor , de noted by b G ∈ { 0 , 1 } | U |·| T |×| R | , which indica tes the presence of hyper -edges. The reason behind 4 Communities: 1) T -ML: Theoretical Machine Learning 2) A-ML: Applied Machine Learning 90% T - ML 10% A-ML User 1 10% T - ML 90% A-ML User 2 55% T - ML 45% A-ML Resour ce 1 Applicat ions ( 20% T -ML, 80% A-ML ) Latent V ariable Models ( 35% T -ML, 65% A-ML ) Theoretic al Guarantees ( 95% T -ML, 5% A-ML ) · · · T ags Figure 1: Overvie w of MM SF model for an example of machine learnin g articles (resource s) tagged by users. One article (resource) and the correspo nding tags by two users are sho wn. T wo communites of The- oretica l machine learni ng and Applied machine learnin g are assumed. The mixed community membership of resou rces, users and tags are also sho wn. consid ering matricizat ion along th e res ource mod e will soon be come clea r . W e use the notation b G ( { u, t } , r ) to de note the entry correspo nding to the hyper -edge { u, t, r } , and b G ( { U, T } , r ) to denote the column vec tor corres pondin g to the set of hype r -edge s { U, T , r } . W e consider models with k underlying (hidden ) communities and let [ k ] := { 1 , 2 , . . . , k } . For node i , let π i ∈ R k denote its communi ty member ship vector , i.e., the vecto r is suppor ted on the commun ities to which the node belongs. Define Π U := [ π i : i ∈ U ] ∈ R k ×| U | denote the set of colu mn vec tors denot ing the community membership s of users in U , and similar ly define Π T and Π R . Let Π := [ π i : i ∈ U ∪ T ∪ R ] . W e no w provi de a statistica l model to explain the pr esence of hyper -edges { u, t, r } among users, tag s and resources throu gh the community membership s. W e con sider a mixed memberships model, where there are multiple communities for users, tags and resources. Intuiti ve ly , users belonging to certain groups (i.e. interes ted in certain top ics) will tend to select res ource s mainly comprised of those topics. The tags emplo yed by the users are depen dent on the conte xtual cat ego ry of the resourc e selected by the user . This intuiti on is formali zed under our pro posed statistical m odel belo w . Let z u →{ t,r } ∈ R k be a coordi nate basis v ector w hich denotes the co mmunity membersh ip of user u when posting tag t and resource r , and similarly let z r →{ u,t } , z t →{ u,r } denote the m embershi ps of resource r and tag t when partic ipatin g in the hyper edge { u, t, r } . Let P ∈ R k × k be the community connec ti vity matrix, where P i,j denote s the probability that a user in community i selects a resour ce in community j . Simila rly , let ˜ P ∈ R k × k denote a matr ix such tha t each entry ˜ P i,j denote s the probability that a tag in community i is associated with resource in community j . The propo sed m ixed members hip stochasti c folkson omy (MMSF) is as follo ws: • For each node in i ∈ U ∪ T ∪ R , draw its community m embershi p vector π i ∈ R k , i.i.d. from some distrib ution f π . • For each triplet { u, t, r } , dra w coordinat e basi s vec tors z u →{ t,r } ∼ Multinomial ( π u ) , z t →{ u,r } ∼ Multinomia l ( π t ) and z r →{ u,t } ∼ Multinomia l ( π r ) in a conditi onally independen t manner , giv en Π . 5 • Draw rando m vari ables b B r → u ; t ∼ Berno ulli ( z ⊤ u →{ t,r } P z r →{ u,t } ) b B r → t ; u ∼ Berno ulli ( z ⊤ t →{ u,r } ˜ P z r →{ u,t } ) . (1) The presen ce of hyper -ed ge G ( { u, t } , r ) is giv en by the produ ct b G ( { u, t } , r ) = b B r → u ; t · b B r → t ; u . (2) The use of v aria bles z u →{ t,r } , z t →{ u,r } and z r →{ u,t } allo ws for cont e xt-dep enden t selec tion of group membership s as in the MMS B m odel. Giv en a resourc e and its conte xt, a user may ch oose to access th e resour ce, and probability of using a tag on a reso urce depends on conte xt of the tag and the resou rce. Give n the conte xt of user , tag and the resource , thes e two eve nts are indepe ndent. In order to hav e a hyper -edg e, we need both e ve nts to happen and this explain s E qn. (2). Ours is a resource centric model, where a r esourc e can b e reg arded as comprising of many topics or com- munities . Which tags get associ ated with the resource is depende nt on the context of the resource z r →{ u,t } and the tag z t →{ u,r } and similarly , whic h user selects a resourc e is depend ent on the conte xt of the user ( z u →{ t,r } ) and the resource z r →{ u,t } . The hyper -edge s are drawn according to (2) an d thus, matrici zation along the resourc e mode is con venient for analysis. Our model is resour ce centric and not user centric. The intuiti on is that the tags associated with a resource are depend ent on the conte xt that the resource is being access ed and the likeliho od of the user accessin g a resour ce is dependent on his/her current group and the conte xt of the resourc e. Figure 2 provides an inst ance of a hyperg raph where the resource is a paper and communitie s consist of theor etical and applie d m achine learnin g. Unlik e the pairwise MMSB model (Airol di et al., 2008), where the edges are condi tional ly independ ent gi ve n the community members hips, in the propo sed MM SF model, th e edges b B r → t ; u and b B r → u ; t contai ned in the hypered ge { u, t, r } are not conditi onally independen t gi v en the community memberships, since they are selected based on the common contex t z r →{ u,t } of the resource r . Thus, the M MSF model is capturi ng depen dencie s bey ond th e pairwise MMSB model. At the same time, the MMS F model ha s co nditio nally indepe ndent hyperedges giv en the community membership s, w hich leads to tractab le learnin g. W e do no t take the approac h of modelin g hyperedges directly , i.e., through a community co nnecti vity tensor in ˜ P ∈ R k × k × k , w here ˜ P a,b,c would gi v e the probabil ity that a user in community a would ha ve an hyperedg e w ith resou rce b and tag c . This would lead to k 3 unkno wn parameters, while our model has only k 2 unkno wn parameters. Moreov er , if the user at a certain point is interes ted in some topic (i.e. draws z u →{ t,r } in some community) , then he looks for resources and tags having significan t m embershi p in tha t topic (modeled through dra ws of z t →{ u,r } and z r →{ u,t } ) and this will generate the hyper -edge u → { t, r } . W e as sume that th e community v ect ors a re drawn i.i.d. from a gen eral u nkno wn distrib ution: for i ∈ [ n ] , π i i.i.d. ∼ f π ( · ) , suppo rted on the k − 1 -dimensiona l simplex ∆ k − 1 ∆ k − 1 := { π ∈ R k , π ( i ) ∈ [0 , 1] , X i π ( i ) = 1 } . The performan ce of our learning algorit hms will depend on the distrib ution of π . In particul ar , we assume that with probability ρ , a re alizati on of π is a coordinate basis v ector , and thus, abo ut ρ fraction of the nodes in th e net work ar e pur e , i.e. they belong mostly to a single c ommunity . In t his p aper , we in vesti gate ho w the tractab ility of learni ng the communitie s depends on ρ . 6 A B C P S f r a g r e p l a c e m e n t s ˜ R { u i , t i } Figure 2: Our moment-base d learnin g algorith m uses 3-star count tensor from set X to s ets A, B , C . 3 Pr oposed Method Notation: For a matrix M , if M = U D V ⊤ is the SVD of M , let k-svd( M ) := U ˜ DV ⊤ denote the k -rank SV D of M , where ˜ D is limited to top- k singular v alues of M . A matrix A ∈ R p × q is stacked as a vec tor a ∈ R pq by the v ec( · ) operator , a = v ec( A ) ⇔ a ( i 1 − 1) q + i 2 ) = A ( i 1 , i 2 ) . The re ve rse matricization operation is den oted by mat( · ) , i.e. abo v e A = mat( a ) . Let A ∗ B denote the H adamard or entry-wise product. Let k-svd( M ) of a matrix M denote its restrict ion to top- k singul ar v alues, i.e. if M = U Λ V ⊤ , k-svd( M ) = U k Λ k V ⊤ k , which denote the restriction of the subspace s and the singul ar v alues to the top- k ones. In this paper , we consider the pr oblem o f le arning the community v ectors π i , for i ∈ [ n ] , gi ven a realiza tion of the (matriciz ed) hyper -adjacenc y matrix G ∈ R | R |×| U |·| T | . W e will emplo y a cluste ring-b ased approa ch on the hyper -ad jacenc y matrix, bu t employ a diffe rent clusterin g criterion than the usual distance based cluster ing. our metho d is shown in Algor ithm 1. Our method relies on finding pur e resource nodes and using them to find communities for the resource, tag and users. A pure resource node is a node that is mainly co rrespo nding to one hidden community . Therefore , finding th at node pa ves the way for finding resource communiti es. In additio n, since this is a resour ce-cen tric model, looking at the subset of hyper graph with pure resources, all tags and all users, suf fices to find the communities for users and tags as well. Since we assume kno wledge of community conne cti vity matrices , w e can learn community membersh ips for mixed resource nod es as well. W e no w pro vide the details of our propose d method. Pro jectio n matrix: W e partiti on the resourc e set R into two parts X and Y to av oid dependen cy issues between the pr ojectio n matrix and the proj ected vecto rs, and this is standar d for analysis of spectr al cluster - ing. No w let k-svd( b G ( { U, T } , Y )) = M k Λ k V ⊤ k and we employ P c ro j := M k M ⊤ k as the projection matrix. W e project the vectors b G ( { U, T } , x ) for x ∈ X using thi s projection matrix. Rank test o n pr oje cted vecto rs: In the us ual spectra l clusterin g m ethod, on ce we ha ve projec ted vector s P c ro j b G ( { U, T } , x ) ∈ R | U |·| T | , any distanc e based cluster ing can be employe d to class ify the vectors into dif feren t (pure) communities. Ho we ve r , when mixed membership nodes are present, this method fails. W e propo se an alterna ti ve method which considers a rank test on the (matricize d form of) the pro jected vec tors. Specifically consid er the matricized form mat(P c ro j b G ( { U, T } , x ) ∈ R | U |×| T | and check whether σ 1 (mat(P c ro j b G ( { U, T } , x ))) > τ 1 and σ 2 (mat(P c ro j b G ( { U, T } , x ))) < τ 2 7 and if so , dec lare th e node x ∈ X as a pur e node . Interchange ro les of X and Y and similarly find pure nodes in Y . Learning using est imated pure nodes: Once the pure n odes in resource set R are fo und, we can emplo y the tens or decompos ition method, proposed in (Anan dkumar et al., 2014a), for lea rning the mixe d member - ship communiti es of all the no des. The pure nodes are emplo yed to obt ain a vera ged 3 -star subgraph counts . Partiti on { U, T } into three sets A, B , C as sho wn in Figure 2. The 3 -star subgraph count is defined as b T ˜ R → A,B ,C := 1 | ˜ R | X r ∈ ˜ R b G ( r , A ) ⊤ ⊗ b G ( r , B ) ⊤ ⊗ b G ( r , C ) ⊤ , (3) where ˜ R denote s the set of pure resourc e nodes. The method is explai ned in Appendix B. Reconstructio n after p ower method: Since we do not hav e access to the exact moments we need to do additi onal proces sing: the es timated co mmunity members hip v ect ors are then su bject to thresh olding so that the weak val ues are set to zero . T his modification makes our reconstructi on strong as we are con sideri ng sparse community memberships . Also note that assuming knowledg e of community conne cti vity matrices, we can learn community m embershi ps for mixed resource nodes as well. This is shown in Algorithm 3 in the Appendix . Algorithm 1 { b Π } ← LearnMix edMembersh ip ( b G , k , τ 1 , τ 2 ) Input: Hyper -adj acenc y matrix b G ∈ R | U |·| T |×| R | , k is the numb er of communiti es, and τ 1 , τ 2 are th reshol ds for rank test. Output: Estimates of the community membershi p vectors Π . 1: Partitio n the resource set R randomly into two parts X , Y . 2: ˜ R = Pure Resource Nodes Detection ( X, Y , U, T ) . 3: b Π ← T ensorDec omp ( b G ( { U, T } , · ) , ˜ R ) 4: Return b Π . Pro cedur e 2 Pure Resource Nodes Detection Input: X, Y , U, T . 1: Construct Projectio n m atrix P c ro j = M k M ⊤ k , where k-svd( b G ( { U, T } , Y )) = M k Λ k V ⊤ k . 2: Set of pure nodes ˜ R ← ∅ . 3: fo r x ∈ X do 4: if σ 1 (mat(P c ro j b G ( { U, T } , x ))) > τ 1 and σ 2 (mat(P c ro j b G ( { U, T } , x ))) < τ 2 then 5: ˜ R ← ˜ R ∪ { x } . { Not e mat(P c ro j b G ( { U, T } , x )) ∈ R | U |×| T | is matricizati on } 6: end if 7: end fo r 8: Intercha nge roles of X and Y and fi nd pure nodes in Y . 9: Return ˜ R . 8 4 Analysis of the Learnin g Algorithm Notation: L et ˜ O ( · ) denote O ( · ) up to poly-log fact ors. W e use the term high probab ility to mean with probab ility 1 − n − c for any cons tant c > 0 . 4.1 Assumptions For simplicity , we assu me that the community memberships of resources, tags and us ers are drawn from th e same distrib ution . Further , we co nsider equ al e xpec ted communi ty sizes , i.e. E [ π ] = 1 /k · 1 ⊤ . Additional ly , we assume that the community connec ti vity matrices P , ˜ P are homogeneou s 1 and equal P = ˜ P = ( p − q ) I + q 11 ⊤ . (4) These simplificatio ns are merely for con veni ence, and can be easily remov ed. Require ment fo r success of rank test: W e require that 2 n = ˜ Ω σ k ( E [ π π ⊤ ]) − 3 · κ ( E [ π π ⊤ ]) − 2 · ( p − q ) /k + q ( p − q ) / √ k + q 2 ! , (5) where κ ( · ) denote s the condition number and σ k ( · ) denotes the k th singul ar v alue. W e assume that m ax i ∈ [ k ] π x ( i ) = 1 − ǫ, ǫ = O (1) and hence there exists no node such that th eir π is between 1 and π max . Require ment f or success of tensor deco mposition: Recall tha t the tensor method uses only pure re - source nodes. Let ρ be the fractio n of such pure resource nodes . L et w i := P [ π r ( i ) = 1 | r ∈ ˜ R ] . For simplicit y , w e assume that w i ≡ 1 /k . Again, this can be easily e xtende d. W e require the separation in edge connecti vity p − q to satisfy ( p − q ) 2 p = ˜ Ω √ k √ nρ · σ k ( E [ π π ⊤ ]) ! . (6) Intuiti vely this implies that there should be enoug h separation between connec ti vity w ithin a communit y and conne cti vity across communitie s. Dependence on p , q : Note th at for the rank test, (5), in the well-co nditio ned set ting we ha ve σ k ( E [ π π ⊤ ]) = O (1 /k ) . Then if p ≃ q , we need n = ˜ Ω k 3 . For the case where q < p/k , w e w ill require n = ˜ Ω k 2 . This is intuiti ve as the role of q is to make the components non-orth ogona l, i.e., q acts as noise. Therefore, smaller q results in better gu arante es. For the tensor dec omposit ion method, (6), in the w ell-con dition ed setting , if we hav e n = ˜ Ω k 3 , this means p, q are constants. Alternati vely , for sparse graphs, we want p, q to decay . Accord ing to the constrain ts, w e need a large r n . This is intuiti v e as in case of sparse graphs we need fewer observ atio ns and le ss inf ormation about unkn o wn community memberships. Therefore, we need more samples. Note that Anandkumar et al. (2014 a) require n = O ( k 2 ) while we need n = O ( k 3 ) . T he reason is that we are estimating a hyper graph (they estimate a graph ) and we are estimating more parameter s in this model. Therefore, we need more samples. 1 Our results can be easily extended to the case when P and ˜ P are full rank. 2 ˜ Ω , ˜ O r epresent Ω , O up to poly-log factors. 9 4.2 Guarantees W e no w estab lish main results on recov ery at the end of our alg orithm. W e first sh o w th at un der the assump- tions in the pre vious section, we obtain an ℓ 2 guaran tee for reco ve ry of the membership weights of source nodes in each community . W e should note that this result can be extended to reco ve ry of membership for tag and user nodes as well. In this case, there will be additio nal perturba tion terms. Let ˜ Π be the reconst ructio n of communities (of resourc es, users and tag s) usin g the tensor m ethod in Algorith m 3 in the A ppendi x, b ut before threshold ing. For a matrix M , let ( M ) i denote the i th ro w . Recall that (Π) i denote s the memberships of all the nodes in the i th community , sinc e Π ∈ R ( | R | + | U | + | T | ) × k . W e ha ve the foll o wing result: Theor em 1 (Reconstruction of communities (befor e th r esholding)) W e have w . h.p. ǫ π := max i ∈ [ k ] k ( ˜ Π) i − (Π) i k 2 = ˜ O √ k · p · κ ( E [ π π ⊤ ]) √ ρ ( p − q ) 2 ! . (7) Remark: Note that the ℓ 2 norm abo v e is taken ov er all the no des of the network and we e xpect this to be O ( √ n ) if error at each node is O (1) . Assuming E [ π π ⊤ ] is w ell condit ioned and w hen ρ, p, q = Ω(1) , we get a better guarant ee that ǫ π = O ( √ k ) . No w we further sho w that when the distrib utio n of π is “mostly” sparse, i.e. each node’ s membership vec tor does not hav e too m any lar ge entries, w e can improv e the above ℓ 2 guaran tees into ℓ 1 guaran tees via thresh olding . Specifically , assuming that the distrib ution of π satisfies P [ π ( i ) ≥ τ ] ≤ C k log(1 /τ ) , ∀ i ∈ [ k ] for τ = O ( ǫ π · k n ) , we hav e the followin g result. This is equiv alent to the case that the tail τ is expo nentia lly small in k , i.e., sparsity . Remark: Dirichl et distri b ution satisfies th is assumpt ion when P i α i < 1 , whe re α i repres ent the Diric h- let concen tration parameters. Theor em 2 ( ℓ 1 guarantee fo r r econstruct ion after thre sholding) W e have k ˆ Π i − Π i k 1 = ˜ O ǫ π · r n k = ˜ O √ n · p · κ ( E [ π π ⊤ ]) √ ρ ( p − q ) 2 , (8) wher e ˆ Π i is the r esult of thr eshold ing with τ = O ( ǫ π · k n ) . Remark: Note that the ℓ 1 norm abo v e is taken ov er all the no des of the network and we e xpect this to be O ( n ) if error at each node is O (1) . Assuming E [ π π ⊤ ] is well condi tioned and when ρ, p , q = Ω (1) , we get a better guaran tee of O ( √ n ) . Hence, we obtain good error guarante es in both cases on ℓ 1 and ℓ 2 norms. For pro of of the Theorems, see Appendix C. 10 5 Overview of Proof 5.1 Analysis of Graph Moments under MMSF 5.1.1 Ove rvie w of K r onecker and Khatri-Rao pr oducts: W e require the notion s of Kroneck er A ⊗ B and K hatri-Rao products A ⊙ B between two matrices A and B . First we d efine the Kr onec k er pr oduct A ⊗ B between matrices A ∈ R n 1 × k 1 and B ∈ R n 2 × k 2 . Its ( i , j ) th entry is gi ve n by ( A ⊗ B ) i , j := A i 1 ,j 1 B i 2 ,j 2 , i = { i 1 , i 2 } ∈ [ n 1 ] × [ n 2 ] , j = { j 1 , j 2 } ∈ [ k 1 ] × [ k 2 ] . Thus, for two v ectors a and b , we ha v e ( a ⊗ b ) i := a i 1 b i 2 , i = { i 1 , i 2 } ∈ [ n 1 ] × [ n 2 ] . For t he Khatri-Rao produ ct A ⊙ B between matrices A ∈ R n 1 × k and B ∈ R n 2 × k , we ha v e its ( i , j ) th as A ⊙ B ( i , j ) := A i 1 ,j B i 2 ,j , i = { i 1 , i 2 } ∈ [ n 1 ] × [ n 2 ] , j ∈ [ k ] . In other words , we hav e A ⊙ B := [ a 1 ⊗ b 1 a 2 ⊗ b 2 . . . a k ⊗ b k ] , where a i , b i are the i th columns of A and B . Note the differ ence between the Kronecke r and the Khatri-Rao produ cts. While the K roneck er product expa nds both the number of rows and columns, the Khatri-Rao produ ct preserve s the original number of columns. W e will also use anot her simple fact that ( A ⊗ B )( C ⊗ D ) = AC ⊗ B D. (9) 5.1.2 Result on Corr ectnes s of the Algorithm Recall that P ∈ [0 , 1] k × k denote s the connec ti vity m atrix between communities of users and resources and ˜ P ∈ [0 , 1] k × k denote s the correspondi ng connecti vity between communities of resources and tags. Define F := Π ⊤ U P , ˜ F := Π ⊤ T ˜ P . (10) Let F u = π ⊤ u P be the ro w vector corres pondi ng to user u and similarly ˜ F t corres ponds to tag t . Similarl y , let F A = Π ⊤ A P be the sub-matrix of F . W e now pro vide a simple result on the a ver age hyper -edg e conne cti vity and the form of th e 3 -star counts , gi ve n the community memberships. Pro position 1 (Form of Gra ph Moments) Under the MM SF model pr oposed in Section 2, we ha ve that the gen erat ed hyper -graph b G ∈ R | U |·| T |×| R | satisfi es G := E [ b G | Π] = ( F ⊙ ˜ F )Π R , (11) wher e ⊙ denot es the Khatr i-Rao pr odu ct. Mor eover , for a given re sour ce r ∈ R , the column vector b G ( r , { U, T } ) has condition ally independ ent entries given the community membership vector π r . If ˜ R ⊂ R is the set of (e xact ly) pur e nodes, then the 3 -star count defined in (3) satisfi es T ˜ R → A,B ,C := E [ b T ˜ R → A,B ,C | Π] = X i ∈ [ k ] w i ( H A ⊗ H B ⊗ H C ) , (12) 11 wher e w i is w i := P [ π r ( i ) = 1 | r ∈ ˜ R ] , and H A := F U ( A ) ⊙ ˜ F T ( A ) , and similar ly , H B and H C . The abo ve results follo w from modeling assumptions in Section 2, and in particular , the condition al inde - pende nce relationship s among the dif ferent va riable s. For details, see A ppendi x A . In (11), no te that a if column of G ( X ; { U, T } ) co rrespo nds to a pure node x ∈ X , th en the matrix has rank of one, since π x corres ponds to a coordina te basi s vector . On the other hand, for the case where columns corresp ond to mixed nodes , the matrix has rank bigger than one. Thus, the rank criterio n succeed s in ident ifying the pure nodes in X un der exac t moments. Lemma 3 (Corr ectness of the method und er ex act moments) Assume F ⊙ ˜ F has full column rank, and Π Y has full r ow rank, wher e Y ⊂ R is used for construct ing the pr ojectio n matri x, t hen the pr oposed method LearnMixed Members hip in Algorithm 1 corr ectl y learns the community members hip matrix Π . Pro of: Using the form of the moments in Proposition 1 , we ha ve that if r ∈ ˜ R is a pure node, then G ( r ; { U, T } ) = ( F ⊙ ˜ F ) π r is rank one sinc e it selects only one column of F ⊙ ˜ F . Thus, the rank test in Algorithm 1 succeeds in recov ering the pure nod es. T he correct ness of tenso r metho d foll o ws from (Anand kumar et al. , 2014 a). Since we only ha ve sampled graph b G and not the exact moments, we need to carry out perturbation analys is, w hich is outline d below . 5.2 Pe rturbation Analysis Recall that P c ro j = M k M ⊤ k is the projecti on matrix correspo nding to k -svd ( b G ( { U, T } , Y )) = M k Λ k V ⊤ k . Define the perturb ation between empirical and exa ct moments upon projectio n as m x := k P c ro j b G ( { U, T } , x ) − G ( { U, T } , x ) k , ∀ x ∈ X , ǫ Rank := max x k m x k . (13) The abo ve pertu rbatio n can be divid ed into two parts k m x k ≤ k P c ro j( b G ( { U, T } , x ) − G ( { U, T } , x )) k + k (P c ro j − Pro j ) G ( { U, T } , x ) k . The first term is common ly referred to as distanc e perturbatio n and the second term is the subspac e pertur - bation . W e establis h these pertu rbation bounds belo w . W e begin our pertur bation analysis by bou nding m x as defined in Eqn. (13). Lemma 4 (Distance perturbation) Under the assumptio ns of Section 4.1, with pr obability 1 − δ , we have for all x ∈ X , k P c ro j( b G ( { U, T } , x ) − G ( { U, T } , x )) k ≤ √ k p 1 + C ′ √ k (log( n/δ )) 4 1 / 2 , for some const ant C ′ > 0 . See Appendi x C .1 and Appendix C.2 for detail s. Notice that the subsp ace perturbation dominates. 12 Lemma 5 (Subspace perturbation) W e have the subspa ce pertur batio n as k (P c ro j − Pro j ) G ( { U, T } , x ) k ≤ 2 σ − 1 k (Π Y ) q k F ⊙ ˜ F k 1 . Under the assumpti ons of Section 4.1, w .h.p. this re duces as k (P c ro j − Pro j) G ( { U, T } , x ) k ≤ O √ n p σ k ( E [ π π ⊤ ]) · p − q k + q ! . See Appendi x C .2. 5.3 Analysis of Rank T est Recall tha t from the perturbation analysis, we ha ve bound ǫ Rank on th e error v ecto r m x , defined i n (13). W e assume there exist no node such that max i ∈ [ k ] π x ( i ) is between the threshold giv en in (14) and 1. W e hav e the follo w ing result on the rank test. Lemma 6 (Conditions f or Success of Rank T est) When the thr esholds in A lgorith m 1 ar e chosen 0 < τ 1 < min i k ( F U ) i k · k ( ˜ F T ) i k − ǫ Rank , τ 2 > ǫ Rank , then all the pur e nodes pass the ran k test. Mor eov er , any node x ∈ X passing the ran k test satisfies max i ∈ [ k ] π x ( i ) ≥ τ 1 − τ 2 − 2 ǫ Rank max i k ( F U ) i k · k ( ˜ F T ) i k . (14) Pro of: See Appendix C.3. The abov e result states that we can correctl y detect pure nodes using the rank test. The conditi ons stem from the fact that we require the top eigen-v alue to pass the test and the second top eig en-v alu e to not pass the test. Fo r a pure node, σ 1 (mat(P c ro j G ( { U 1 , T 1 } , x ))) is min i k ( F U 1 ) i k · k ( ˜ F T 1 ) i k . T o account for empirica l err or , we consider ǫ Rank . In addition, the second-to p eige n-v alue can be as small as 0 . W e also note the error in empirical estimati on. T his result allo ws us to control the pertur bation in the 3 -star tensor constr ucted using the node s w hich passe d the rank test. 6 Conclusion In this paper , we propos e a nov el probabilist ic appro ach for modeling folksono mies, and propo se a guaran- teed approach for detecting ov erlapp ing communities in them. W e present a more scalable approac h where realist ic condition al independ ence const raints are imposed. These constr aints are natura l for social tagging systems, and they lead to scalable modeli ng and tractable lea rning. While the ori ginal MMSB model as- sumes that the communitie s are drawn from a Dirichlet distrib ution, her e, we do not require such a strong parametr ic assumption . Note that the Dirichlet assumption for community memberships can be limiting and cannot model general correlatio ns in memberships. Here, w e impose a weak assumption that a certain fractio n of resou rce n odes are “ pure” and belong to a single community . This is reasona ble to ex pect in prac- tice. W e establ ish that the communitie s are identifiable under these natural assumptio ns, and can be learnt ef ficiently using spectr al appro aches. Conside ring future directions, we note that social tagging assumes a specific struc ture. There fore, it is of interest to extend this model to more genera l hyperg raphs . 13 Acknowledgmen t A.Anandkumar is supported in part by Microsoft Faculty F ello wship , NSF Career awar d CC F-125410 6, NSF A ward CCF-1219234 , an d AR O YIP A ward W911NF-13- 1-008 4. H. Sedghi is supported by O NR A ward N 0001 4 − 14 − 1 − 0665 . The author s thank Majid Janz amin fo r deta iled dis cussio n on r ank test analys is. The authors t hank R ong Ge and Y ash Deshpand e for ex tensi ve initial discussio ns during the visit of AA to Microsoft Research New England in Summer 2013 regardin g the pairwise mixed membership models w ithout the Dirichlet assump- tion. The auth ors also ackno wledge detailed discussions with Kamalika Chaudhu ri regard ing analysis of spectr al clustering. A ppendix A Moments under MMSF model and Algorithm Corr ectness Pro of of Proposit ion 1: W e ha ve E [ b G ( { u, t } , r ) | π r , π t , π u ] (a) = E [ E [ b G ( { u, t } , r ) | z r →{ u,t } , π t , π r , π u ]] (b) = E [ E [ b B r → u ; t · b B r → t ; u | z r →{ u,t } , π t , π u ] | π r ] (c) = E [ F u z r →{ u,t } · ˜ F t z r →{ u,t } | π r ] , (15) where ( a ) and ( b ) are from the assumptio n (2) that b G ( { u, t } , r ) = b B r → u ; t · b B r → t ; u , where b B r → u ; t and b B r → t ; u are Bernou lli dra ws, which only depend on the contextu al var iables z r →{ u,t } , z u →{ r,t } and z t →{ u,r } , and therefore b G ( { u, t } , r ) − z r →{ u,t } − π r form a Marko v chain. This also establishes th at b G ( { u, t } , r ) and b G ( { u ′ , t ′ } , r ) are conditi onally in depend ent giv en the community membership vect or π r , for u 6 = u ′ and t 6 = t ′ . For (c), we ha ve that E [ b B r → u ; t | z r →{ u,t } , π u ] = E [ E [ b B r → u ; t | z r →{ u,t } , z u →{ r,t } ] | π u ] = E [ z ⊤ u →{ t,r } P z r →{ u,t } | z r →{ u,t } , π u ] = π ⊤ u P z r →{ u,t } = F u z r →{ u,t } from (1) and the fact tha t E [ z u →{ t,r } | π u ] = π u . 14 Thus, we ha ve E [ b G ( { U, T } , r ) | π r , Π T , Π U ] (a) = E [ F z r →{ u,t } ⊗ ˜ F z r →{ u,t } | π r ] (b) = E [( F ⊗ ˜ F )( z r →{ u,t } ⊗ z r →{ u,t } ) | π r ] (c) = X i ∈ [ k ] π r ( i )( F ⊗ ˜ F )( e i ⊗ e i ) (d) = ( F ⊙ ˜ F ) π r , where (a) follo ws from (15) and (b) follows from the fact (9). (c) follows from the fact that z r →{ u,t } tak es v alue e i with probabi lity π r ( i ) , w here e i ∈ R k is the basis vector in the i th coordi nate. (d) follo ws from the definitio n of Khatri-Rao prod uct. The form of the 3 -star moment is from the lines of (Anandkumar et al., 2014a, P rop 2.1), and relies on the assumpti on that ˜ R consis ts of pure nodes. B Learn ing using T ensor Decomposition W e now recap the tensor decomposit ion ap proac h proposed in (Anandkumar et al., 2014a) here. This is sho wn in Algorith m 3 with modificati ons specific to our frame wo rk. W e parti tion U, T into three sets for the dif fer ent tasks e xplai ned in th e Algor ithm 3. Also no te that with kno wledg e of community connecti vity matrices, we can learn community membership s for m ixed res ource nodes as well. Pro cedur e 3 ( b Π) ← T ensorDecomp ( b G , ˜ R ) Let P ∈ R k × k be the community co nnecti vity matrix from user communities to res ource communities and similarl y ˜ P is connecti vity from tag communities to resource communities. ˜ R are estimated pure resour ce nodes. Partition { U, T } into { U i , T i } for i = 1 , 2 , 3 . Compute whitened and symmetrized tensor T ← ˆ G ˜ R →{ A,B ,C } ( c W A , c W B b S AB , c W C b S AC ) , where A, B , C form a parti tion of { U 2 , T 2 } . Use { U 3 , T 3 } for computing the whiten ing m atrices . { b λ, b Φ } ← T ensorEigen ( T , { c W ⊤ A b G ⊤ i,A } i / ∈ A , N ) . { b Φ is a k × k matrix with each columns being a n estimated eigen ve ctor and b λ is the vector of estimated eigen v alues. } b Π R ← Thres (Diag( b λ ) − 1 b Φ ⊤ c W ⊤ A b G ⊤ R,A , τ ) . r eturn ( b Π) . C Pertur bation Analysis: Pr oof of Theor ems 1, 2 Notation: For a v ector v , let k v k denote its 2 -norm. Let Dia g ( v ) denote a diagonal matrix w ith diag onal entries giv en by a vec tor v . For a m atrix M , let ( M ) i and ( M ) i denote its i th column and ro w respec ti ve ly . Let k M k 1 denote colu mn absolute sum and k M k ∞ denote ro w abs olute sum of M . L et M † denote the MoorePenro se pseud o-in vers e of M . 15 Pro cedur e 4 { λ, Φ } ← T ensorEigen ( T , { v i } i ∈ [ L ] , N ) (Anandkumar et al., 2014a) Input: T ensor T ∈ R k × k × k , L initial izatio n vectors { v i } i ∈ L , number of iterat ions N . Output: the estimated eigen va lue/eig en vector pair s { λ, Φ } , where λ is the vec tor of eigen v alue s and Φ is the matrix of eigen vectors. f or i = 1 to k do f or τ = 1 to L do θ 0 ← v τ . f or t = 1 to N do ˜ T ← T . f or j = 1 to i − 1 (when i > 1 ) do if | λ j h θ ( τ ) t , φ j i| > ξ then ˜ T ← ˜ T − λ j φ ⊗ 3 j . end if end f or Compute po wer itera tion update θ ( τ ) t := ˜ T ( I ,θ ( τ ) t − 1 ,θ ( τ ) t − 1 ) k ˜ T ( I ,θ ( τ ) t − 1 ,θ ( τ ) t − 1 ) k end f or end f or Let τ ∗ := arg max τ ∈ L { ˜ T ( θ ( τ ) N , θ ( τ ) N , θ ( τ ) N ) } . Do N po wer iteration updates starting from θ ( τ ∗ ) N to obtain eigen vect or estimate φ i , and set λ i := ˜ T ( φ i , φ i , φ i ) . end f or r eturn the estimated eigen valu e/eigen vectors ( λ, Φ) . C.1 Distance Concentration: Proof of L emma 4 The proof is alon g the lines of (McShe rry, 2001, Theore m 13 ) but we ap ply Han son-Wrig ht bou nd in Propo- sition 5 to get a better perturb ation guarantee without the need for constructing the so-call ed combinatorial projec tion, as in (McSherry, 2001). W e hav e h x := b G ( x ; { U, T } ) − G ( x ; { U, T } ) and let σ 2 = max i E [ h x ( i ) 2 | π x ] . Note the simple fact k P c ro j h x k 2 = h ⊤ x P c ro j 2 h x = h ⊤ x P c ro j h x , since P c ro j is a projec tion m atrix. From Proposition 1, we ha v e that the entries of h x are conditional ly indepe ndent giv en π x . Thus, the Hans on-Wrigh t inequal ity in Proposition 5 is a pplica ble, and we ha v e with probab ility 1 − δ , for all x ∈ X , h ⊤ x P c ro j h x ≤ E [ h ⊤ x P c ro j h x | π x ] + C ′ σ 2 k P c ro j k F (log( n/δ )) 4 (16) No w k P c ro j k F ≤ √ k k P c ro j k = √ k . The expecta tion is E [ h ⊤ x P c ro j h x | π x ] ≤ tr(P c ro j) σ 2 = k σ 2 , using the propert y that P c ro j is idempoten t. Thus, we ha v e from (16), with probabili ty 1 − δ , for all x ∈ X , h ⊤ x P c ro j h x ≤ k σ 2 + C ′ √ k σ 2 (log( n/δ )) 4 , 16 and we see that the mean term domina tes and the bound is ˜ O ( k σ 2 ) . Draw ra ndom vari ables b B r → u ; t ∼ Berno ulli ( z ⊤ u →{ t,r } P z r →{ u,t } ) b B r → t ; u ∼ Berno ulli ( z ⊤ t →{ u,r } ˜ P z r →{ u,t } ) . The presen ce of hype r -edge G ( { u, t } , r ) is giv en by the produ ct b G ( { u, t } , r ) = b B r → u ; t · b B r → t ; u . The v arianc e is on lines of proo f of Lemma 10 and we repe at it here. max i E [ h x ( i ) 2 | π x ] = max u ∈ U,v ∈ V E [ ˆ B x → u ; t ˆ B x → t ; u − (( F ⊙ ˜ F ) π x ) ut ] 2 ≤ max u ∈ U,v ∈ V (( F ⊙ ˜ F ) π x ) ut , ≤ max u ∈ U,v ∈ V X j ∈ [ k ] F ( u, j ) ˜ F ( t, j ) π x ( j ) ≤ max i ∈ [ k ] X j ∈ [ k ] P ( i, j ) ˜ P ( i, j ) π x ( j ) ≤ P 2 max C.2 Pr oof of Lemma 5 From Dav is-Kahan in Propositio n 6, we ha v e k (P c ro j − I ) G ( { U, T } , Y ) k ≤ 2 k b G ( { U, T } , Y ) − G ( { U, T } , Y ) k . and thus k (P c ro j − I ) G ( { U, T } , x ) k ≤ 2 k b G ( { U, T } , Y ) − G ( { U, T } , Y ) k · k G ( { U, T } , Y ) † · G ( { U, T } , x ) k No w , G ( { U, T } , Y ) † = ( F ⊙ ˜ F )Π Y † = Π † Y ( F ⊙ ˜ F ) † , since the assump tion is that F ⊙ ˜ F has full column rank and Π Y has full ro w rank. Thus, we ha ve G ( { U, T } , Y ) † · G ( { U, T } , x ) = Π † Y ( F ⊙ ˜ F ) † ( F ⊙ ˜ F ) π x = Π † Y · π x , since ( F ⊙ ˜ F ) † ( F ⊙ ˜ F ) = I due to full column rank, when | U | and | T | are sufficie ntly large, du e to concen tratio n result from Lemm a 11. Note that under assumptio n A3, the v arianc e terms in Lemma 11 are decayi ng and we ha ve that F ⊙ ˜ F has full column rank w .h.p. From Lemma 10, we ha v e the result. C.3 Analysis of Rank T est: Lemma 6 Consider the test under ex pected moments G := E [ b G | Π] . For eve ry no de x ∈ X ( R is rand omly partitio ned into X, Y ), which passes the rank test in Algorith m 1, by definiti on, k m at( ˆ G ( { U, T } , x )) k > τ 1 , an d σ 2 (mat( ˆ G ( { U, T } , x ))) < τ 2 . 17 W e use the follo wing approxi mation. k F i k ≃ q ( p − q ) 2 k Π i k 2 + n q 2 + 2( p − q ) q k Π i k 1 Recall the form of G from Propositio n 1 mat( G ( { U, T } , x )) = F U Diag( π x ) ˜ F ⊤ T . First we consi der the case, p ≃ q . Follo wing lines of Anandkumar et al. (2014b), we ha ve that | σ 1 − π max n ( p − q k + q ) 2 | ≤ k E k + ǫ Rank where k E k ≤ √ k π 2 , max n ( p − q k + q ) 2 k E [ π π ⊤ ] k q 2 p − q k + q 3 ( p q E [ π π ⊤ ] + k E [ π π ⊤ ] k q 2 p − q k + q ) . Hence, we ha v e that σ 2 ≥ π 2 , max n ( p − q k + q ) 2 − k E k − ǫ Rank − (1 / ˜ µ ) ǫ Rank − π 3 , max np 2 k E [ π π ⊤ ] k , where we assume π max ≥ (1 + µ ) π 2 , max and ˜ µ := 1+ µ − µ R − µ E 1+ µ , µ R := k F k k F i k , µ E := k E k π 2 , max n ( p − q k + q ) 2 . W e note that ǫ Rank dominate s k E k and the last term. Therefore, τ 2 − ǫ Rank ≥ σ 2 (mat( G ( { U, T } , x ))) ≥ π 2 , max n ( p − q k + q ) 2 − (1 + 1 / ˜ µ ) ǫ Rank , and τ 1 + ǫ Rank ≤ k F U Diag( π x ) ˜ F ⊤ T k ≤ π max max i k ( F U 1 ) i k · k ( ˜ F T ) i k + π 2 , max n ( p − q k + q ) 2 ≤ π max max i k ( F U ) i k · k ( ˜ F T ) i k + τ 2 + 1 / ˜ µ ǫ Rank . Combining we ha ve that an y vect or which passes the rank test satisfies π max ≥ τ 1 − τ 2 + (1 − 1 / ˜ µ ) ǫ Rank max i k ( F U ) i k · k ( ˜ F T ) i k . No w , for the case where q < p/k , th e bound on k E k is almost 0, µ R ≃ 1 and µ E = 0 . Hence E qn. (C. 3) alw ays hold s. This is intuiti ve as the role of q is to make the components non-ortho gonal , i.e., q acts as noise. Therefore, smaller q results in better guarantees. W ith | U | = | T | = Θ ( n ) , and using the concentra tion bou nds in Lemma 11, we hav e that with pr obabi lity 1 − δ , k ( F U ) i k · k ( ˜ F T ) i k = O p | U | · | T |k E [ π π ⊤ ] k · ( p − q + √ k q ) assuming home genou s setting. 18 For ǫ Rank , the subspac e perturba tion dominates . From Lemma 11, we ha v e k F ⊙ ˜ F k 1 = O n 2 p − q k + q 2 ! . Thus, we ha ve the sub space perturbati on from Lemma 5 as ǫ Rank = O √ n p σ k ( E [ π π ⊤ ]) · p − q k + q ! . Substitu ting for the condition that τ 1 = Ω( ǫ Rank ) , we obtain assumpt ion (5). Thus, the ran k tes t succee ds in this settin g. C.4 Pe rturbation Analysis f or the T ensor Method This is along the lines of analysis in (Anandkumar et al., 2014a). Ho we ve r , notice here due to hyper graph setting , we need to redo the indi vidua l perturbatio ns. R ecall that w i := P [ i = arg max j π ( j ) | π is pure ] and ρ = P [ π is pure ] . T he size of reco ver ed set of pure nodes ˜ R = Θ( nρ ) , assuming n ρ > 1 . W e provide the perturbatio n of the whitened tensor . Let Φ := W ⊤ A H A Diag( η ) 1 / 2 be the eigen vec tors of the whitened tensor under e xact moments and λ := Di ag ( η ) − 1 / 2 be the eigen v alues . S, b S respecti vely denote the exa ct and empirical symmetrizatio n matrix for dif feren t cases based on their subscri pt. Lemma 7 (Per turbation of whitened tensor) W e have w .h.p. ǫ T := b T ˜ R →{ A,B ,C } ( ˆ W A , ˆ W B b S AB , ˆ W C b S AC ) − X i ∈ [ k ] λ i Φ ⊗ 3 = O p √ nρw min · ( p − q ) 2 · σ k ( E [ π π ⊤ ]) (17) Pro of: Let T := E [ b T | Π A,B ,C ] . ǫ 1 := b T ( ˆ W A , ˆ W B b S AB , ˆ W C b S AC ) − T ( ˆ W A , ˆ W B b S AB , ˆ W C b S AC ) ǫ 2 := T ( ˆ W A , ˆ W B b S AB , ˆ W C b S AC ) − T ( W A , W B S AB , W C S AC ) For ǫ 1 , the dominan t term in the pertu rbation bound is O 1 | ˜ R | k ˜ W ⊤ B H B k 2 X i ∈ Y c W ⊤ A ( b G A,i − H A π i ) ! = O 1 w min 1 | ˜ R | X i ∈ Y c W ⊤ A ( b G A,i − H A π i ) ! The secon d term is ǫ 2 ≤ ǫ W √ w min , 19 since due to whitenin g property . No w imposin g the requirement that ǫ i < Θ λ min r 2 , from Theorem 11 (Anandkumar et al. , 2014a), λ min = 1 / √ w max , and we hav e r = Θ(1) by initializat ion using whitened neigh borhoo d vecto rs (from lemma 25 (Anandkumar et al., 2014a)). ǫ 1 is not the dominant error , on lines of (Anand kumar et al., 2014a). N o w for ǫ 2 , we require ǫ W ≤ r w min w max ≤ 1 , and using Lemma 8, we ha ve ( p − q ) 2 p ≥ √ w max w min · 1 √ nρ · σ k ( E [ π π ⊤ ]) . Lemma 8 (Whitening Per turbation) W e have the perturba tion of the whitenin g matrix ˆ W A as w .h.p. ǫ W := k Diag ( ~ w ) 1 / 2 H ⊤ A ( ˆ W A − W A ) k = O p √ nρw min · ( p − q ) 2 · σ k ( E [ π π ⊤ ]) . Pro of: F rom (Anandku mar et al., 2014a, Lemma 17), the whitening p erturb ation und er the tens or method is gi v en by ǫ W := k Diag ( w ) 1 / 2 H ⊤ A ( ˆ W A − W A ) k = O ǫ G σ min ( G ˜ R,A ) ! . Using the bounds from Section C.5, we ha ve ǫ G := k b G ( { U, T } , ˜ R ) − G ( { U, T } , ˜ R ) k = O ( q k F ⊙ ˜ F k 1 ) = O n p − q k + q , and σ min ( G ˜ R,A ) = Ω q | ˜ R | w min · σ min ( H A ) = Ω ( √ n · ρw min · σ min ( H A )) . From Lemma 12, we ha v e σ min ( H A ) = σ min ( F A ⊙ ˜ F A ) = Ω n ( p − q ) 2 min i,j 6 = i E [ π 2 i ] − E [ π i π j ] . Finally note that σ k ( E [ π π ⊤ ]) = Θ min i,j 6 = i E [ π 2 i ] − E [ π i π j ] . Substitutin g we ha ve the resul t. Let ˜ Π Z be the reco nstruc tion after the tensor method (bef ore thresho lding) on resource subs et Z ⊂ R − ˜ R (we do not incorpo rate ˜ R to av oid depend enc y issues), i.e. ˜ Π Z := Diag( λ ) − 1 Φ ⊤ ˆ W ⊤ A G ⊤ Z,A . Lemma 9 (Reconstructio n of communities (bef or e thre sholding)) W e have w .h.p. ǫ π := max i ∈ Z k ( ˜ Π Z ) i − (Π Z ) i k = ǫ T √ k k Π Z k = O ǫ T √ k · √ n k E [ π π ⊤ ] k . (18) Pro of: This is on lines of (Anandku mar et al., 2014a, Lemma 13). 20 C.5 Concentration of Graph Moments Lemma 10 (Concentrati on of hyper -edges) W ith pr obabilit y 1 − δ , given communit y members hip vector s Π , ǫ G := k b G ( { U, T } , Y ) − G ( { U, T } , Y ) k = O (max( q k F ⊙ ˜ F k 1 , q k ( P ∗ ˜ P )Π Y k ∞ )) Remark: When number of nodes n is lar ge enoug h, the first term, viz., q k F ⊙ ˜ F k 1 dominate s. Pro of: The proof is on the lin es of (Anandkumar et al., 2013, Lemma 22) but adapted to the se tting of hyper -adjacenc y rather than adjacenc y matri ces. Let m y := b G ( { U, T } , y ) − G ( { U, T } , y ) and M y := m y e ⊤ y and thus b G ( { U, T } , Y ) − G ( { U, T } , Y ) = X y M y , Note that th e rand om m atrices M y are conditiona lly independ ent for y ∈ Y sinc e m y are conditiona lly inde- pende nt giv en π y , and in each vecto r m y , the entrie s are indepen dent as well. W e apply m atrix B ernstei n’ s inequa lity . W e ha ve E [ M y | Π] = 0 . W e compute the v arianc es P y ∈ Y E [ M y M ⊤ y | Π] and P y E [ M ⊤ y M y | Π] . W e hav e that P y E [ M y M ⊤ y | Π] only the diagon al terms are non-zero due to independen ce, and E [ M y M ⊤ y | Π] ≤ Diag(( F ⊙ ˜ F ) π y ) (19) entry- wise, assuming B ernoul li random v ariab les. Thus, k X y ∈ Y E [ M y M ⊤ y | Π] k ≤ max u ∈ U,t ∈ T X y ∈ Y , j ∈ [ k ] F ( u, j ) ˜ F ( t, j ) π y ( j ) = max u ∈ U,t ∈ T X y ∈ Y , j ∈ [ k ] F ( u, j ) ˜ F ( t, j )Π Y ( j, y ) ≤ · max i ∈ [ k ] X y ∈ Y , j ∈ [ k ] P ( i, j ) ˜ P ( i, j )Π Y ( j, y ) = k ( P ∗ ˜ P )Π Y k ∞ , (20) where ∗ indicates Hadamard or entry-wise prod uct. Similarly P y ∈ Y E [ M ⊤ y M y ] = P y ∈ Y Diag( E [ m ⊤ y m y ]) ≤ k ( P ∗ ˜ P )Π Y k ∞ . From Lemma 11, we ha ve a bound k ( P ∗ ˜ P )Π Y k ∞ . W e now bou nd k M y k = k m y k through vec tor Bernstein ’ s inequali ty . W e hav e for Bernoull i b G , max u ∈ U,t ∈ T | b G ( { u, t } , y ) − G ( { u, t } , y ) | ≤ 2 and X u ∈ U,t ∈ T E [ b G ( { u, t } , y ) − G ( { u, t } , y )] 2 ≤ X u ∈ U,t ∈ T (( F ⊙ ˜ F ) π y ) ut ≤ k F ⊙ ˜ F k 1 . Thus with probab ility 1 − δ , we ha v e k M y k ≤ (1 + p 8 log (1 /δ ) ) q k F ⊙ ˜ F k 1 · + 8 / 3 log (1 /δ ) . Thus, we ha ve the bou nd that k P y M y k = O (max( q k F ⊙ ˜ F k 1 , q k ( P ∗ ˜ P )Π Y k ∞ )) . 21 For a gi ven δ ∈ (0 , 1) , w e assume that the sets U, T and Y ⊂ R are large enou gh to satis fy p | U | · | T | ≥ 8 3 log | U | · | T | δ p | Y | ≥ 8 3 log | Y | δ . Lemma 11 (Concentrati on bounds) W ith pr obability 1 − δ , k F ⊙ ˜ F k 1 ≤ | U | · | T | max i ( P · E [ π ]) i max i ( ˜ P · E [ π ]) i + r 8 3 | U | · | T | · P 4 max · log | U | · | T | δ , |k ( F ⊙ ˜ F ) i k ≤ max i k Π U k · k Π T k · k P i k · k ˜ P i k = O p | U | · | T |k E [ π π ⊤ ] k · ( p − q + √ k q ) , for the homog eneo us setting. Similarly for subset Y ⊂ R , we have k Π Y Π ⊤ Y k ≤ | Y | · k E [ π π ⊤ ] k + r 8 3 | Y | · k E [ π π ⊤ ] k 2 · log | Y | δ σ k (Π Y Π ⊤ Y ) ≥ | Y | · σ k ( E [ π π ⊤ ]) − r 8 3 | Y | · k E [ π π ⊤ ] k 2 · log | Y | δ k ( P ∗ ˜ P ) ⊤ Π Y k ∞ ≤ | Y | max i ( E [ π ] ⊤ · ( P ∗ ˜ P )) i + r 8 3 | Y | · P 4 max · log | Y | δ Remark: Note t hat σ ( P ) = Θ( p − q ) and k P k = Θ( p + q ) for homog eneous P . Under Assu mption A3, the v arianc e terms are small and the abo ve qua ntities are close to their expectati on. Pro of: T o bound on k F ⊙ ˜ F k 1 , we note that k E [ F ⊙ ˜ F ] k 1 ≤ | U | · | T | m ax i ( P ⊤ · E [ π ]) i ( ˜ P ⊤ · E [ π ]) i . Using Bernstein ’ s inequali ty , for each column of F ⊙ ˜ F , we ha v e, with probability 1 − δ , k ( F ⊙ ˜ F ) i k 1 − | U | · | T |h E [ π ] , ( P ) i ih E [ π ] , ( ˜ P ) i i ≤ r 8 3 | U | · | T | · P 4 max · log | U | · | T | δ , by applyin g Bernstein ’ s inequality , since h π , ( P ) i ih π , ( ˜ P ) i i ≤ m ax i ( P ⊤ π ) i ( ˜ P ⊤ π ) i ≤ P 2 max , and max X u ∈ U,t ∈ T k E [( P ) ⊤ i π u π ⊤ u ( P ) i ] · E [( ˜ P ) ⊤ i π t π ⊤ t ( ˜ P ) i ] k , X u ∈ U,t ∈ T k E [ π ⊤ u ( P ) i ( P ) ⊤ i π u ] · E [ π ⊤ t ( ˜ P ) i ( ˜ P ) ⊤ i π t ] k ≤ | U | · | T | · P 4 max . The other results follo w similarly . The lowest singul ar val ue for the Khatri-Rao product is a bit more in v olv ed and we pro vide the bound belo w . Lemma 12 (Spectral Bound f or KR-pro duct) σ 2 k ( F ⊙ ˜ F ) ≥ | U | · | T | σ k (Γ ∗ Γ) − r 8 3 | U | · | T | · k P k 2 · k ˜ P k 2 · k E [ π π ⊤ ] k 2 · log | U | · | T | δ , wher e Γ := P ⊤ E [ π π ⊤ ] ˜ P and ∗ denotes H adamar d pr odu ct. 22 Pro of: The res ult in the Lemma fol lo ws directly from the con centra tion result. For the homogeneou s setting , we ha ve for a matrix Γ , σ k (Γ ∗ Γ) = Θ min i Γ( i, i ) 2 − m ax i 6 = j Γ( i, j ) 2 . Substitu ting w e ha ve the resu lt. Remark: For the homoge neous setting, with P = ˜ P having p on the diagonal and q on the off-d iagon al, we ha ve Γ = h ( p − q ) I + q 11 ⊤ i E [ π π ⊤ ] h ( p − q ) I + q 11 ⊤ i = ( p − q ) 2 E [ π π ⊤ ] + 2( p − q ) q v 1 ⊤ + q 2 k E [ π π ⊤ ] k sum 11 ⊤ , where v is a vecto r where v i = k E [ π π ⊤ ] ( i ) k 1 , where M ( i ) denote s the i th ro w of M . Thus, we hav e the follo w ing bound σ k (Γ ∗ Γ) = min i,j 6 = i Γ( i, i ) 2 − Γ( i, j ) 2 = Θ ( p − q ) 4 min i,j 6 = i E ( π 2 i ) − E [ π i π j ] 2 , assuming that E [ π 2 i ] − E [ π i π j ] = Θ( E [ π 2 i ]) for a ll i 6 = j , and the other terms which are drop ped are positi ve. Thus, we ha ve w .h.p. σ k ( F ⊙ ˜ F ) = Ω n ( p − q ) 2 min i,j 6 = i E [ π 2 i ] − E [ π i π j ] (21) D Standard Matrix Concentration and Pertu rbation Bounds D.1 Bern stein’ s Inequalities One of the ke y tools we use is the standar d m atrix Bernstei n inequal ity (Tropp, 201 2, thm. 6.1, 6.2). Pro position 2 (Matrix Bernstein Inequality) Suppose Z = P j W j wher e 1. W j ar e indepe ndent ran dom matrices with dimension d 1 × d 2 , 2. E [ W j ] = 0 for all j , 3. k W j ≤ R almost sur ely . Let d = d 1 + d 2 , and σ 2 = max n k P j E [ W j W ⊤ j ] , k P j E [ W ⊤ j W j ] o , then we have Pr[ k Z ≥ t ] ≤ d · exp − t 2 / 2 σ 2 + R t/ 3 ≤ d · exp − 3 t 2 8 σ 2 , t ≤ σ 2 /R, ≤ d · exp − 3 t 8 R , t ≥ σ 2 /R 23 Pro position 3 (V ector Bernste in Inequality) Let z = ( z 1 , z 2 , ..., z n ) ∈ R n be a rando m vector with in- depen dent entries, E [ z i ] = 0 , E [ z 2 i ] = σ 2 i , and Pr[ | z i | ≤ 1] = 1 . L et A = [ a 1 | a 2 | · · · | a n ] ∈ R m × n be a matrix, then Pr[ k Az ≤ (1 + √ 8 t ) v u u t n X i =1 k a i 2 σ 2 i + (4 / 3) max i ∈ [ n ] k a i t ] ≥ 1 − e − t . D.2 Hanson-Wright Inequalities W e require the Hanson-Wright inequality (Rudelson and V ershyn in, 2013). Pro position 4 (Hanson-Wright Inequality: sub -Gaussian bound) Let z = ( z 1 , z 2 , ..., z n ) ∈ R n be a ran dom vector w ith indepe ndent entries, E [ z i ] = 0 and Pr[ | z i | ≤ 1] = 1 and let M ∈ R n × n be any matrix. Ther e exists a constant c > 0 s.t. Pr h | z ⊤ M z − E ( z ⊤ M z ) | > t i ≤ 2 exp − c min t 2 k M k 2 F , t k M k Unfortun ately the sub-Gaussia n bound is not strong enough when z has small varian ce σ 2 . In this case, we get th e pert urbati on as ˜ O ( k M k F ) instead of ˜ O ( σ k M k F ) , whi ch is desir ed. T his is b ecause for a bounded random v ariab le, the sub-Gaussian paramete r only depends on the bou nd and not on the varian ce. W e will co nsider an extensio n of the Hanso n-Wrigh t i nequal ity to sub-e xpon ential random v ariabl es (Erd ˝ os et al., 2012; V u and W ang, 2013) and emplo y the sub-expo nentia l formulat ion for bound ed rando m v ariable s. W e first define sub-e xpo nentia l random var iable (V ershynin, 2010, Definition 5.13). Definition 1 (Sub-exponential Random V ariable) A zer o-mea n ran dom varia ble X is said to be sub- e xpone ntial if ther e ex ists a paramet er K suc h that E [ e X/K ] ≤ e . Remark: There are other equiv alent notio ns for sub-e xpon ential random varia bles (V ershyni n , 2010, Def- inition 5.13), b ut thi s will be the con venien t one for provin g sub- exp onenti al bound for Bernoulli random v ariabl es. It is easy to se e that the ce ntered Bernou lli random v ariabl es are sub-e xpon ential for some constant K . W e will employ the followin g ver sion of Hanson-Wrig ht’ s inequal ity for sub-e xpon ential random va ri- ables (Erd ˝ os et al., 201 2, Lemma B. 2). Pro position 5 (Hanson-Wright Inequality: sub -exponential bound) Let z = ( z 1 , z 2 , ..., z n ) ∈ R n be a random vec tor w ith independen t entries, E [ z i ] = 0 , E [ z 2 i ] ≤ σ 2 and z i ar e sub-e xponential and let M ∈ R n × n be any matrix. Ther e e xists const ants c, C > 0 s.t. Pr h | z ⊤ M z − E ( z ⊤ M z ) | > tσ 2 k M k F i ≤ C exp h − ct 1 / 4 i . Remark: The resu lt in th e form ab ov e ap pears in (V u and W ang, 2013, (13)) and we set α = 1 in (V u and W ang, 2013, (13)). T he parameter C abov e differs from the sub -ex ponent ial paramete r K by only a const ant fa ctor . Comparing sub-ex ponent ial formulation in P roposit ion 5 with sub-Gaussi an formulation in Propo si- tion 4, we see that in the former , the deviat ion is ˜ O ( k M k F σ ) , while in the latter it is only ˜ O ( k M k F ) . Thus, for centered Bernoulli random varia bles and we can emplo y Propositi on 5 , and we will use it for distan ce concen tration bounds. 24 D.3 Davis-Kahan In equality W e also use the standard Davis and Kahan bou nd for subspace perturbatio n. Pro position 6 (Davi s and Kahan) F or a matrix ˆ A , let P c ro j be the pr ojection matrix on to its top- k left singul ar vector s. F or any rank- k matrix A , w e have k (P c ro j − I ) A k ≤ 2 k ˆ A − A k Pro of: This is directly from (McSherry, 2001, Lemma 12). By writing A = ˆ A − ( ˆ A − A ) , w e ha ve k (P c ro j − I ) A k ≤ k (P c ro j − I ) ˆ A k + k (P c ro j − I )( ˆ A − A ) k , and each of the terms is less than k ˆ A − A k . For the first term, it is because P c ro j ˆ A is the best rank- k approx imation of ˆ A an d since A is also rank k , the resi dual k (P c ro j − I ) ˆ A k ≤ k ˆ A − A k . F or the seco nd term, k (P c ro j − I )( ˆ A − A ) k ≤ k ˆ A − A k since (P c ro j − I ) cannot increase norm. Refer ences Edoardo M. Airoldi, David M. Blei, S tephen E. Fienber g, an d Eric P . X ing. Mixe d membership stochastic blockmo dels. Jour nal of Machine Learnin g R esear ch , 9:1981 –2014 , June 2008. A. Anandkumar , R . Ge, D. H su, and S . M. Kakade. A T ensor Spectral A pproac h to Learning M ixe d M em- bershi p C ommunity Models . In Confer enc e on Learnin g T heory (COLT) , J une 2013. Animashree Anandku mar , R ong Ge, D aniel Hsu, and Sha m M Kakade. A tensor approach t o learning mixed membership community models. The Jour nal of Machine Learnin g R esear ch , 15(1):2 239–2 312, 2014a. Animashree Anandku mar , Rong Ge, and Majid Janzamin. Guaranteed non-or thogo nal tensor decomposi tion via alterna ting rank-1 updates. arXiv pr eprin t arXiv:140 2.5180 , 2014b . Michael B rinkmeier , Jeremias W erner , and Sven Recknagel. Communit ies in graphs and hyper graphs . In Pr oceedings of the sixte enth A C M confe r enc e on Confer ence on informatio n and knowledg e m ana gemen t , pages 869–87 2. ACM, 2 007. Abhijnan C hakrab orty and Saptarshi Ghosh. Clustering hyper grap hs for discov ery of ov erlapp ing commu- nities in folksonomies . In Dynamics On and Of Complex Networks, V olume 2 , pages 201–220. Springer , 2013. Abhijnan Chakrabo rty , Saptarshi Ghosh, and N iloy Ganguly . Detecting ov erlapp ing co mmunities in folk- sonomie s. In Pr oceedings of the 23r d ACM confer enc e on H yperte xt an d social media , pages 213–218. A C M, 2012. L ´ aszl ´ o Erd ˝ os, Horng-Tze r Y au, and Jun Y in. Bulk u ni ve rsality for gene ralized wigner matri ces. Pr obability Theory and Related F ield s , 154(1 -2):34 1–407, 2012. F . Huang, U.N. Niranjan , M. Hakeem, and A . Anandku mar . Fast D etectio n of Ov erlapp ing Communit ies via Online T ensor Method s. ArXiv 1309.07 87 , Sept. 2013. 25 Stefan ie Jeg elka, Suvrit Sra, and Arind am Banerje e. Approxi mation algorith ms for tens or clustering . In Algorith mic learning theory , pages 368 –383. S pringe r , 2009. Ioanni s K onstas , V assilio s S tathopo ulos, and Joemon M Jose. On social networks and collaborati ve recom- mendatio n. In Pr oceedings of the 32nd interna tional A CM SIGIR confer ence on R esear ch and develop - ment in informat ion retr ieva l , pages 195–202. ACM, 2 009. Y u-Ru Lin, Ji meng Sun, Paul Castro, R a vi Ko nuru, Hari Sundaram, and A isling Kelliher . M etaf ac: com- munity discov ery via relation al hyper gra ph factor ization . In Pr oceeding s of the 15th A CM SIGKDD intern ationa l confer ence on Knowledge disco very and data mining , pages 527–5 36. ACM, 2 009. F . McSherry . Spectr al partitio ning of random graphs. In FOCS , 2001 . Tsuyosh i Murata. Detec ting co mmunities from t riparti te network s. In Pr oceed ings of th e 19 th inter nation al confer ence on W orld wide web , pages 115 9–116 0. ACM, 2 010. Nicolas N eubau er an d Kla us Obermayer . T ow ards community detection in k-parti te k-un iform hype r graph s. In Pr oceedings o f the NIPS 2009 W orkshop on Analyzing Networks and Lea rning with Graph s , p ages 1–9, 2009. Symeon Papadop oulos , Y ianni s K ompats iaris, an d Athena V akali. A graph- based clustering scheme for identi fying related tags in folkso nomies. In Data W ar ehousing and Knowledg e Discovery , pages 65–76. Springer , 2010. Mark Rudelson and R oman V ershyn in. Hanson-wright inequ ality and su b-gau ssian concentra tion. arXiv pr eprint arXiv:1306.287 2 , 2013 . J.A. Tropp . User -frie ndly tail bounds for sums of random matrices. F oundatio ns of Computationa l Mathe- matics , 12(4):3 89–43 4, 2012. Alex ei V azquez. Finding hyper grap h communities: a bayesian approac h and v ariatio nal solution. Jour nal of Stati stical Mecha nics: Theory and Experiment , 2009(07):P07 006, 2009. Roman V ershyni n. Introdu ction to the non-asympto tic analysis of random matrices . arXiv pr eprint arXiv:10 11.3027 , 2010. V an V u and Ke W ang. R andom weighted proje ctions , random qu adratic fo rms and random eig en vecto rs. arXiv pr eprint arXiv:1306.309 9 , 2013 . Xufei W ang, L ei T ang, H uiji Gao, and Huan L iu. Disco veri ng overla pping group s in social media. In Data Mining (ICDM), 2010 IEEE 10th Intern ationa l Confer ence on , pages 569–578. IE EE, 2010 . Shenglia ng Xu, Shengh ua Bao, Ben Fei, Z hong Su, and Y ong Y u. E xplorin g folksono my for personal- ized search. In P r oceedings of the 31st ann ual internat ional ACM SIGIR con fer ence on R esear ch and dev elopment in informatio n r etri eva l , pages 155–16 2. ACM, 2 008. Jae won Y ang and Jure Lesk ov ec. Over lappin g community detection at scale: A nonne gati ve matrix fac- torizat ion approach. In Pr ocee dings of the sixth ACM internatio nal co nfer ence on W eb sear ch and data mining , pages 587–59 6. ACM, 2 013. Chen Y udong, Sujay S angha vi, and Huan Xu. Clustering sparse graph s. In Advances in Neur al In formatio n Pr ocessing Systems 25 , 2012. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment