Learning Activation Functions to Improve Deep Neural Networks
Artificial neural networks typically have a fixed, non-linear activation function at each neuron. We have designed a novel form of piecewise linear activation function that is learned independently for each neuron using gradient descent. With this adaptive activation function, we are able to improve upon deep neural network architectures composed of static rectified linear units, achieving state-of-the-art performance on CIFAR-10 (7.51%), CIFAR-100 (30.83%), and a benchmark from high-energy physics involving Higgs boson decay modes.
💡 Research Summary
The paper introduces Adaptive Piecewise‑Linear (APL) activation units, a novel class of learnable activation functions that are trained jointly with the network weights. Each APL unit computes
h_i(x) = max(0, x) + Σ_{s=1}^S a_{s,i}·max(0, −x + b_{s,i}),
where S is a hyper‑parameter controlling the number of “hinges”, and the parameters a_{s,i} (slopes) and b_{s,i} (hinge locations) are learned by standard gradient descent. This formulation yields a piecewise‑linear function that behaves like the identity for large positive inputs and like a linear function with slope α for large negative inputs, while allowing arbitrary curvature in between.
The authors prove (Theorem 1) that any continuous piecewise‑linear function satisfying mild asymptotic linearity conditions can be expressed exactly by an APL unit with a suitable choice of S, a_s, and b_s. Consequently, a single neuron equipped with an APL can approximate any continuous function on a bounded interval, provided enough hinges are used.
A key contribution is the comparison with two popular alternatives: Maxout and Network‑in‑Network (NIN). Maxout computes the maximum over K linear functions, which can emulate an APL only at the cost of O(SK) additional parameters because each hinge would require its own set of weights. NIN replaces each convolutional ReLU with a small multilayer perceptron, again inflating the parameter count dramatically. In contrast, APL adds only 2 S M extra parameters (M = total hidden units), making it feasible to assign a distinct activation to every neuron, even in large convolutional maps.
Experiments were conducted on three benchmarks: CIFAR‑10, CIFAR‑100, and a high‑energy physics dataset (Higgs → ττ decay). For CIFAR‑10 the authors used a three‑layer convolutional network (96, 128, 256 filters) followed by three pooling layers and two 2048‑unit fully‑connected layers. Setting S = 5 yielded an error rate of 11.38 % versus 12.61 % for a ReLU baseline—a relative reduction of ~9 %. When the same APL units were incorporated into a Network‑in‑Network architecture, the error dropped further to 7.51 %, surpassing the previous state‑of‑the‑art. On CIFAR‑100, with S = 2, APL achieved 30.83 % error, again beating the best published results.
The Higgs dataset contains 80 M simulated collision events with 25 real‑valued features. Using the same 8‑layer DNN architecture as Baldi et al. (2015) and S = 2, the APL‑augmented network attained an AUC of 0.804 and a discovery significance of 3.41 σ, modestly improving over both the single‑model ReLU baseline (0.803, 3.38 σ) and the 5‑model ensemble (0.803, 3.39 σ).
Ablation studies examined the effect of the hinge count S and the necessity of learning the activation. With S = 1 and frozen random parameters, performance matched the ReLU baseline (≈12.55 % error). Allowing the parameters to be learned reduced error to 11.59 %. Varying S showed the best CIFAR‑10 result at S = 5; larger S values did not yield further gains and sometimes increased variance, indicating a trade‑off between flexibility and over‑parameterization.
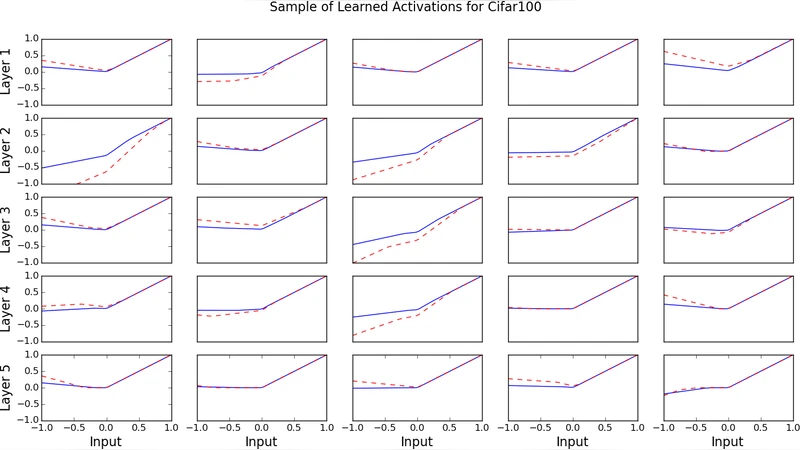
Visualization of learned APL functions revealed shapes resembling leaky ReLUs but with diverse negative‑slope regions, confirming that the network exploits the extra degrees of freedom to adapt non‑linearity to the data distribution.
In summary, Adaptive Piecewise‑Linear units provide a parameter‑efficient, easily implementable way to endow each neuron with a data‑driven, expressive activation function. They improve training dynamics and final accuracy across image classification and scientific data analysis tasks, establishing a compelling alternative to fixed activations, Maxout, and Network‑in‑Network designs.
Comments & Academic Discussion
Loading comments...
Leave a Comment