Inducing Semantic Representation from Text by Jointly Predicting and Factorizing Relations
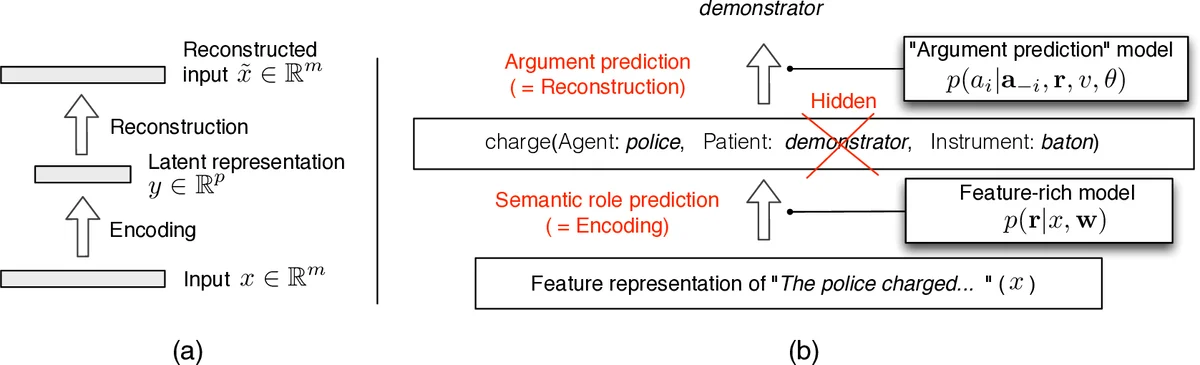
In this work, we propose a new method to integrate two recent lines of work: unsupervised induction of shallow semantics (e.g., semantic roles) and factorization of relations in text and knowledge bases. Our model consists of two components: (1) an encoding component: a semantic role labeling model which predicts roles given a rich set of syntactic and lexical features; (2) a reconstruction component: a tensor factorization model which relies on roles to predict argument fillers. When the components are estimated jointly to minimize errors in argument reconstruction, the induced roles largely correspond to roles defined in annotated resources. Our method performs on par with most accurate role induction methods on English, even though, unlike these previous approaches, we do not incorporate any prior linguistic knowledge about the language.
💡 Research Summary
The paper introduces a novel framework that jointly learns a feature‑rich semantic role labeler (the encoder) and a tensor‑factorization based argument reconstruction model (the decoder) from raw text without any language‑specific prior knowledge. The encoder is a log‑linear model that predicts a distribution over latent role assignments r for each predicate, using a large set of syntactic and lexical features (approximately 49 k feature instantiations). The decoder predicts each argument a_i given the predicate v, the role r_i assigned to that argument, and the remaining arguments a_{‑i}. This prediction is performed with a bilinear softmax: p(a_i|a_{‑i},r,v) ∝ exp(u_{a_i}ᵀ C_{v,r_i}ᵀ C_{v,r_j} u_{a_j}), where u_{a}∈ℝ^d are argument embeddings and C_{v,r}∈ℝ^{d×k} are predicate‑role projection matrices. The model thus captures compatibility between argument pairs conditioned on the predicate and forces the latent roles to encode information sufficient for accurate argument reconstruction.
Training aims to minimize the reconstruction error across the corpus: Σ_i log Σ_r p(a_i|a_{‑i},r,v)·p(r|x). Exact optimization is infeasible because (1) marginalizing over all role configurations is exponential in the number of arguments, and (2) the softmax normalizer Z requires summation over the entire vocabulary. The authors address these issues by (a) applying a mean‑field approximation that replaces the discrete role variables with their posterior expectations μ_i^s = p(r_i = s|x), and (b) estimating Z using negative sampling, a technique popular in word‑embedding learning. The combined objective is optimized with AdaGrad and random initialization.
Experiments are conducted on the English portion of the CoNLL‑2008 shared‑task data, following the evaluation protocol of prior unsupervised SRL work. The authors report purity, collocation, and their harmonic mean (F1). Their model discovers only 4–6 roles per predicate, yet achieves F1 scores comparable to or slightly better than the strongest existing unsupervised systems such as the Bayesian model of Titov & Klementiev (2012), Agglomerative clustering variants, and the global role‑ordering approach. Importantly, the induced roles are more interpretable: agents and patients are clearly separated, whereas competing models often produce dozens of fine‑grained clusters that dilute purity. The results demonstrate that jointly optimizing an encoder and a reconstruction decoder can guide the latent role space toward linguistically meaningful categories without any hand‑crafted language‑specific signatures.
The contributions of the work are threefold: (1) a principled joint learning objective that combines a discriminative, feature‑rich encoder with a generative, tensor‑factorization decoder; (2) a demonstration that reconstruction‑error minimization, a technique widely used in neural autoencoders, is effective for training log‑linear models of semantics; (3) empirical evidence that the approach reaches state‑of‑the‑art performance on English unsupervised SRL while producing a compact, human‑readable role inventory. The paper also bridges the gap between distributional semantics (through embeddings u) and structured semantic role induction, suggesting a promising direction for future research, such as extending the model to multilingual settings, integrating argument identification, or incorporating deeper neural architectures for the encoder.
Comments & Academic Discussion
Loading comments...
Leave a Comment