Co-community Structure in Time-varying Networks
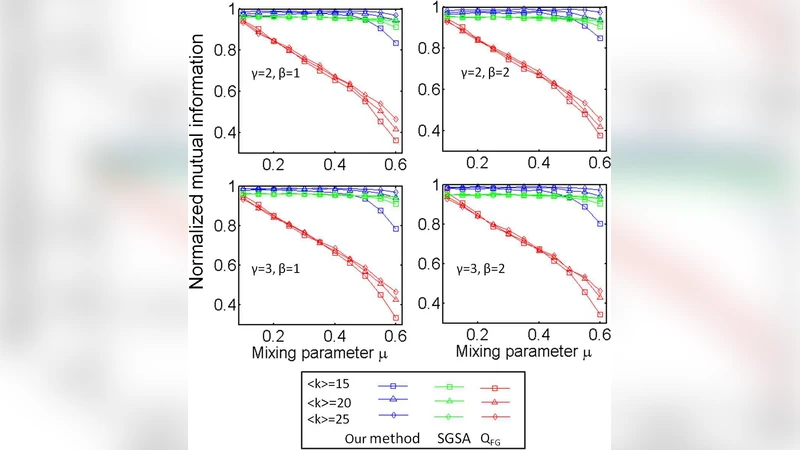
In this report, we introduce the concept of co-community structure in time-varying networks. We propose a novel optimization algorithm to rapidly detect co-community structure in these networks. Both theoretical and numerical results show that the proposed method not only can resolve detailed co-communities, but also can effectively identify the dynamical phenomena in these networks.
💡 Research Summary
The paper introduces the notion of “co‑community” structure in time‑varying networks, i.e., a set of communities that are shared across two or more network snapshots while allowing individual vertices to change their community affiliations over time. To formalize this, the authors consider G networks G₁,…,G_G on the same vertex set V (|V| = N) with adjacency matrices A₁,…,A_G. For each network g they define a membership matrix H_g ∈ ℝ^{N×K} (K is the number of communities) and a virtual common membership matrix H that captures the shared community pattern across all snapshots. The objective function to be minimized is
∑_{g=1}^G ‖A_g – H_g H_gᵀ‖F² + λ₁ ∑{g=1}^G ‖H_g – H‖₁ + λ₂ ‖H‖₁ .
The first term forces each H_g to reconstruct its own adjacency matrix, while the L₁‑regularization terms enforce similarity between H_g and the common matrix H and promote sparsity, thereby yielding a concise representation of the co‑community structure.
Because the problem is non‑convex and non‑smooth, the authors apply a variable‑splitting strategy that yields two alternating sub‑problems. With H fixed, each H_g is updated by solving a symmetric non‑negative matrix factorization (SNMF) problem using the multiplicative rule
(H_g){ik} ← (f H_g){ik}^{1–β} + β· (A_g f H_g){ik} / (f H_g f H_gᵀ f H_g){ik} ,
where f H_g = H_g + Δ(H_g – H) and β ∈ (0,1] controls the step size. After updating all H_g, the columns of the factor matrices are reordered to maximize pairwise correlations, ensuring a consistent community labeling across snapshots.
With the updated H_g’s, the common matrix H is obtained by solving
min λ₁ ∑_{g=1}^G ‖H_g – H‖₁ + λ₂ ‖H‖₁ ,
which can be transformed into a large‑scale linear program and efficiently solved by an additional decomposition (e.g., ADMM). The L₁ penalty drives many entries of H to zero, giving a sparse matrix that directly indicates which vertices belong to which co‑communities.
The overall algorithm proceeds as follows: (1) initialize λ₁, λ₂, β, K and random H₁, H₂ (or all H_g); (2) set H = Σ_g H_g; (3) iteratively update H_g via the SNMF rule, reorder columns, then update H via the L₁ sub‑problem; (4) stop when the relative change ‖H^{new} – H^{old}‖_F / ‖H^{old}‖_F falls below 10⁻⁵. The computational complexity is O(T·K·N²), where T is the number of outer iterations, making the method scalable to networks with tens of thousands of nodes.
To quantify the stability of the discovered co‑communities, the authors define a Co‑Community Entropy (CCE) score. For each pair of vertices (i, j) they compute c_{ij}, the empirical probability (over multiple runs) that i and j belong to the same co‑community. The CCE is
CCE = – (2 / N(N–1)) Σ_{i<j}
Comments & Academic Discussion
Loading comments...
Leave a Comment