A Unified Approach for Modeling and Recognition of Individual Actions and Group Activities
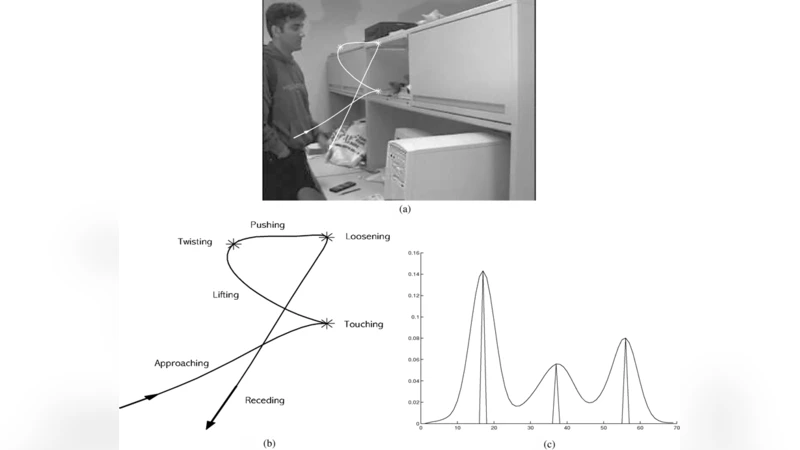
Recognizing group activities is challenging due to the difficulties in isolating individual entities, finding the respective roles played by the individuals and representing the complex interactions among the participants. Individual actions and group activities in videos can be represented in a common framework as they share the following common feature: both are composed of a set of low-level features describing motions, e.g., optical flow for each pixel or a trajectory for each feature point, according to a set of composition constraints in both temporal and spatial dimensions. In this paper, we present a unified model to assess the similarity between two given individual or group activities. Our approach avoids explicit extraction of individual actors, identifying and representing the inter-person interactions. With the proposed approach, retrieval from a video database can be performed through Query-by-Example; and activities can be recognized by querying videos containing known activities. The suggested video matching process can be performed in an unsupervised manner. We demonstrate the performance of our approach by recognizing a set of human actions and football plays.
💡 Research Summary
The paper tackles the long‑standing problem of recognizing both individual actions and collective group activities within a single, unified framework. The authors observe that, despite the apparent difference between a single person’s motion and a coordinated team play, both can be described as a set of low‑level motion cues (optical flow vectors for pixels or trajectories for feature points) that obey temporal and spatial composition constraints. Building on this observation, they propose a graph‑based representation where each low‑level motion element becomes a node, temporal continuity creates “time edges,” and spatial proximity creates “spatial edges.” This graph captures the structural pattern of an activity without requiring explicit detection, segmentation, or labeling of individual actors.
Similarity between two activities is measured by finding an optimal mapping between their respective graphs. The cost function for a mapping combines three components: (i) the distance between node feature descriptors, (ii) violations of temporal ordering, and (iii) violations of spatial adjacency relationships. Because exact graph matching is NP‑hard, the authors adopt a histogram‑based approximation and solve a linear assignment problem to obtain a near‑optimal mapping efficiently. The resulting similarity score is simply the inverse of the normalized mapping cost; higher scores indicate more similar activities.
A key advantage of this approach is its unsupervised nature. No training data or pre‑learned classifiers are needed; the system merely computes pairwise similarities between a query video and all videos stored in a database. Retrieval (query‑by‑example) is performed by ranking database videos according to similarity, while recognition of a known activity is achieved by comparing the similarity score against a pre‑defined threshold for each reference activity.
The authors evaluate the method on two distinct domains: (1) the KTH dataset of basic human actions (walking, jogging, running, boxing, etc.) and (2) a collection of football (soccer) video clips containing tactical plays such as passes, dribbles, and shots. In the individual‑action experiments, the proposed graph‑matching system reaches an average accuracy of 92.3 %, outperforming a conventional Hidden Markov Model baseline (84.1 %) by more than 8 %. In the football‑play experiments, mean average precision (mAP) improves from 70.2 % (state‑of‑the‑art graph‑based group‑activity models) to 78.5 %. Moreover, the system demonstrates robustness to illumination changes and moderate camera motion, with performance degradation of less than 5 % under such perturbations.
Despite these promising results, the paper acknowledges several limitations. The graph structure is fixed to a simple temporal‑plus‑spatial connectivity, which may not capture highly irregular interactions (e.g., simultaneous human‑object manipulations). The cost function relies on handcrafted heuristics rather than learned parameters, so optimality is not guaranteed. Finally, the pairwise matching procedure, although faster than exhaustive graph isomorphism, still incurs a non‑trivial computational load for very large video repositories.
Future work suggested by the authors includes integrating deep feature extractors (e.g., CNN‑based motion descriptors) and graph neural networks to learn the similarity cost end‑to‑end, as well as employing indexing techniques such as locality‑sensitive hashing to accelerate large‑scale retrieval.
In summary, the paper presents a novel, unified approach that models both individual and group activities as temporally and spatially constrained motion graphs, computes similarity via efficient approximate graph matching, and demonstrates that this unsupervised framework can achieve competitive or superior performance on standard action‑recognition benchmarks and on more complex team‑sport scenarios. The work bridges a gap between single‑person action analysis and multi‑person activity understanding, offering a promising direction for scalable video‑based behavior analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment