Comparative Bi-stochastizations and Associated Clusterings/Regionalizations of the 1995-2000 U. S. Intercounty Migration Network
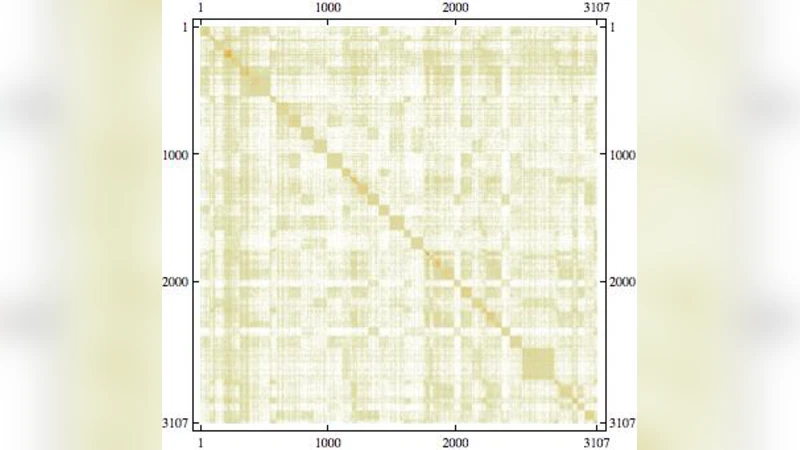
Wang, Li and Konig have recently compared the cluster-theoretic properties of bi-stochasticized symmetric data similarity (e. g. kernel) matrices, produced by minimizing two different forms of Bregman divergences. We extend their investigation to non-symmetric matrices, specifically studying the 1995-2000 U. S. 3,107 x 3,107 intercounty migration matrix. A particular bi-stochastized form of it had been obtained (arXiv:1207.0437), using the well-established Sinkhorn-Knopp (SK) (biproportional) algorithm–which minimizes the Kullback-Leibler form of the divergence. This matrix has but a single entry equal to (the maximal possible value of) 1. Highly contrastingly, the bi-stochastic matrix obtained here, implementing the Wang-Li-Konig-algorithm for the minimum of the alternative, squared-norm form of the divergence, has 2,707 such unit entries. The corresponding 3,107-vertex, 2,707-link directed graph has 2,352 strong components. These consist of 1,659 single/isolated counties, 654 doublets (thirty-one interstate in nature), 22 triplets (one being interstate), 13 quartets (one being interstate), three quintets and one septet. Not manifest in these graph-theoretic results, however, are the five-county states of Hawaii and Rhode Island and the eight-county state of Connecticut. These–among other regional configurations–appealingly emerged as well-defined entities in the SK-based strong-component hierarchical clustering.
💡 Research Summary
The paper investigates two distinct bi‑stochastic normalization procedures applied to a large, non‑symmetric migration matrix that records inter‑county movements in the United States between 1995 and 2000. The matrix has dimensions 3,107 × 3,107, representing every county as both a source and a destination. The authors extend the recent work of Wang, Li, and König, who compared cluster‑theoretic properties of bi‑stochastic symmetric similarity (kernel) matrices generated by minimizing two different Bregman divergences, to the far more realistic case of a non‑symmetric flow matrix.
The first normalization uses the classic Sinkhorn‑Knopp (SK) algorithm, which iteratively rescales rows and columns to achieve doubly stochastic form while minimizing the Kullback‑Leibler (KL) divergence. KL divergence measures the relative entropy between the original and the scaled matrix, preserving the information content of the original flow as much as possible. After applying SK, the resulting bi‑stochastic matrix contains a single entry equal to 1, with all other entries close to zero. This indicates that, under KL minimization, the migration network collapses into a very sparse structure dominated by one strong reciprocal link, while the rest of the flow is diffused across many near‑zero entries.
The second normalization implements the Wang‑Li‑König algorithm, which minimizes the squared‑norm form of the Bregman divergence. The squared‑norm (ℓ₂²) divergence penalizes the Euclidean distance between the original and the scaled matrix, encouraging a more uniform distribution of mass across entries. The outcome is dramatically different: 2,707 entries become exactly 1, and the remaining entries are zero. In effect, the matrix is turned into an almost binary adjacency matrix where each unit entry corresponds to a pair of counties with a strong, mutually significant migration exchange.
Treating this binary matrix as a directed graph yields 3,107 vertices and 2,707 directed edges. Strong‑component analysis (identifying maximal sub‑graphs where every vertex is reachable from every other vertex) reveals 2,352 distinct components. The majority, 1,659 components, are isolated vertices—counties that have no reciprocal migration ties under the squared‑norm normalization. The remaining components consist of small clusters: 654 doublets (31 of which cross state borders), 22 triplets (one interstate), 13 quartets (one interstate), three quintets, and a single septet. These clusters expose tightly knit regional groups that are not apparent in the KL‑based SK result.
A notable observation is that the five‑county states of Hawaii and Rhode Island, and the eight‑county state of Connecticut, emerge as well‑defined entities in the hierarchical clustering derived from the SK‑based strong components, even though they are not highlighted by the squared‑norm graph analysis. This contrast underscores how the choice of divergence fundamentally reshapes the perceived community structure of the same underlying migration data.
The authors argue that the divergent outcomes have practical implications. KL‑based bi‑stochastic scaling preserves the global entropy of the flow and is suitable when the analyst wishes to retain the overall distribution of migration while enforcing stochastic constraints. In contrast, squared‑norm scaling emphasizes strong bilateral exchanges and is valuable for uncovering localized, functionally cohesive regions. Consequently, policymakers, regional planners, and demographers should select the normalization method that aligns with their analytical goals: a global, entropy‑preserving view versus a local, interaction‑focused view.
Finally, the paper demonstrates that applying Bregman‑divergence‑based bi‑stochastic transformations to non‑symmetric flow data yields rich, multi‑scale insights into human mobility patterns. By juxtaposing the two approaches, the study provides a methodological template for extracting both hierarchical, entropy‑driven clusters and dense, reciprocal sub‑networks from large migration matrices, thereby informing more nuanced transportation planning, resource allocation, and regional development strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment