Sampling properties of directed networks
For many real-world networks only a small “sampled” version of the original network may be investigated; those results are then used to draw conclusions about the actual system. Variants of breadth-first search (BFS) sampling, which are based on epidemic processes, are widely used. Although it is well established that BFS sampling fails, in most cases, to capture the IN-component(s) of directed networks, a description of the effects of BFS sampling on other topological properties are all but absent from the literature. To systematically study the effects of sampling biases on directed networks, we compare BFS sampling to random sampling on complete large-scale directed networks. We present new results and a thorough analysis of the topological properties of seven different complete directed networks (prior to sampling), including three versions of Wikipedia, three different sources of sampled World Wide Web data, and an Internet-based social network. We detail the differences that sampling method and coverage can make to the structural properties of sampled versions of these seven networks. Most notably, we find that sampling method and coverage affect both the bow-tie structure, as well as the number and structure of strongly connected components in sampled networks. In addition, at low sampling coverage (i.e. less than 40%), the values of average degree, variance of out-degree, degree auto-correlation, and link reciprocity are overestimated by 30% or more in BFS-sampled networks, and only attain values within 10% of the corresponding values in the complete networks when sampling coverage is in excess of 65%. These results may cause us to rethink what we know about the structure, function, and evolution of real-world directed networks.
💡 Research Summary
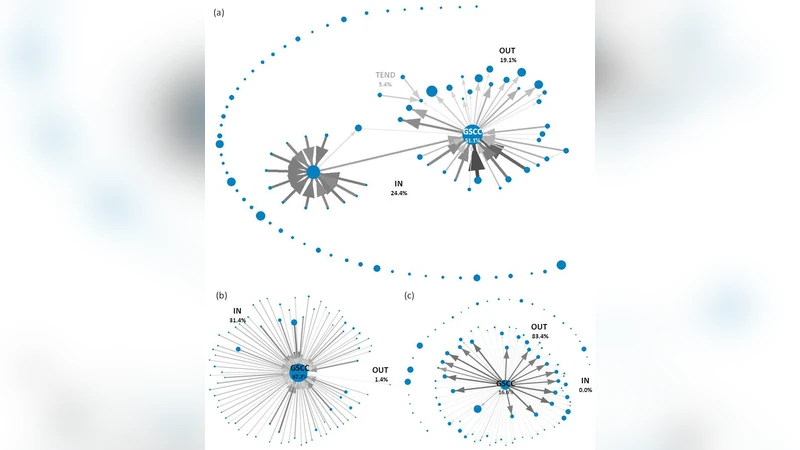
The paper tackles a fundamental methodological problem in network science: how faithfully do sampled versions of large directed graphs reflect the structural properties of the original networks? To answer this, the authors systematically compare two widely used sampling strategies—Breadth‑First Search (BFS) sampling, which mimics epidemic spreading, and uniform random sampling—across seven complete, real‑world directed networks. The data set includes three language editions of Wikipedia (English, German, French), three distinct web‑crawled graphs representing portions of the World Wide Web, and an Internet‑based social network (a follower graph). All networks are sizable (hundreds of thousands to millions of nodes) and exhibit the classic bow‑tie organization comprising IN, strongly connected component (SCC), OUT, tendrils, and disconnected parts.
For each network, the authors generate sampled subgraphs at incremental coverage levels ranging from 5 % to 100 % in 5 % steps. For every sampled graph they compute a suite of topological metrics: (i) average in‑ and out‑degree, (ii) degree variance, (iii) degree autocorrelation (correlation between a node’s in‑ and out‑degree), (iv) link reciprocity (fraction of bidirectional edges), (v) number and size distribution of SCCs, and (vi) the proportion of nodes belonging to each bow‑tie region. They then quantify the deviation of each metric from its value in the full network, using both absolute and relative errors.
The analysis reveals stark differences between the two sampling methods. BFS, by construction, expands outward from a seed node through already discovered neighborhoods, which leads to a pronounced bias toward the SCC and OUT regions while largely neglecting the IN component and tendrils. Consequently, at low coverage (≤ 40 %) BFS‑sampled graphs dramatically overestimate average degree (by more than 30 % on average), degree variance (≈ 35 % higher), and degree autocorrelation (inflated by 0.2–0.3). Reciprocity is also over‑estimated by roughly 20–30 %. The number of SCCs is reduced, and the size of the largest SCC dominates the sampled graph, distorting the perceived connectivity landscape.
In contrast, uniform random sampling distributes nodes and edges evenly across the entire graph, preserving the degree distribution and bow‑tie composition more faithfully even at modest coverage levels. Nonetheless, when coverage falls below 10 %, random samples begin to fragment the network: the total count of SCCs spikes, many tiny SCCs appear, and overall connectivity diminishes. Despite this, key metrics such as average degree and reciprocity stay within 10–15 % of the original values for coverage as low as 30–40 %.
A crucial practical finding is the coverage threshold required for BFS to yield reliable estimates. The authors show that only when the sampled fraction exceeds roughly 65 % do the BFS‑derived metrics converge to within 10 % of the true values. Random sampling reaches comparable accuracy at about 50 % coverage. This implies that studies relying on BFS to explore directed networks must either accept substantial bias or invest in sampling a majority of the nodes—a requirement often infeasible for massive online systems.
The paper’s contributions extend beyond the empirical observations. By quantifying how each metric deviates as a function of sampling method and coverage, the authors provide a diagnostic framework that can be applied to any directed network where only partial data are available. Their results caution against naïve interpretation of BFS‑derived statistics, especially in contexts where IN‑component dynamics (e.g., information inflow, vulnerability to upstream attacks) are critical. Moreover, the work highlights the need for bias‑correction techniques or hybrid sampling schemes that combine the efficiency of BFS with the representativeness of random sampling.
In summary, the study demonstrates that sampling methodology profoundly shapes our perception of directed network topology. BFS, while computationally attractive, systematically inflates degree‑related measures and obscures portions of the bow‑tie structure, whereas random sampling offers a more balanced view but still suffers from fragmentation at very low coverage. Researchers must therefore carefully select sampling strategies and ensure sufficient coverage—ideally above 65 % for BFS or 50 % for random sampling—to draw robust conclusions about the structure, function, and evolution of real‑world directed networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment