Recipe recommendation using ingredient networks
The recording and sharing of cooking recipes, a human activity dating back thousands of years, naturally became an early and prominent social use of the web. The resulting online recipe collections are repositories of ingredient combinations and cooking methods whose large-scale and variety yield interesting insights about both the fundamentals of cooking and user preferences. At the level of an individual ingredient we measure whether it tends to be essential or can be dropped or added, and whether its quantity can be modified. We also construct two types of networks to capture the relationships between ingredients. The complement network captures which ingredients tend to co-occur frequently, and is composed of two large communities: one savory, the other sweet. The substitute network, derived from user-generated suggestions for modifications, can be decomposed into many communities of functionally equivalent ingredients, and captures users’ preference for healthier variants of a recipe. Our experiments reveal that recipe ratings can be well predicted with features derived from combinations of ingredient networks and nutrition information.
💡 Research Summary
The paper investigates how large‑scale, user‑generated cooking data can be mined to build ingredient‑based recommendation models. Using Allrecipes.com as a case study, the authors collected 46,337 recipes and 1,976,920 user reviews, each containing ingredient lists, preparation steps, cooking times, serving sizes, and nutritional facts. After extensive preprocessing—including regular‑expression cleaning and frequency filtering—they retained the 1,000 most common ingredients, which cover 94.9 % of all ingredient entries.
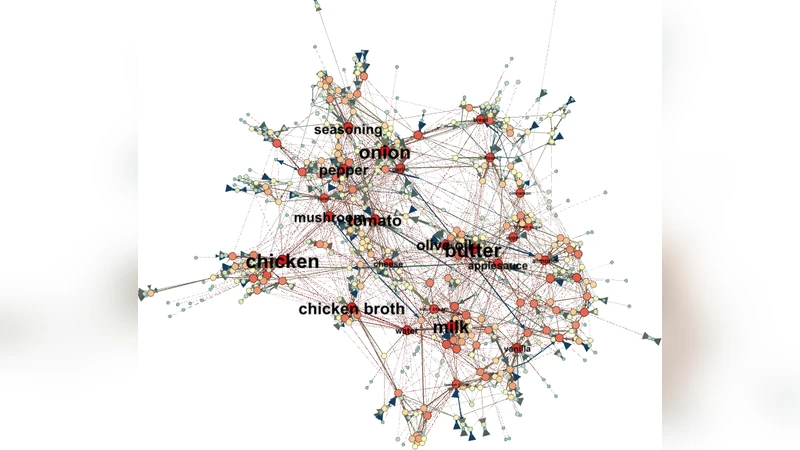
Two distinct networks are constructed. The Ingredient Complement Network links pairs of ingredients with an edge weight equal to their pointwise mutual information (PMI), a measure of how often the two appear together relative to chance. Community detection on this network reveals two dominant clusters corresponding to savory and sweet cuisines, plus a smaller cocktail cluster. Analysis of recipe‑level PMI statistics shows that the maximum PMI among ingredient pairs in a recipe correlates modestly (ρ = 0.09) with the recipe’s average rating, suggesting that having at least a couple of strongly complementary ingredients slightly boosts perceived quality.
The Ingredient Substitute Network is derived from review text. The authors identified 14 “modification cues” (e.g., “add”, “omit”, “instead”) and extracted the original ingredient and its suggested replacement from the surrounding sentence. This yields a directed graph where an edge a → b indicates that users have successfully replaced a with b. Community detection on this graph groups functionally equivalent or nutritionally healthier alternatives (e.g., butter → applesauce, whole milk → low‑fat milk). Notably, reviews that mention modifications have higher average ratings (4.49 vs. 4.39) and lower variance, indicating that flexibility is generally appreciated by the community.
For the predictive task, the authors treat the user rating as the target variable and assemble a feature set comprising: (i) complement‑network statistics (max, mean PMI), (ii) substitute‑network metrics (number of viable substitutes, substitution frequency), (iii) nutritional information (calories, fat, sugar, etc.), and (iv) recipe metadata (cooking time, difficulty). Several regression models (linear, random forest, gradient boosting) were evaluated; the best model achieved an R² of 0.792. Feature importance analysis revealed that network‑derived features contributed 84 % of the predictive power, while nutrition contributed the remaining 16 %. This demonstrates that relational information between ingredients is far more informative for rating prediction than raw nutritional data alone.
The study also explores regional cooking preferences within the United States, showing statistically significant differences in the use of cooking methods (e.g., grilling more common on the West Coast, boiling more common in the South). These findings underscore the cultural dimension of ingredient usage.
In discussion, the authors acknowledge limitations: the dataset is English‑only, the rule‑based extraction of modifications may miss nuanced language, and regional taste subtleties are only partially captured. They propose future work involving multilingual corpora, deep‑learning‑based NLP for more robust modification detection, and integration of personal dietary constraints to build a truly personalized recipe recommendation engine.
Overall, the paper makes a compelling case that ingredient‑level network analysis—both co‑occurrence (complement) and user‑driven substitution—provides rich, actionable signals for predicting recipe success and for designing recommendation systems that respect both culinary tradition and individual health preferences.
Comments & Academic Discussion
Loading comments...
Leave a Comment