Decision Based Uncertainty Propagation Using Adaptive Gaussian Mixtures
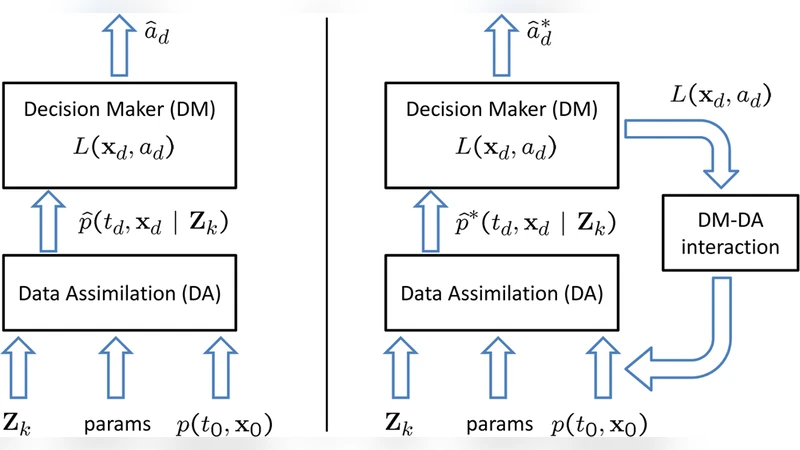
Given a decision process based on the approximate probability density function returned by a data assimilation algorithm, an interaction level between the decision making level and the data assimilation level is designed to incorporate the information held by the decision maker into the data assimilation process. Here the information held by the decision maker is a loss function at a decision time which maps the state space onto real numbers which represent the threat associated with different possible outcomes or states. The new probability density function obtained will address the region of interest, the area in the state space with the highest threat, and will provide overall a better approximation to the true conditional probability density function within it. The approximation used for the probability density function is a Gaussian mixture and a numerical example is presented to illustrate the concept.
💡 Research Summary
The paper addresses a critical gap in decision‑support systems for rare but high‑impact events such as CBRN incidents: conventional data‑assimilation (DA) techniques often produce probability density functions (PDFs) that inadequately represent the region of greatest concern, leading to severe under‑estimation of expected loss. The authors propose a non‑intrusive interaction layer that injects the decision maker’s loss function into the DA workflow without redesigning the underlying DA algorithm.
The loss function, denoted L(x_d, a_d), maps states at the decision time t_d to a real‑valued threat level. In the presented work it is modeled as a Gaussian centered on the most hazardous region (μ_L, Σ_L). The conditional PDF p(t, x | Z_k) is approximated by a Gaussian mixture (Gaussian Sum) with N components: each component i has mean μ_i(t|k), covariance P_i(t|k) and weight w_i(t|k). The mixture satisfies the usual positivity and normalization constraints.
The core contribution is the adaptive addition of new Gaussian components whose initial weights are set to zero. These components are placed near the loss‑function peak so that, if the system dynamics naturally drive probability mass toward the region of interest, the weights will become positive during propagation. Weight evolution is governed by minimizing the error in the Fokker‑Planck (FPKE) equation, leading to a quadratic programming problem (Equation 14). The objective includes a term L derived from integrals of the product of the FPKE residuals and the Gaussian basis functions; these integrals can be evaluated analytically for polynomial nonlinearities or approximated via Gaussian quadrature.
Propagation of each component’s mean and covariance follows standard Extended Kalman Filter (EKF) time‑update equations (11‑13). When measurements become available, a Bayes update is performed, and the weights are updated according to established Gaussian‑Sum filter formulas (cited from prior work). Because the new components start with zero weight, the initial uncertainty representation is unchanged; only the dynamics of the weights allow the mixture to “discover” probability mass in the high‑risk region.
Two performance criteria are defined: (i) the L2 distance between the true conditional PDF and the adapted mixture should be smaller than that of the baseline mixture (Equation 6); (ii) the absolute error in expected loss, |Ĺ*(a) – L(a)|, must be reduced relative to the baseline (Equation 7). The authors demonstrate the method on a simple two‑dimensional diffusion example. Compared with a conventional Gaussian‑Sum filter, the adaptive mixture concentrates additional probability density around the loss‑function center, resulting in a markedly lower expected‑loss estimation error while preserving overall PDF fidelity.
The paper acknowledges limitations: the number of added components grows linearly with the desired resolution of the region of interest, increasing computational load; solving the quadratic program at each time step requires careful numerical handling to maintain positivity and normalization of weights. Moreover, while a sketch is provided for handling intermediate observations (i.e., when measurements arrive between the current time and decision time), a full algorithmic treatment is left for future work.
In summary, the authors present a principled, mathematically grounded framework that leverages adaptive Gaussian mixtures to embed decision‑maker context into data assimilation. By aligning the PDF approximation with the loss function, the approach yields more accurate expected‑loss calculations, which is essential for high‑stakes decision making in uncertain, nonlinear dynamical systems. The method is non‑intrusive, compatible with existing DA pipelines, and holds promise for applications ranging from disaster response to military planning and environmental risk management.
Comments & Academic Discussion
Loading comments...
Leave a Comment