The Nuclear Science References (NSR) Database and Web Retrieval System
The Nuclear Science References (NSR) database together with its associated Web interface, is the world’s only comprehensive source of easily accessible low- and intermediate-energy nuclear physics bibliographic information for more than 200,000 articles since the beginning of nuclear science. The weekly-updated NSR database provides essential support for nuclear data evaluation, compilation and research activities. The principles of the database and Web application development and maintenance are described. Examples of nuclear structure, reaction and decay applications are specifically included. The complete NSR database is freely available at the websites of the National Nuclear Data Center http://www.nndc.bnl.gov/nsr and the International Atomic Energy Agency http://www-nds.iaea.org/nsr.
💡 Research Summary
The paper presents a comprehensive overview of the Nuclear Science References (NSR) database and its associated web retrieval system, emphasizing its unique role as the sole global bibliographic resource dedicated to low- and intermediate‑energy nuclear physics. Originating in the 1960s at Oak Ridge National Laboratory, NSR now contains over 200,000 records spanning more than a century of research, drawn from 473 journals, conference proceedings, laboratory reports, theses, preprints, and private communications. Since 1980, the National Nuclear Data Center (NNDC) at Brookhaven National Laboratory has taken primary responsibility for its maintenance, with the International Atomic Energy Agency (IAEA) and McMaster University contributing to compilation and development.
The database architecture is built on a relational MySQL 5 backend hosted on a RedHat Linux server equipped with dual 3.3 GHz Quad‑Core Xeon CPUs, 64 GB RAM, and a 450 GB 15 kRPM disk. The application layer uses Java EE 2, JSP, and Apache Tomcat 5.5, providing a robust, low‑maintenance environment. Each entry is assigned a unique eight‑character NSR key number (year, first author initials, sequential index) and stores bibliographic details such as authors, title, DOI, and a manually crafted keyword abstract. These keyword abstracts are the cornerstone of NSR’s indexing strategy: they encode nuclear species, reactions, measured quantities, calculated or deduced values, and experimental or theoretical methods in a highly structured natural‑language format. This enables precise Boolean searches and rapid retrieval of relevant literature.
Keyword generation is currently a manual process, ensuring high quality but limiting throughput. To address this, the authors have initiated a semi‑automated pipeline using Apache UIMA for semantic analysis of PDF articles, converting them to text and extracting candidate terms. Early tests show promise, though human oversight remains essential.
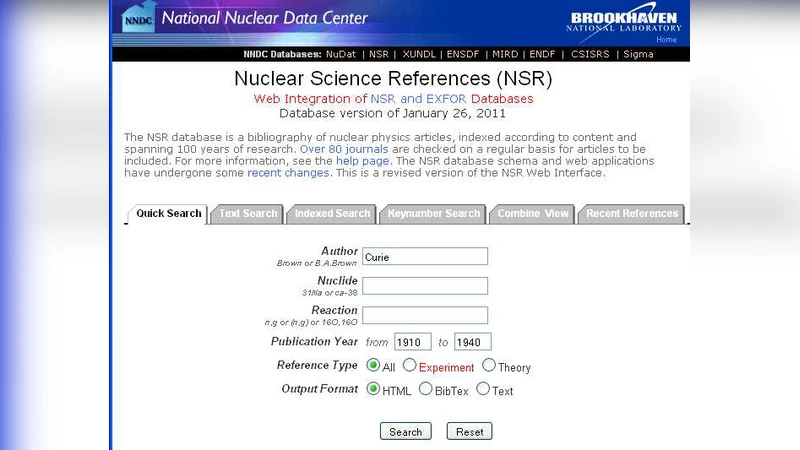
The web interface comprises six functional modules: Quick Search (author, nuclide, reaction, year), Text Search (free‑text in title and keyword fields), Indexed Search (Boolean queries across up to three indexed fields such as author, nuclide, reaction, subject, journal code), Keynumber Search (direct lookup by NSR key), Combine View (set operations on multiple query results), and Recent References (quarterly PDF compilations). Results can be exported in HTML, plain text, BibTex, or PDF. Approximately 80 % of records include keyword abstracts, which feed the indexed quantities used by the search engine.
A key differentiator from generic web search engines is NSR’s ability to disambiguate nuclear symbols and units. For example, “32 Mg” (magnesium‑32) is distinguished from “32 mg” (milligrams), avoiding the massive irrelevant hit lists typical of plain‑text indexing. This precision is vital for nuclear data evaluators, ENSDF compilers, and researchers conducting structure, reaction, or decay studies.
Usage statistics reveal substantial community reliance: the NNDC site records roughly 700 queries per day, each returning an average of 800 references, amounting to about 2.5 million retrievals annually. Retrieval counts have risen steadily over the past 25 years, reflecting both database growth and increasing demand for curated nuclear bibliographic data.
In conclusion, the NSR database serves as an indispensable infrastructure for nuclear physics, offering meticulously curated bibliographic records, sophisticated keyword‑based indexing, and a versatile web retrieval system. Ongoing efforts to incorporate semantic analysis for keyword generation, expand international collaboration, and maintain the underlying hardware and software will ensure its continued relevance and utility for the global nuclear science community.
Comments & Academic Discussion
Loading comments...
Leave a Comment