Optimal detection of changepoints with a linear computational cost
We consider the problem of detecting multiple changepoints in large data sets. Our focus is on applications where the number of changepoints will increase as we collect more data: for example in genetics as we analyse larger regions of the genome, or…
Authors: R. Killick, P. Fearnhead, I. A. Eckley
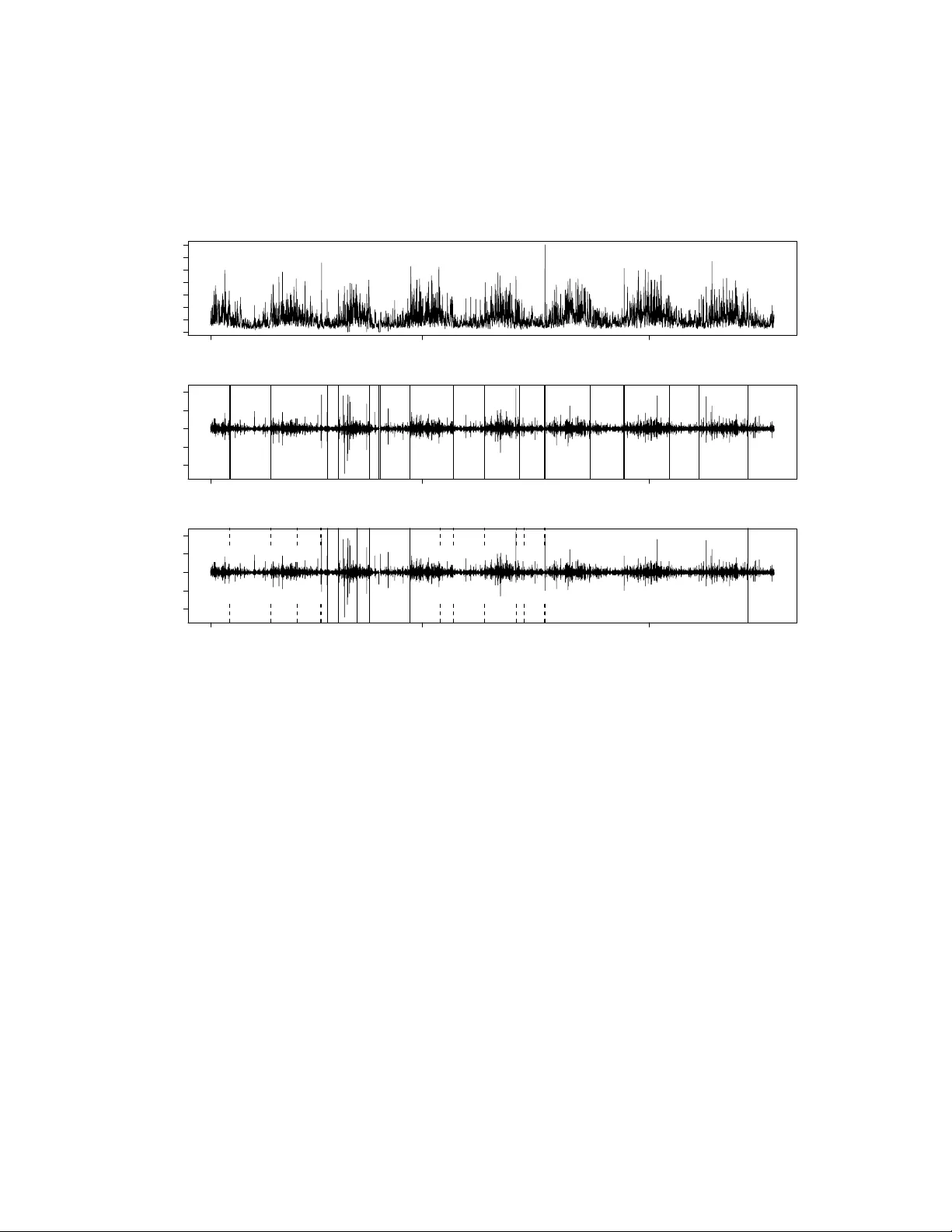
Optimal detection of c hangep oin ts with a linear computational cost Killic k, R., F earnhead, P . and Ec kley , I.A. ∗ No vem b er 26, 2024 Abstract W e consider the problem of detecting multiple c hangep oints in large data sets. Our fo cus is on applications where the num b er of changepoints will in- crease as w e collect more data: for example in genetics as w e analyse larger regions of the genome, or in finance as w e observ e time-series ov er longer p e- rio ds. W e consider the common approach of detecting changepoints through minimising a cost function o ver possible n umbers and locations of c hangep oints. This includes sev eral established pro cedures for detecting c hanging p oin ts, suc h as penalised lik eliho o d and minim um description length. W e introduce a new ∗ R. Killic k is Senior Research Associate, Department of Mathematics & Statistics, Lancaster Univ ersit y , Lancaster, UK (E-mail: r.killic k@lancs.ac.uk). P . F earnhead is Professor, Department of Mathematics & Statistics, Lancaster Univ ersit y , Lancaster, UK (E-mail: p.fearnhead@lancs.ac.uk). I.A. Ec kley is Senior Lecturer, Departmen t of Mathematics & Statistics, Lancaster Univ ersity , Lan- caster, UK (E-mail: i.ec kley@lancs.ac.uk). The authors are grateful to Ric hard Da vis and Alice Cleynen for pro viding the Auto-P ARM and PDP A softw are resp ectively . P art of this researc h w as conducted whilst R. Killic k w as a join tly funded Engineering and Physical Sciences Researc h Council (EPSR C) / Shell Researc h Ltd graduate student at Lancaster Univ ersity . Both I.A. Eckley and R. Killic k also gratefully ac knowledge the financial support of the EPSR C gran t num b er EP/I016368/1. 1 metho d for finding the minim um of such cost functions and hence the optimal n umber and lo cation of changepoints that has a computational cost whic h, un- der mild conditions, is linear in the num b er of observ ations. This compares fa vourably with existing metho ds for the same problem whose computational cost can b e quadratic or ev en cubic. In simulation studies w e sho w that our new metho d can be orders of magnitude faster than these alternativ e exact metho ds. W e also compare with the Binary Segmentation algorithm for iden- tifying changepoints, showing that the exactness of our approac h can lead to substan tial impro vemen ts in the accuracy of the inferred segmentation of the data. KEYW ORDS Structural Change; Dynamic Programming; Segmen tation; PEL T. 1. INTR ODUCTION As increasingly longer data sets are b eing collected, more and more applications re- quire the detection of changes in the distributional prop erties of such data. Consider for example recent w ork in genomics, lo oking at detecting changes in gene copy num- b ers or in the comp ositional structure of the genome (Braun et al., 2000; Olshen et al., 2004; Picard et al., 2005); and in finance where, for example, in terest lies in detecting c hanges in the v olatility of time series (Aggarw al et al., 1999; Andreou and Ghy- sels, 2002; F ernandez, 2004). T ypically suc h series will contain several changepoints. There is therefore a growing need to b e able to search for such c hanges efficiently . It is this search problem which w e consider in this pap er. In particular we fo cus on ap- plications where we exp ect the n umber of changepoints to increase as w e collect more data. This is a natural assumption in many cases, for example as we analyse longer regions of the genome or as w e record financial time-series o ver longer time-p erio ds. By comparison it do es not necessarily apply to situations where w e are obtaining data o ver a fixed time-p erio d at a higher frequency . 2 A t the time of writing Binary Segmen tation proposed by Scott and Knott (1974) is arguably the most widely used c hangep oin t searc h metho d. It is approximate in nature with an O ( n log n ) computational cost, where n is the n umber of data p oints. While exact search algorithms exist for the most common forms of changepoint mo d- els, these hav e a muc h greater computational cost. Seve ral exact search metho ds are based on dynamic programming. F or example the Segmen t Neighbourho o d metho d prop osed b y Auger and La wrence (1989) is O ( Qn 2 ), where Q is the maximum num b er of c hangep oin ts y ou wish to search for. Note that in scenarios where the num b er of c hangep oin ts increases linearly with n , this can corresp ond to a computational cost that is cubic in the length of the data. An alternativ e dynamic programming algo- rithm is pro vided b y the Optimal P artitioning approac h of Jac kson et al. (2005). As w e describ e in Section 2.2 this can b e applied to a slightly smaller class of problems and is an exact approach whose computational cost is O ( n 2 ). W e presen t a new approac h to search for c hangep oints, whic h is exact and under mild conditions has a computational cost that is linear in the num b er of data p oin ts: the P runed E xact L inear T ime (PEL T) method. This approac h is based on the algorithm of Jac kson et al. (2005), but inv olv es a pruning step within the dynamic program. This pruning reduces the computational cost of the metho d, but do es not affect the exactness of the resulting segmentation. It can b e applied to find changepoints under a range of statistical criteria such as p enalised likelihoo d, quasi-lik eliho o d (Braun et al., 2000) and cumulativ e sum of squares (Inclan and Tiao, 1994; Picard et al., 2011). In simulations w e compare PEL T with b oth Binary Segmen tation and Optimal P artitioning. W e sho w that PEL T can b e calculated orders of magnitude faster than Optimal Partitioning, particularly for long data sets. Whilst asymptotically PEL T can b e quic ker, w e find that in practice Binary Segmentation is quick er on the examples we consider, and we b elieve this would b e the case in almost all applications. 3 Ho wev er, we show that PEL T leads to a substan tially more accurate segmen tation than Binary Segmentation. The pap er is organised as follows. W e b egin in Section 2 b y reviewing some basic c hangep oin t notation and summarizing existing w ork in the area of search metho ds. The PEL T metho d is in tro duced in Section 3 and the computational cost of this approac h is considered in Section 3.1. The efficiency and accuracy of the PEL T metho d are demonstrated in Section 4. In particular w e demonstrate the metho ds’ p erformance on large data sets coming from oceanographic (Section 4.2) and financial (supplemen tary material) applications. Results sho w the speed gains o ver other exact searc h metho ds and the increased accuracy relative to appro ximate searc h metho ds suc h as Binary Segmentation. The pap er concludes with a discussion. 2. BA CKGR OUND Changep oin t analysis can, lo osely sp eaking, b e considered to b e the iden tification of p oin ts within a data set where the statistical prop erties c hange. More formally , let us assume we ha ve an ordered sequence of data, y 1: n = ( y 1 , . . . , y n ). Our mo del will ha ve a n umber of c hangep oin ts, m , together with their p ositions, τ 1: m = ( τ 1 , . . . , τ m ). Eac h c hangep oint p osition is an integer b etw een 1 and n − 1 inclusive. W e define τ 0 = 0 and τ m +1 = n and assume that the changepoints are ordered such that τ i < τ j if, and only if, i < j . Consequently the m changepoints will split the data in to m + 1 segmen ts, with the i th segment containing y ( τ i − 1 +1): τ i . One commonly used approach to iden tify multiple c hangep oints is to minimise: m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) + β f ( m ) . (1) Here C is a cost function for a segmen t and β f ( m ) is a p enalty to guard against o ver fitting. Twice the negativ e log lik eliho o d is a commonly used cost function in the changepoint literature (see for example Horv ath, 1993; Chen and Gupta, 2000), 4 although other cost functions suc h as quadratic loss and cum ulative sums are also used (e.g. Rigaill, 2010; Inclan and Tiao, 1994), or those based on b oth the segment log-lik eliho o d and the length of the segmen t (Zhang and Siegm und, 2007). T urning to choice of p enalt y , in practice b y far the most common choice is one whic h is linear in the n umber of changepoints, i.e. β f ( m ) = β m . Examples of suc h p enalties include Ak aik e’s Information Criterion (AIC, Ak aik e (1974)) ( β = 2 p ) and Sch w arz Informa- tion Criterion (SIC, also known as BIC; Sch w arz, 1978) ( β = p log n ), where p is the n umber of additional parameters in tro duced by adding a c hangep oint. The PEL T metho d whic h w e introduce in Section 3 is designed for such linear cost functions. Although linear cost functions are commonplace within the changepoint literature Guy on and Y ao (1999), Picard et al. (2005) and Birge and Massart (2007) offer ex- amples and discussion of alternative p enalty c hoices. In Section 3.2 w e sho w ho w PEL T can b e applied to some of these alternativ e c hoices. The remainder of this section describes tw o commonly used methods for m ultiple c hangep oin t detection; Binary Segmen tation (Scott and Knott, 1974) and Segment Neigh b ourho o ds (Auger and Lawrence, 1989). A third metho d prop osed b y Jackson et al. (2005) is also describ ed as it forms the basis for the PEL T metho d which we prop ose. F or notational simplicity we describ e all the algorithms (including PEL T) assuming that the minim um segment length is a single observ ation, i.e. τ i − 1 − τ i ≥ 1. A larger minimum segmen t length is easily implemen ted when appropriate, see for example Section 4. 2.1 Binary Segmen tation Binary Segmentation (BS) is arguably the most established search metho d used within the c hangep oin t literature. Early applications include Scott and Knott (1974) and Sen and Sriv asta v a (1975). In essence the metho d extends any single c hangep oint method 5 to m ultiple c hangep oin ts b y iteratively rep eating the metho d on different subsets of the sequence. It b egins b y initially applying the single changepoint metho d to the en tire data set, i.e. we test if a τ exists that satisfies C ( y 1: τ ) + C ( y ( τ +1): n ) + β < C ( y 1: n ) . (2) If (2) is false then no changepoint is detected and the metho d stops. Otherwise the data is split into tw o segments consisting of the sequence before and after the iden tified changepoint, τ a sa y , and apply the detection metho d to eac h new segmen t. If either or both tests are true, w e split these into further segments at the newly iden tified c hangep oint(s), applying the detection metho d to eac h new segmen t. This pro cedure is rep eated until no further changepoints are detected. F or pseudo-co de of the BS metho d see for example Eckley et al. (2011). Binary Segmentation can b e view ed as attempting to minimise equation (1) with f ( m ) = m : eac h step of the algorithm attempts to introduce an extra c hangep oint if and only if it reduces (1). The adv an tage of the BS metho d is that it is computation- ally efficient, resulting in an O ( n log n ) calculation. How ev er this comes at a cost as it is not guaranteed to find the global minimum of (1). 2.2 Exact metho ds Se gment Neighb ourho o d Auger and Lawrence (1989) propose an alternativ e, ex- act search metho d for c hangep oint detection, namely the Segment Neighbourho o d (SN) metho d. This approach searc hes the entire segmen tation space using dynamic programming (Bellman and Dreyfus, 1962). It b egins by setting an upp er limit on the size of the segmen tation space (i.e. the maximum n umber of c hangep oints) that is required – this is denoted Q . The metho d then con tinues by computing the cost function for all p ossible segments. F rom this all p ossible segmen tations with b etw een 0 and Q changepoints are considered. 6 In addition to b eing an exact searc h metho d, the SN approac h has the ability to incorp orate an arbitrary p enalty of the form, β f ( m ). Ho wev er, a consequence of the exhaustiv e search is that the metho d has significan t computational cost, O ( Qn 2 ). If as the observed data increases, the num b er of changepoints increases linearly , then Q = O ( n ) and the metho d will ha ve a computational cost of O ( n 3 ). The optimal p artitioning metho d Y ao (1984) and Jac kson et al. (2005) prop ose a searc h metho d that aims to minimise m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) + β . (3) This is equiv alen t to (1) where f ( m ) = m . F ollo wing Jackson et al. (2005) the optimal partitioning (OP) metho d b egins by first conditioning on the last p oin t of change. It then relates the optimal v alue of the cost function to the cost for the optimal partition of the data prior to the last c hangep oin t plus the cost for the segment from the last changepoint to the end of the data. More formally , let F ( s ) denote the minimisation from (3) for data y 1: s and T s = { τ : 0 = τ 0 < τ 1 < · · · < τ m < τ m +1 = s } be the set of p ossible vectors of c hangep oin ts for suc h data. Finally set F (0) = − β . It therefore follows that: F ( s ) = min τ ∈T s ( m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) + β ) , = min t ( min τ ∈T t m X i =1 C ( y ( τ i − 1 +1): τ i ) + β + C ( y ( t +1): n ) + β ) , = min t F ( t ) + C ( y ( t +1): n ) + β . This provides a recursion which giv es the minimal cost for data y 1: s in terms of the minimal cost for data y 1: t for t < s . This recursion can b e solved in turn for s = 1 , 2 , . . . , n . The cost of solving the recursion for time s is linear in s , so the o verall computational cost of finding F ( n ) is quadratic in n . Steps for implementing the OP metho d are giv en in Algorithm 1. 7 Optimal Partitioning Input: A set of data of the form, ( y 1 , y 2 , . . . , y n ) where y i ∈ R . A measure of fit C ( · ) dependent on the data. A p enalty constan t β whic h do es not dep end on the num b er or location of changepoints. Initialise: Let n = length of data and set F (0) = − β , cp (0) = N U LL . Iterate for τ ∗ = 1 , . . . , n 1. Calculate F ( τ ∗ ) = min 0 ≤ τ <τ ∗ F ( τ ) + C ( y ( τ +1): τ ∗ ) + β . 2. Let τ 0 = arg min 0 ≤ τ <τ ∗ F ( τ ) + C ( y ( τ +1): τ ∗ ) + β . 3. Set cp ( τ ∗ ) = ( cp ( τ 0 ) , τ 0 ). Output the c hange points recorded in cp ( n ). Algorithm 1: Optimal Partitioning. Whilst OP improv es on the computational efficiency of the SN metho d, it is still far from b eing comp etitive computationally with the BS metho d. Section 3 introduces a mo dification of the optimal partitioning method denoted PEL T whic h results in an approac h whose computational cost can b e linear in n whilst retaining an exact min- imisation of (3). This exact and efficien t computation is achiev ed via a combination of optimal partitioning and pruning. 3. A PR UNED EXA CT LINEAR TIME METHOD W e now consider how pruning can b e used to increase the computational efficiency of the OP metho d whilst still ensuring that the metho d finds a global minim um of the cost function (3). The essence of pruning in this context is to remov e those v alues of τ whic h can never b e minima from the minimisation performed at each iteration in (1) of Algorithm 1. The follo wing theorem giv es a simple condition under whic h we can do suc h pruning. 8 Theorem 3.1 We assume that when intr o ducing a changep oint into a se quenc e of observations the c ost, C , of the se quenc e r e duc es. Mor e formal ly, we assume ther e exists a c onstant K such that for al l t < s < T , C ( y ( t +1): s ) + C ( y ( s +1): T ) + K ≤ C ( y ( t +1): T ) . (4) Then if F ( t ) + C ( y ( t +1): s ) + K ≥ F ( s ) (5) holds, at a futur e time T > s , t c an never b e the optimal last changep oint prior to T . Pro of. See Section 5 of Supplemen tary Material. The in tuition b ehind this result is that if (5) holds then for an y T > s the b est segmen tation with the most recent changepoint prior to T b eing at s will b e b etter than an y which has this most recen t changepoint at t . Note that almost all cost functions used in practice satisfy assumption (4). F or example, if w e tak e the cost function to b e min us the log-likelihoo d then the constan t K = 0 and if w e tak e it to b e minus a p enalised log-lik eliho o d then K would equal the p enalisation factor. The condition imp osed in Theorem 3.1 for a candidate c hangep oint, t , to b e dis- carded from future consideration is imp ortant as it remov es computations that are not relev an t for obtaining the final set of changepoints. This condition can b e easily implemen ted in to the OP metho d and the pseudo-co de is given in Algorithm 2. This sho ws that at each step in the metho d the candidate changepoints satisfying the con- dition are noted and remo v ed from the next iteration. W e show in the next section that under certain conditions the computational cost of this metho d will b e linear in the num b er of observ ations, as a result w e call this the P runed E xact L inear T ime (PEL T) metho d. 9 PEL T Method Input: A set of data of the form, ( y 1 , y 2 , . . . , y n ) where y i ∈ R . A measure of fit C ( . ) dependent on the data. A p enalty constan t β whic h do es not dep end on the num b er or location of changepoints. A constant K that satisfies equation 4. Initialise: Let n = length of data and set F (0) = − β , cp (0) = N U LL , R 1 = { 0 } . Iterate for τ ∗ = 1 , . . . , n 1. Calculate F ( τ ∗ ) = min τ ∈ R τ ∗ F ( τ ) + C ( y ( τ +1): τ ∗ ) + β . 2. Let τ 1 = arg min τ ∈ R τ ∗ F ( τ ) + C ( y ( τ +1): τ ∗ ) + β . 3. Set cp ( τ ∗ ) = [ cp ( τ 1 ) , τ 1 ]. 4. Set R τ ∗ +1 = { τ ∈ R τ ∗ ∪ { τ ∗ } : F ( τ ) + C ( y τ +1: τ ∗ ) + K ≤ F ( τ ∗ ) } . Output the c hange points recorded in cp ( n ). Algorithm 2: PEL T Metho d. 3.1 Linear Computational Cost of PEL T W e now inv estigate the theoretical computational cost of the PEL T metho d. W e fo cus on the most imp ortan t class of c hangep oin t mo dels and penalties and provide sufficien t conditions for the metho d to hav e a computational cost that is linear in the n umber of data p oints. The case we fo cus on is the set of mo dels where the segment parameters are indep enden t across segments and the cost function for a segmen t is min us the maxim um log-lik eliho o d v alue for the data in that segment. More formally , our result relates to the exp ected computational cost of the metho d and ho w this dep ends on the n umber of data p oin ts w e analyse. T o this end we define an underlying sto c hastic mo del for the data generating pro cess. Specifically we define suc h a pro cess ov er p ositive-in teger time p oints and then consider analysing the first n data points generated by this pro cess. Our result assumes that the parameters 10 asso ciated with a giv en segmen t are I ID with densit y function π ( θ ). F or notational simplicit y we assume that giv en the parameter, θ , for a segmen t, the data p oints within the segment are IID with densit y function f ( y | θ ) although extensions to de- p endence within a segment is trivial. Finally , as previously stated our cost function will b e based on min us the maxim um log-lik eliho o d: C ( y ( t +1): s ) = − max θ s X i = t +1 log f ( y i | θ ) . Note that for this loss-function, K = 0 in (4). Hence pruning in PEL T will just dep end on the choice of p enalt y constan t β . W e also require a stochastic mo del for the lo cation of the changepoints in the form of a mo del for the length of each segmen t. If the c hangep oin t p ositions are τ 1 , τ 2 , . . . , then define the segmen t lengths to b e S 1 = τ 1 and for i = 2 , 3 , . . . , S i = τ i − τ i − 1 . W e assume the S i are I ID copies of a random v ariable S . F urthermore S 1 , S 2 , . . . , are indep enden t of the parameters asso ciated with the segments. Theorem 3.2 Define θ ∗ to b e the value that maximises the exp e cte d lo g-likeliho o d θ ∗ = arg max Z Z f ( y | θ ) f ( y | θ 0 ) d y π ( θ 0 ) d θ 0 . L et θ i b e the true p ar ameter asso ciate d with the se gment c ontaining y i and ˆ θ n b e the maximum likeliho o d estimate for θ given data y 1: n and an assumption of a single se gment: ˆ θ n = arg max θ n X i =1 log f ( y i | θ ) . Then if (A1) denoting B n = n X i =1 h log f ( y i | ˆ θ n ) − log f ( y i | θ ∗ ) i , we have E ( B n ) = o ( n ) and E ([ B n − E ( B n )] 4 ) = O ( n 2 ) ; 11 (A2) E [log f ( Y i | θ i ) − log f ( Y i | θ ∗ )] 4 < ∞ ; (A3) E S 4 < ∞ ; and (A4) E (log f ( Y i | θ i ) − log f ( Y i | θ ∗ )) > β E ( S ) ; wher e S is the exp e cte d se gment length, the exp e cte d CPU c ost of PEL T for analysing n data p oints is b ounde d ab ove by Ln for some c onstant L < ∞ . Pro of. See Section 6 of Supplemen tary Material. Conditions (A1) and (A2) of Theorem 3.2 are w eak tec hnical conditions. F or example, general asymptotic results for maxim um likelihoo d estimation w ould giv e B n = O p (1), and (A1) is a slightly stronger condition which is con trolling the probabilit y of B n taking v alues that are O ( n 1 / 2 ) or greater. The other t w o conditions are more imp ortan t. Condition (A3) is needed to control the probabilit y of large segments. One imp ortant consequence of (A3) is that the exp ected n umber of c hangep oints will increase linearly with n . Finally condition (A4) is a natural one as it is required for the exp ected p enalised lik eliho o d v alue obtained with the true changepoint and parameter v alues to b e greater than the exp ected p enalised lik eliho o d v alue if we fit a single segmen t to the data with segment parameter θ ∗ . In all cases the worst case complexity of the algorithm is where no pruning o ccurs and the computational cost is O ( n 2 ). 3.2 PEL T for concav e p enalties There is a growing b o dy of research (see Guyon and Y ao, 1999; Picard et al., 2005; Birge and Massart, 2007) that consider nonlinear p enalty forms. In this section we 12 address ho w PEL T can b e applied to p enalty functions whic h are conca v e. β f ( m ) + m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) , (6) where f ( m ) is concav e and differentiable. F or an appropriately chosen γ , the following result sho ws that the optimum segmen- tation based on such a p enalt y corresp onds to minimising mγ + m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) . (7) Theorem 3.3 Assume that f is c onc ave and differ entiable, with derivative denote d f 0 . F urther, let ˆ m b e the value of m for which the criteria (6) is minimise d. Then the optimal se gmentation under this set of p enalties is the se gmentation that minimises mf 0 ( ˆ m ) + m +1 X i =1 C ( y ( τ i − 1 +1): τ i ) . (8) Pro of. See Section 7 of Supplemen tary Material. This suggests that we can minimize p enalty functions based on f ( m ) using PEL T – the correct p enalty constan t just needs to b e applied. A simple approac h, is to run PEL T with an arbitrary p enalty constant, sa y γ = f 0 (1). Let m 0 denote the resulting num b er of changepoints estimated. W e then run PEL T with p enalty constan t γ = f 0 ( m 0 ), and get a new estimate of the num b er of changepoints m 1 . If m 0 = m 1 w e stop. Otherwise we up date the p enalty constan t and rep eat un til conv ergence. This simple pro cedure is not guaran teed to find the optimal num b er of c hangep oin ts. Indeed more elab orate searc h schemes ma y b e b etter. Ho w ev er, as tests of this simple approach in Section 4.3 show, it can b e quite effective. 4. SIMULA TION AND DA T A EXAMPLES W e no w compare PEL T with b oth Optimal P artitioning (OP) and Binary Segmen- tation (BS) on a range of simulated and real examples. Our aim is to see empirically 13 (i) ho w the computational cost of PEL T is affected by the amoun t of data, (ii) to ev aluate the computational sa vings that PEL T gives o v er OP , and (iii) to ev aluate the increased accuracy of exact metho ds o ver BS. Unless otherwise stated, w e used the SIC p enalty . In this case the p enalty constan t increases with the amount of data, and as such the application of PEL T lies outside the conditions of Theorem 3.2. W e also consider the impact of the n umber of c hangep oints not increasing linearly with the amoun t of data, a further violation of the conditions of Theorem 3.2. 4.1 Changes in V ariance within Normally Distributed Data In the following subsections w e consider multiple c hanges in v ariance within data sets that are assumed to follow a Normal distribution with a constant (unknown) mean. W e b egin b y sho wing the p o w er of the PEL T metho d in detecting m ultiple changes via a simulation study , and then use PEL T to analyse Oceanographic data and Dow Jones Index returns (Section 2 in supplemen tary material). Simulation Study In order to ev aluate PEL T we shall construct sets of sim ulated data on whic h we shall run v arious multiple changepoint metho ds. It is reasonable to set the cost function, C as t wice the negativ e log-likelihoo d. Note that for a c hange in v ariance (with unkno wn mean), the minim um segment length is tw o observ ations. The cost of a segment is then C ( y ( τ i − 1 +1): τ i ) = ( τ i − τ i − 1 ) log(2 π ) + log P τ i j = τ i − 1 +1 ( y j − µ ) 2 τ i − τ i − 1 ! + 1 ! . (9) Our sim ulated data consists of scenarios with v arying lengths, n =(100, 200, 500, 1000, 2000, 5000, 10000, 20000, 50000). F or eac h v alue of n w e consider a linearly increasing num b er of c hangep oin ts, m = n/ 100. In eac h case the changepoints are distributed uniformly across (2 , n − 2) with the only constraint b eing that there m ust b e at least 30 observ ations b etw een c hangep oin ts. Within eac h of these scenarios 14 Figure 1: A realisation of m ultiple changes in v ariance where the true changepoint lo cations are sho wn by v ertical lines. 0 500 1000 1500 2000 −4 −2 0 2 4 w e ha ve 1,000 rep etitions where the mean is fixed at 0 and the v ariance parameters for each segmen t are assumed to ha v e a Log-Normal distribution with mean 0 and standard deviation log(10) 2 . These parameters are chosen so that 95% of the simulated v ariances are within the range 1 10 , 10 . An example realisation is sho wn in Figure 1. Additional sim ulations considering a wider range of options for the num b er of c hangep oin ts (square ro ot: m = b √ n/ 4 c and fixed: m = 2) and parameter v alues are giv en in Section 1 of the Supplemen tary Material. Results are sho wn in Figure 2 where we denote the Binary Segmentation method whic h identifies the same num b er of c hangep oints as PEL T as subBS. Con v ersely the num b er of changepoints BS w ould optimally select is called optimal BS. Firstly Figure 2(a) sho ws that when the n umber of changepoints increases linearly with n , PEL T do es indeed hav e a CPU cost that is linear in n . By comparison figures in the supplemen tary material sho w that if the n umber of c hangep oin ts increases at a slo wer rate, for example, square ro ot or even fixed n umber of changepoints, the CPU cost of PEL T is no longer linear. Ho wev er ev en in the latter tw o cases, substantial computational savings are attained relativ e to OP . Comparison of times with BS are also given in the Supplementary material. These show that PEL T and BS ha v e similar computational costs for the case of linearly increasing n umber of c hangep oin ts, but 15 Figure 2: (a) Average Computational Time (in seconds) for a change in v ariance (thin: OP , thic k: PEL T). (b) Average difference in cost b etw een PEL T and BS for subBS (thin), optimal BS (thic k)) (c) MSE for PEL T (thic k), optimal BS (thin) and subBS (dotted). (a) 0 10000 30000 50000 0 50 100 150 Computational Time (b) 0 10000 30000 50000 0 200 400 600 800 1000 Difference in o verall cost (c) 0 10000 30000 50000 0.0 0.1 0.2 0.3 0.4 0.5 MSE BS can b e orders of magnitude quick er for other situations. The adv an tage of PEL T ov er BS is that PEL T is guaran teed to find the optimal segmen tation under the c hosen cost function, and as suc h is lik ely to b e preferred pro viding sufficient computational time is a v ailable to run it. Figure 2(b) shows the impro ved fit to the data that PEL T attains ov er BS in terms of the smaller v alues of the cost function that are found. If y ou consider using the log-lik eliho o d to c ho ose b et w een comp eting mo dels, the v alue for n = 50 , 000 is ov er 1000 whic h is v ery large. An alternativ e comparison is to lo ok at ho w well each metho d estimates the parameters in the mo del. W e measure this using mean square error: MSE = P n i =1 ( ˆ θ i − θ i ) 2 n , (10) Figure 2(c) shows the increase in accuracy in terms of mean square error of esti- mates of the parameter. The figures in the supplementary material show that for the fixed n umber of changepoints scenario the difference is negligible but, for the linearly increasing n um b er of c hangep oin ts scenario, the difference is relativ ely large. A final w a y to compare the accuracy of PEL T with that of BS is to look at ho w accurately eac h metho d detects the actual times at whic h changepoints occurred. F or 16 Figure 3: Prop ortion of correctly identified c hangep oints against the proportion of falsely detected c hangep oin ts. Change in v ariance with m = n/ 100 where (a) n = 500, (b) n = 5 , 000, (c) n = 50 , 000 (PEL T: thic k line, BS: thin line, +: SIC p enalty). (a) 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 Propor tion F alse Positiv es Propor tion T r ue P ositives + + (b) 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 Propor tion F alse Positiv es Propor tion T r ue P ositives + + (c) 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 Propor tion F alse Positiv es Propor tion T r ue P ositives + + the purp oses of this study a changepoint is considered correctly identified if we infer its lo cation within a distance of 10 time-p oints of the true p osition. If tw o c hangep oin ts are iden tified in this windo w then one is counted as correct and one false. The n umber of false changepoints is then the total num b er of changepoints iden tified minus the n umber correctly iden tified. The results are depicted in Figure 3 for a selection of data lengths, n , for the case m = n/ 100. As n increases the difference b et ween the PEL T and BS algorithms b ecomes clearer with PEL T correctly identifying more c hangep oin ts than BS. Qualitatively similar results are obtained if w e c hange how close an inferred c hangep oint has to be to a true changepoint to b e classified as correct. Figures for square ro ot increasing and fixed num b ers of changepoints are giv en in the supplemen tary material. As the n umber of c hangep oints decreases a higher prop ortion of true c hangep oints are detected with fewer false changepoints. The supplementary material also contains an exploration of the same prop erties for c hanges in both mean and v ariance. The results are broadly similar to those de- scrib ed ab ov e. W e no w demonstrate increased accuracy of the PEL T algorithm com- pared with BS on an o ceanographic data set; a financial application is giv en in the supplemen tary material. 17 4.2 Application to Canadian W av e Heights There is interest in c haracterising the o cean environmen t, particularly in areas where there are marine structures, e.g. offshore wind farms or oil installations. Short- term op erations, suc h as insp ection and maintenance of these marine structures, are t ypically p erformed in p erio ds where the sea is less v olatile to minimize risk. Here we consider publically av ailable data for a lo cation in the North Atlan tic where data has b een collected on w av e heigh ts at hourly in terv als from Jan uary 2005 until Septem b er 2012, see Figure 4(a). Our interest is in segmenting the series into p e- rio d of lo wer and higher v olatility . The data w e use is obtained from Fisheries and Oceans Canada, East Scotian Slop buoy ID C44137 and has b een repro duced in the changepoint R pack age (Killick and Ec kley, 2010). The cyclic nature of larger w av e heights in the winter and small w av e heigh ts in the summer is clear. How ev er, the transition p oint from p erio ds of higher volatilit y (win ter storms) to low er v olatility (summer calm) is unclear, particularly in some y ears. T o identify these features w e w ork with the first difference data. Consequen tly a natural approach is to use the change in v ariance cost function of Section 4.1. Of course this is but one of sev eral w a ys in whic h the data could b e segmen ted. F or the data we consider (Figure 4(a)) there is quite a difference in the num b er of c hangep oin ts identified b y PEL T (17) and optimal Binary Segmentation (6). Ho w ever, the lo cation of the detected c hangep oints is quite similar. The difference in lik eliho o d b et w een the inferred segmen tations is 3851. PEL T c ho oses a segmentation which, b y-eye, segmen ts the series well in to the different volatilit y regions (Figure 4(b)). Con versely , the segmen tation pro duced by BS do es not (Figure 4(c)); most notably it fails to detect an y transitions b etw een 2008 and 2012. If w e increase the n um b er of c hangep oin ts BS finds to equal that of PEL T, the additional changepoints still fail to capture the regions appropriately . 18 Figure 4: North Atlan tic W av e Heigh ts (a) Original data (b) Differenced data with PEL T c hange- p oin ts (c) Differenced data with optimal BS c hangep oints and additional subBS changepoints (dotted lines). (a) 0 4 8 14 2005 2008 2011 (b) −4 0 4 2005 2008 2011 (c) −4 0 4 2005 2008 2011 4.3 Changes in Auto-cov ariance within Autoregressiv e Data Changes in AR mo dels ha ve b een considered by many authors including Davis et al. (2006), Husk ov a et al. (2007) and Gom ba y (2008). This section describ es a simulation study that compares the prop erties of PEL T and the genetic algorithm used in Davis et al. (2006) to implement the minim um description length (MDL) test statistic. Minimum Description L ength for AR Mo dels The sim ulation study here will b e constructed in a similar w ay to that of Section 4.1. It is assumed that the data follo w an autoregressive mo del with order and parameter v alues dep ending on the segmen t. W e shall take the cost function to be the MDL, and consider allowing AR mo dels of order 1 , . . . , p max , for some c hosen p max within each segmen t. The 19 asso ciated cost for a segmen t is C ( y ( τ i − 1 +1): τ i ) = min p ∈{ 1 ,...,p max } log p + p + 2 2 log( τ i − τ i − 1 ) + τ i − τ i − 1 2 log 2 π ˆ σ ( p, τ i − 1 + 1 , τ i ) 2 . (11) where ˆ σ ( p, τ i − 1 + 1 , τ i ) 2 is the Y ule-W alker estimate of the inno v ation v ariance for data y ( τ i − 1 +1): τ i and order p . When implemen ting PEL T, w e set K = − [2 log ( p max ) + ( p max / 2) log( n )], to ensure that (4) is satisfied. Simulation Study The sim ulated data consists of 5 scenarios with v arying lengths, n = c (1000, 2000, 5000, 10000, 20000) and eac h scenario contains 0 . 003 n c hange- p oin ts. These c hangep oin ts are distributed uniformly across (2 , n − 2) with the con- strain t that there m ust be at least 50 observ ations b etw een c hangep oints. Within eac h of these 5 scenarios w e hav e 200 rep etitions where the segment order is selected randomly from { 0 , 1 , 2 , 3 } and the autoregressive parameters for each segment are a realisation from a standard Normal distribution sub ject to stationarit y conditions. W e compare the output from PEL T with an approximate metho d prop osed by Davis et al. (2006) for minimising the MDL criteria, whic h uses a genetic algorithm. This w as implemen ted in the program Auto-P ARM, made a v ailable by the authors. W e used the recommended settings except that for b oth metho ds w e assumed p max = 7. T able 1 shows the a verage difference in MDL o ver eac h scenario for each fitted mo del. It is clear that on av erage PEL T achiev es a low er MDL than the Auto-P ARM algo- rithm and that this difference increases as the length of the data increases. Overall, for 91% of data sets, PEL T gav e a low er v alue of MDL than Auto-Parm. In addition, the a v erage n umber of iterations required for PEL T to conv erge is small in all cases. Previously , it was noted that the PEL T algorithm for the MDL p enalt y is no longer an exact searc h algorithm. F or n = 1 , 000 w e ev aluated the accuracy of PEL T by calculating the optimal segmen tation in eac h case using Segmen t Neighbourho o d 20 T able 1: Av erage MDL and num b er of PEL T iterations ov er 200 rep etitions. n 1,000 2,000 5,000 10,000 20,000 no. iterations 2.470 2.710 2.885 2.970 3.000 Auto-P ARM - PEL T 8.856 13.918 59.825 252.796 900.869 (SN). The a verage difference in MDL b etw een the SN and PEL T algorithms is 1 . 01 (to 2dp). Ho w ever SN took an order of magnitude longer to run than PEL T, its computational cost increasing with the cub e of the data size making it impracticable for large n . A b etter approac h to improv e on the results of our analysis w ould b e to impro ve the searc h strategy for the v alue of p enalty function to run PEL T with. 5. DISCUSSION In this pap er w e hav e presented the PEL T metho d; an alternative exact m ultiple c hangep oin t metho d that is b oth computationally efficien t and versatile in its appli- cation. It has b een shown that under certain conditions, most importantly that the n umber of changepoints is increasing linearly with n , the computational efficiency of PEL T is O ( n ). The simulation study and real data examples demonstrate that the assumptions and conditions are not restrictive and a wide class of cost functions can b e implemen ted. The empirical results sho w a resulting computational cost for PEL T that can b e orders of magnitude smaller than alternativ e exact searc h metho ds. F ur- thermore, the results show substantial increases in accuracy b y using PEL T compared with Binary Segmentation. Whilst PEL T is not, in practice, computationally quic ker than Binary Segmen tation, w e w ould argue that the statistical b enefits of an exact segmen tation outw eigh the relatively small computational costs. There are other fast algorithms for segemen ting data that impro v e up on Binary Segmentation (Gey and Lebarbier, 2008; Harchaoui and Levy-Leduc, 2010), although these do not ha ve the guaran tee of exactness that PEL T do es. 21 Rigaill (2010) dev elops a comp eting exact metho d called pruned dynamic program- ming (PDP A). This method also aims to impro ve the computational efficiency of an exact method, this time Segmen t Neigh b ourho o d, through pruning, but the w ay pruning is implemen ted is v ery different from PEL T. The metho ds are complemen- tary . Firstly they can b e applied to differen t problems, with PDP A able to cope with a non-linear p enalty functions for the n um b er of changepoints, but restricted to mo dels with a single parameter within each segment. Secondly the applications under whic h they are computationally efficien t is differen t, with PDP A b est suited to applications with few changepoints. Whilst unable to compare PEL T with PDP A on the change in v ariance or the c hange in mean and v ariance mo dels considered in the results section, w e hav e done a comparison b et ween them on a c hange in mean. Results are presen ted in T able 1 of the Supplementary material. Our comparison was for both a linearly increasing num b er of c hangep oin ts, and a fixed n umber of changepoints scenario. F or the former PEL T was substan tially quic ker, by a factors of b etw een 300 and 40,000 as the num b er of data-p oin ts v aried b et ween 500 and 500,000. When w e fixed the n umber of changepoints to 2, PDP A was a factor of 2 quic k er for data with 500,000 c hangep oin ts, though often muc h slo w er for smaller data sets. Co de implementing PEL T is con tained within the R library changepoint which is a v ailable on CRAN (Killic k and Ec kley, 2010). References Aggarw al, R., Inclan, C., and Leal, R. (1999). V olatilit y in emerging sto ck markets. The Journal of Financial and Quantitative Analysis , 34(1):33–55. Ak aik e, H. (1974). A new lo ok at the statistical mo del identification. IEEE T r ansac- tions on Automatic Contr ol , 19(6):716–723. 22 Andreou, E. and Ghysels, E. (2002). Detecting multiple breaks in financial mark et v olatility dynamics. Journal of Applie d Ec onometrics , 17(5). Auger, I. E. and La wrence, C. E. (1989). Algorithms for the optimal identification of segmen t neigh b orho o ds. Bul letin of Mathematic al Biolo gy , 51(1):39–54. Bellman, E. and Dreyfus, S. E. (1962). Applie d Dynamic Pr o gr amming . Princeton. Birge, L. and Massart, P . (2007). Minimal P enalties for Gaussian Mo del Selection. Pr ob ability The ory and R elate d Fields , 138(1):33–73. Braun, J. V., Braun, R. K., and Muller, H. G. (2000). Multiple c hangep oin t fitting via quasilik eliho o d, with application to DNA sequence segmen tation. Biometrika , 87(2):301–314. Chen, J. and Gupta, A. K. (2000). Par ametric statistic al change p oint analysis . Birkhauser. Da vis, R. A., Lee, T. C. M., and Ro driguez-Y am, G. A. (2006). Structural break estimation for nonstationary time series mo dels. JASA , 101(473):223–239. Ec kley , I. A., F earnhead, P ., and Killic k, R. (2011). Analysis of changepoint mo dels. In Barb er, D., Cemgil, T., and Chiappa, S., editors, Bayesian Time Series Mo dels . Cam bridge Univ ersity Press. F ernandez, V. (2004). Detection of breakp oin ts in volatilit y . Estudios de A dministr a- cion , 11(1):1–38. Gey , S. and Lebarbier, E. (2008). Using cart to detect multiple c hange-p oints in the mean for large samples. SSB Pr eprint, No.12 . Gom bay , E. (2008). Change detection in autoregressiv e time series. J. Multivariate A nal. , 99(3):451 – 464. 23 Guy on, X. and Y ao, J.-f. (1999). On the underfitting and o verfitting sets of mo dels c hosen b y order selection criteria. J. Multivariate Anal. , 70(2):221 – 249. Harc haoui, Z. and Levy-Leduc, C. (2010). Multiple c hange-p oint estimation with a total-v ariation p enalt y . JASA , 105(492):1480–1493. Horv ath, L. (1993). The maximum likelihoo d metho d of testing c hanges in the pa- rameters of normal observ ations. A nnals of Statistics , 21(2):671–680. Husk ov a, M., Prask ov a, Z., and Steinebac h, J. (2007). On the detection of changes in autoregressiv e time series. J. Statist. Plann. Infer enc e , 137(4):1243 – 1259. Inclan, C. and Tiao, G. C. (1994). Use of cum ulative sums of squares for retrosp ective detection of changes of v ariance. JASA , 89(427):913–923. Jac kson, B., Sargle, J. D., Barnes, D., Arabhi, S., Alt, A., Gioumousis, P ., Gwin, E., Sangtrakulc haro en, P ., T an, L., and Tsai, T. T. (2005). An algorithm for optimal partitioning of data on an in terv al. IEEE, Signal Pr o c essing L etters , 12(2):105–108. Killic k, R. and Ec kley , I. A. (2010). changep oint: Analysis of Changep oint Mo dels . Lancaster Univ ersit y , Lancaster, UK. Olshen, A. B., V enk atraman, E. S., Lucito, R., and Wigler, M. (2004). Circular binary segmen tation for the analysis of array-based DNA copy num b er data. . Biostatistics , 5:557–72. Picard, F., Lebarbier, E., Ho eb eke, M., Rigaill, G., Thiam, B., and Robin, S. (2011). Join t segmen tation, calling and normalization of m ultiple cgh profiles. Biostatistics , 12(3):413 – 428. Picard, F., Robin, S., La vielle, M., V aisse, C., and Daudin, J. J. (2005). A statistical approac h for arra y cgh data analysis. Bioinformatics , 6(27). 24 Rigaill, G. (2010). Pruned dynamic programming for optimal multiple c hange-p oin t detection. A rXiv e-prints . Sc hw arz, G. (1978). Estimating the dimension of a model. A nn. Statist. , 6(2):461–464. Scott, A. J. and Knott, M. (1974). A cluster analysis metho d for grouping means in the analysis of v ariance. Biometrics , 30(3):507–512. Sen, A. and Sriv asta v a, M. S. (1975). On tests for detecting c hange in mean. The A nnals of Statistics , 3(1):98–108. Y ao, Y. (1984). Estimation of a noisy discrete-time step function: Ba yes and empirical Ba yes approaches. The Annals of Statistics , 12(4):1434–1447. Zhang, N. R. and Siegmund, D. O. (2007). A mo dified bay es information criterion with applications to the analysis of comparativ e genomic h ybridization data. Biometrics , 63(1):22–32. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment