Detecting and Tracking the Spread of Astroturf Memes in Microblog Streams
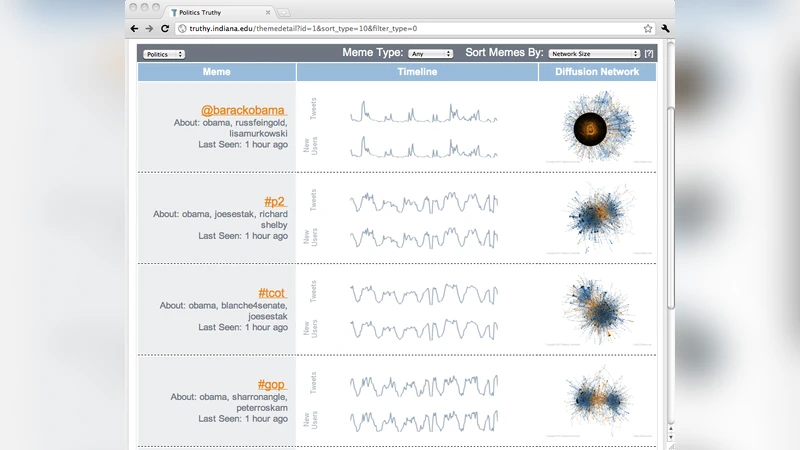
Online social media are complementing and in some cases replacing person-to-person social interaction and redefining the diffusion of information. In particular, microblogs have become crucial grounds on which public relations, marketing, and political battles are fought. We introduce an extensible framework that will enable the real-time analysis of meme diffusion in social media by mining, visualizing, mapping, classifying, and modeling massive streams of public microblogging events. We describe a Web service that leverages this framework to track political memes in Twitter and help detect astroturfing, smear campaigns, and other misinformation in the context of U.S. political elections. We present some cases of abusive behaviors uncovered by our service. Finally, we discuss promising preliminary results on the detection of suspicious memes via supervised learning based on features extracted from the topology of the diffusion networks, sentiment analysis, and crowdsourced annotations.
💡 Research Summary
The paper addresses the growing challenge of misinformation, astroturfing, and smear campaigns that proliferate on micro‑blogging platforms such as Twitter, especially during politically charged periods. To confront this problem, the authors design an extensible, real‑time framework that ingests massive streams of public micro‑blog events, extracts “memes” (hashtags, URLs, or recurring textual patterns), builds dynamic diffusion networks, visualizes propagation, and classifies or models meme behavior.
Data collection relies on the Twitter Streaming API combined with Apache Kafka for high‑throughput buffering and Apache Storm for real‑time filtering. Each incoming tweet is parsed for hashtags, mentions, and URLs; variants are normalized into a single meme identifier (e.g., #VoteForX, #Vote4X). The normalized memes become nodes in a graph stored in Neo4j, where edges capture user‑to‑meme, user‑to‑user, and meme‑to‑meme relationships along with timestamps, retweet type, and reply direction. This graph is continuously updated, enabling the system to compute topological metrics (centrality, community modularity, depth, speed variance) on the fly.
A web‑based dashboard built with D3.js presents an interactive view of meme diffusion: time‑series of tweet volume, identification of key spreaders, and visual clustering of propagation paths. The classification layer operates on two fronts. First, a rule‑based filter flags obvious anomalies such as sudden spikes, identical IP/device activity, or abnormal retweet ratios. Second, a supervised learning model is trained on 1,200 memes that were crowdsourced and labeled into three categories: normal, suspected astroturf, and smear. Feature engineering draws from three domains: (1) network topology (node degree, betweenness, eigenvector centrality, community structure), (2) text sentiment and topic analysis (positive/negative scores, keyword frequencies, LDA topic distributions), and (3) account metadata (followers/following ratio, account age, verification status).
Among several classifiers, XGBoost achieved the best performance with an area under the ROC curve of 0.87 and overall accuracy of 81 %, outperforming Random Forest and SVM especially on the imbalanced dataset. The model runs in near‑real time, issuing alerts when a meme is classified as suspicious and automatically highlighting its diffusion graph and sentiment trajectory on the dashboard.
The framework was deployed during the U.S. election cycle, uncovering several abusive behaviors. A case study of the hashtag #VoteForX showed a rapid surge to 150 k tweets within 48 hours, driven primarily by a network of newly created accounts each with fewer than 200 followers. These accounts followed each other, repeatedly posted near‑identical text templates, and exhibited high betweenness centrality within a tightly knit subgraph. Sentiment analysis revealed an over‑use of positive language, a hallmark of coordinated promotion. Traditional manual monitoring would have missed these patterns, but the combined network‑topology and machine‑learning approach detected them automatically.
The system’s architecture is deliberately modular: each component communicates via RESTful APIs and message queues, allowing straightforward integration of other platforms (Reddit, Instagram, TikTok) and future analytical techniques. The authors acknowledge limitations, including the cost of high‑quality crowd‑sourced labeling and the sensitivity of sentiment tools to language and cultural nuances. Future work will explore multimodal data (images, video), graph neural networks for deeper diffusion pattern learning, and semi‑automated labeling to reduce annotation overhead.
In summary, the paper demonstrates that a real‑time, graph‑centric framework coupled with supervised learning on topological, linguistic, and account‑level features can effectively detect suspicious meme diffusion in large‑scale micro‑blog streams. This capability has immediate relevance for election integrity, public‑policy communication, corporate crisis management, and any domain where the authenticity of online discourse is paramount.