Distributed Storage Codes with Repair-by-Transfer and Non-achievability of Interior Points on the Storage-Bandwidth Tradeoff
Regenerating codes are a class of recently developed codes for distributed storage that, like Reed-Solomon codes, permit data recovery from any subset of k nodes within the n-node network. However, regenerating codes possess in addition, the ability to repair a failed node by connecting to an arbitrary subset of d nodes. It has been shown that for the case of functional-repair, there is a tradeoff between the amount of data stored per node and the bandwidth required to repair a failed node. A special case of functional-repair is exact-repair where the replacement node is required to store data identical to that in the failed node. Exact-repair is of interest as it greatly simplifies system implementation. The first result of the paper is an explicit, exact-repair code for the point on the storage-bandwidth tradeoff corresponding to the minimum possible repair bandwidth, for the case when d=n-1. This code has a particularly simple graphical description and most interestingly, has the ability to carry out exact-repair through mere transfer of data and without any need to perform arithmetic operations. Hence the term repair-by-transfer'. The second result of this paper shows that the interior points on the storage-bandwidth tradeoff cannot be achieved under exact-repair, thus pointing to the existence of a separate tradeoff under exact-repair. Specifically, we identify a set of scenarios, termed helper node pooling’, and show that it is the necessity to satisfy such scenarios that over-constrains the system.
💡 Research Summary
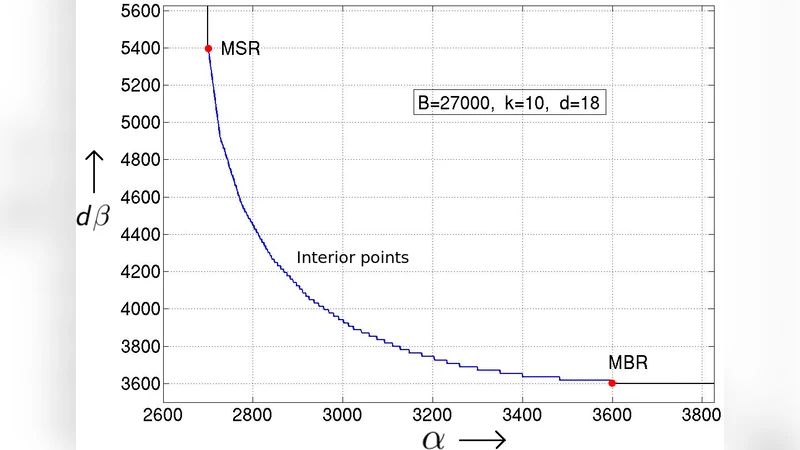
The paper tackles two fundamental issues in the theory of regenerating codes for distributed storage: (1) the construction of an exact‑repair code that achieves the minimum‑bandwidth regeneration (MBR) point when every surviving node participates in the repair (d = n − 1), and (2) the impossibility of attaining interior points of the storage‑bandwidth trade‑off under exact‑repair constraints.
The first contribution is a remarkably simple code that operates by “repair‑by‑transfer.” The authors model the system as an undirected graph whose vertices correspond to storage nodes and whose edges represent the coded symbols stored on pairs of nodes. Each node stores α = 2β symbols, where β is the amount each helper node transmits during a repair. When a node fails, the newcomer simply copies the β symbols from each of its d = n − 1 neighbors—no arithmetic, no decoding, just raw data transfer. The authors prove that this construction meets the MBR point exactly: the per‑node storage α and the total repair bandwidth γ = dβ satisfy the cut‑set bound with equality. Because the repair process requires only data movement, the scheme is extremely attractive for practical systems where CPU cycles, latency, and energy consumption are at a premium.
The second, more theoretical, contribution shows that the interior of the functional‑repair trade‑off curve cannot be achieved when exact‑repair is required. To demonstrate this, the authors introduce the notion of “helper‑node pooling.” In many realistic failure scenarios multiple nodes may fail simultaneously, and the same set of d helpers must serve all ongoing repairs. This creates a coupling among the information sent by each helper: the data contributed to one repair cannot be independent of the data contributed to another, because the helpers are forced to reuse the same stored symbols. By representing the flow of information with entropy inequalities on a directed information graph, the authors derive additional linear constraints on α and β that are not present in the functional‑repair analysis. They prove that for any interior point (i.e., any point strictly between the MBR and the minimum‑storage regeneration (MSR) extremes) these constraints are contradictory, implying that no exact‑repair code can meet the functional‑repair bound there. Consequently, the exact‑repair trade‑off collapses to a piecewise curve that only includes the two extreme points and possibly a narrow region near them.
The paper situates its results within the broader literature. Prior exact‑repair constructions existed only for special parameter sets (e.g., (n,k,d) = (4,2,3)) and often required sophisticated linear network coding. The graph‑based MBR construction presented here is the first to achieve the MBR point for arbitrary n with d = n − 1 using only symbol transfer. The impossibility proof, on the other hand, clarifies why extending such constructions to interior points has been fruitless: the helper‑node pooling requirement fundamentally over‑constrains the system.
From an engineering perspective, the work suggests two practical design guidelines. First, if a system can tolerate the storage overhead of the MBR point, the repair‑by‑transfer code offers a low‑complexity, low‑latency solution that eliminates the need for on‑the‑fly encoding. Second, when designers aim for storage efficiency close to the MSR point, they must accept that exact‑repair will force a higher repair bandwidth than the functional‑repair bound predicts, unless they redesign the failure model (e.g., by limiting simultaneous failures or by dynamically selecting disjoint helper sets).
In summary, the paper delivers a constructive exact‑repair code that achieves the optimal bandwidth with a trivial repair operation, and it rigorously proves that exact‑repair imposes a stricter storage‑bandwidth trade‑off than functional‑repair. The introduction of helper‑node pooling as a fundamental limiting factor deepens our understanding of the inherent tension between storage efficiency and repair cost in distributed storage systems, and it charts a clear path for future research on exact‑repair code design, helper selection strategies, and system‑level fault‑tolerance mechanisms.