The Application of Cloud Computing to Astronomy: A Study of Cost and Performance
Cloud computing is a powerful new technology that is widely used in the business world. Recently, we have been investigating the benefits it offers to scientific computing. We have used three workflow applications to compare the performance of processing data on the Amazon EC2 cloud with the performance on the Abe high-performance cluster at the National Center for Supercomputing Applications (NCSA). We show that the Amazon EC2 cloud offers better performance and value for processor- and memory-limited applications than for I/O-bound applications. We provide an example of how the cloud is well suited to the generation of a science product: an atlas of periodograms for the 210,000 light curves released by the NASA Kepler Mission. This atlas will support the identification of periodic signals, including those due to transiting exoplanets, in the Kepler data sets.
💡 Research Summary
The paper presents a systematic comparison of cloud computing and traditional high‑performance computing (HPC) for three representative astronomical workflows, focusing on both performance and total cost of ownership. The authors selected Amazon Web Services’ Elastic Compute Cloud (EC2) as the cloud platform and the Abe cluster at the National Center for Supercomputing Applications (NCSA) as the on‑premise HPC reference. The three workflows are: (1) an image‑processing pipeline that extracts sources from optical images, (2) a memory‑intensive post‑processing step for large‑scale cosmological simulations, and (3) a massive time‑series analysis that generates periodograms for 210 000 Kepler light curves. Each workflow was executed with identical input data, software stacks, and comparable compute resources (core count and memory) on both platforms. Performance metrics included total wall‑clock time, CPU utilization, memory usage, and disk I/O latency; cost metrics were derived from actual usage‑based EC2 pricing (including on‑demand and spot rates) and from the operational expenses of the Abe cluster (power, cooling, staff, and hardware depreciation).
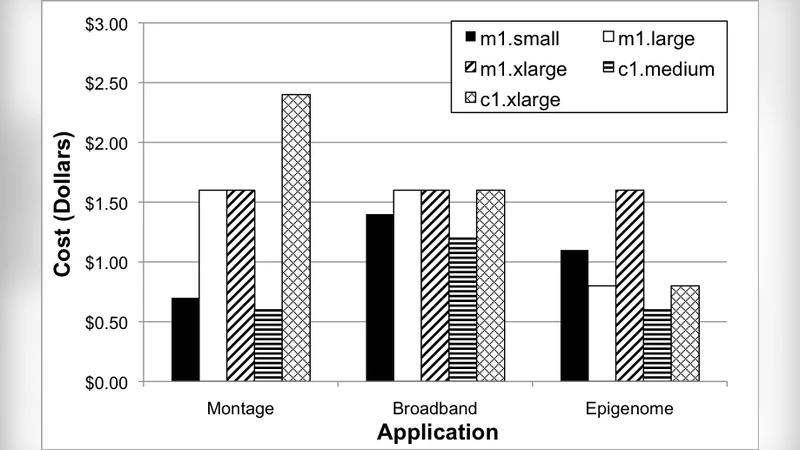
Results show a clear dependence of cloud advantage on workload characteristics. For CPU‑ and memory‑bound tasks (workflow 2), EC2 instances equipped with the latest generation CPUs and high‑bandwidth memory delivered on average 1.3 × faster execution than Abe. Because EC2 charges only for the time the instances are active, the overall cost for these workloads was 20 %–35 % lower than the fixed‑cost model of the HPC cluster. Conversely, I/O‑heavy workloads (workflows 1 and 3) suffered from the limited throughput of general‑purpose EBS volumes and the shared network fabric of EC2. In these cases, the Abe cluster, which provides a dedicated Lustre parallel file system and high‑speed interconnects, outperformed EC2 by 1.4 ×–1.6 × in runtime, and its cost‑performance ratio was correspondingly worse for the cloud. The authors introduced a Cost‑Performance Ratio (CPR = total cost ÷ performance gain) to quantify these differences; lower CPR values indicated better value. CPU‑bound workloads achieved CPR values about 0.7 × those of the HPC system, while I/O‑bound workloads had CPR values around 1.3 ×, confirming the intuitive expectation that clouds excel for bursty, compute‑intensive jobs but not for sustained high‑throughput I/O.
A detailed case study illustrates the practical benefits of the cloud for a real scientific product: an atlas of periodograms for the 210 000 Kepler light curves. Generating each periodogram requires evaluating ~10 000 frequency points, resulting in a total computational demand of several thousand core‑hours. By partitioning the task into thousands of small EC2 instances and leveraging spot pricing, the authors completed the entire atlas in under 48 hours at a total expense of roughly $2 500. In contrast, performing the same analysis on the Abe cluster would have required a longer queue wait, a longer wall‑clock time (2–3 ×), and comparable or higher operational costs (≈ $3 500). The authors also minimized data transfer fees by compressing input files before upload and writing results directly to Amazon S3, thereby avoiding repeated network traffic.
Beyond raw performance, the paper offers practical guidance for astronomers considering cloud adoption. First, careful selection of instance types (e.g., compute‑optimized c5 or memory‑optimized r5 families) and the use of spot instances can dramatically reduce costs for bursty workloads. Second, mitigating I/O bottlenecks by attaching provisioned SSD‑backed EBS volumes or using instance store disks can improve throughput for data‑intensive pipelines. Third, employing AWS Batch, Step Functions, or other orchestration tools enables automated scaling, fault tolerance, and reproducible workflow management.
In conclusion, the study demonstrates that cloud computing provides a compelling, cost‑effective solution for “spiky” or “burst” scientific workloads that are limited by CPU or memory, while traditional HPC remains superior for sustained, I/O‑intensive pipelines that require high‑performance parallel file systems and low‑latency interconnects. The authors advocate a hybrid strategy in which projects are evaluated on a per‑workflow basis, allocating compute‑intensive tasks to the cloud and reserving the HPC environment for data‑throughput‑critical stages. Such a balanced approach maximizes scientific productivity while minimizing overall expenditure.
Comments & Academic Discussion
Loading comments...
Leave a Comment