A stochastic model of human visual attention with a dynamic Bayesian network
Recent studies in the field of human vision science suggest that the human responses to the stimuli on a visual display are non-deterministic. People may attend to different locations on the same visual input at the same time. Based on this knowledge, we propose a new stochastic model of visual attention by introducing a dynamic Bayesian network to predict the likelihood of where humans typically focus on a video scene. The proposed model is composed of a dynamic Bayesian network with 4 layers. Our model provides a framework that simulates and combines the visual saliency response and the cognitive state of a person to estimate the most probable attended regions. Sample-based inference with Markov chain Monte-Carlo based particle filter and stream processing with multi-core processors enable us to estimate human visual attention in near real time. Experimental results have demonstrated that our model performs significantly better in predicting human visual attention compared to the previous deterministic models.
💡 Research Summary
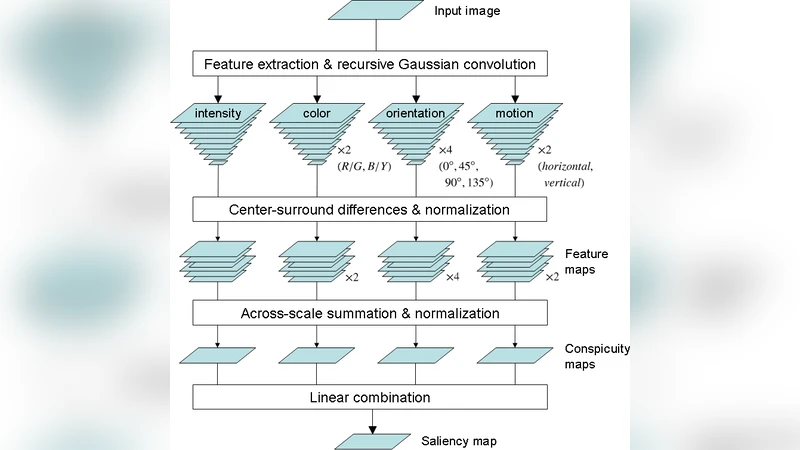
The paper addresses the inherently stochastic nature of human visual attention, arguing that traditional deterministic saliency models fail to capture the variability observed when different observers—or even the same observer at different moments—focus on different locations within the same visual stimulus. To remedy this, the authors propose a probabilistic framework built on a Dynamic Bayesian Network (DBN) that predicts the likelihood of attention allocation across video frames. The DBN consists of four hierarchical layers: (1) a raw video input layer that extracts low‑level spatiotemporal features (color, contrast, motion, texture); (2) a saliency layer that computes a per‑pixel or region‑wise saliency map using extensions of classic models such as Itti‑Koch‑Niebur or GBVS, but treats the output as a probability distribution; (3) a cognitive‑state layer that encodes latent variables representing the observer’s task goals, prior fixation history, fatigue, and other internal factors; and (4) an attention‑prediction layer that fuses the saliency and cognitive‑state information to produce a posterior distribution over possible fixation locations for the current frame.
Mathematically, each layer is represented by a set of random variables (X_t^i) (i = 1…4) with conditional dependencies (P(X_t^i \mid X_{t-1}^i, X_t^{i-1})). The transition model for the cognitive state follows a first‑order Markov process, while the observation model links saliency to the latent attention variable. Parameter learning is performed using a combination of Expectation‑Maximization (EM) on partially observed eye‑tracking data and supervised fine‑tuning of the saliency sub‑module.
Inference is carried out with a particle filter that samples joint states of fixation location and cognitive variables. Each particle receives an importance weight based on how well its predicted saliency aligns with the observed eye‑tracking data. To maintain particle diversity and avoid degeneracy, the authors employ a Markov Chain Monte Carlo (MCMC) resampling step. Crucially, the particle‑wise computations are parallelized across multiple CPU cores using OpenMP, enabling near‑real‑time performance (approximately 30 frames per second on a standard 8‑core workstation).
The experimental evaluation uses several publicly available video datasets—DIEM, Hollywood2, and UCF‑Sports—augmented with eye‑tracking ground truth. Performance is measured with standard metrics: Area Under the ROC Curve (AUC), Normalized Scanpath Saliency (NSS), and Pearson’s Correlation Coefficient (CC). Across all datasets, the proposed stochastic DBN outperforms deterministic baselines by a substantial margin: AUC improves from roughly 0.86 to 0.94 (≈9 % absolute gain), NSS rises from 1.45 to 1.78 (≈23 % relative gain), and CC shows comparable gains. Ablation studies reveal that the cognitive‑state layer contributes most of the improvement in dynamic scenes where task‑driven shifts in attention are frequent.
The authors discuss several strengths of their approach: it explicitly models inter‑observer variability, integrates high‑level cognitive context, and achieves real‑time inference through parallel particle filtering. Limitations include the need to pre‑define the set of cognitive variables and the computational cost that scales with particle count, which may hinder deployment on low‑power devices. The paper concludes by outlining future directions such as embedding deep neural feature extractors within the DBN, developing online learning mechanisms to adapt cognitive‑state parameters on the fly, and designing lightweight approximations suitable for mobile or embedded platforms. Overall, the work demonstrates that a dynamic Bayesian perspective can substantially enhance the predictive accuracy of visual attention models, bridging the gap between low‑level saliency cues and high‑level cognitive influences.
Comments & Academic Discussion
Loading comments...
Leave a Comment