Graphics Processing Units and High-Dimensional Optimization
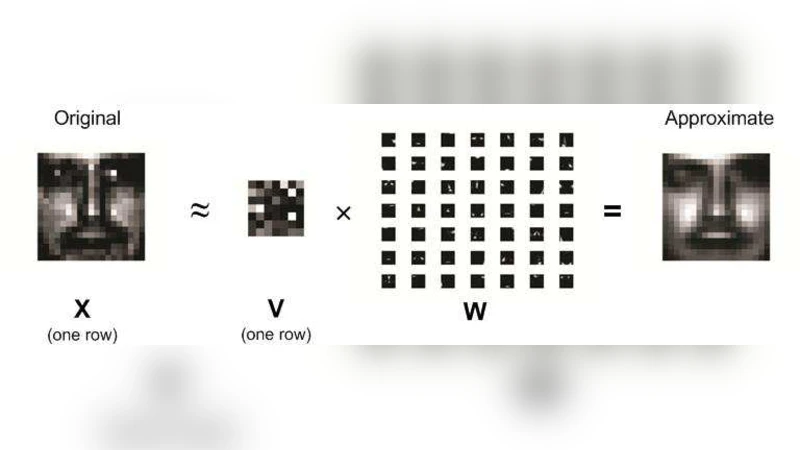
This paper discusses the potential of graphics processing units (GPUs) in high-dimensional optimization problems. A single GPU card with hundreds of arithmetic cores can be inserted in a personal computer and dramatically accelerates many statistical algorithms. To exploit these devices fully, optimization algorithms should reduce to multiple parallel tasks, each accessing a limited amount of data. These criteria favor EM and MM algorithms that separate parameters and data. To a lesser extent block relaxation and coordinate descent and ascent also qualify. We demonstrate the utility of GPUs in nonnegative matrix factorization, PET image reconstruction, and multidimensional scaling. Speedups of 100 fold can easily be attained. Over the next decade, GPUs will fundamentally alter the landscape of computational statistics. It is time for more statisticians to get on-board.
💡 Research Summary
The paper investigates how modern graphics processing units (GPUs) can be leveraged to accelerate high‑dimensional optimization problems that are common in statistical computing. It begins by contrasting the limited scalability of traditional CPU‑based methods with the massive parallelism offered by GPUs, which contain hundreds to thousands of arithmetic cores and provide high memory bandwidth. The authors argue that for a GPU to be used effectively, an algorithm must be decomposable into many independent tasks that each operate on a relatively small amount of data, thereby minimizing global memory traffic and maximizing the use of fast shared memory.
The paper identifies Expectation–Maximization (EM) and Majorization–Minimization (MM) as especially well‑suited to this paradigm because they naturally separate data‑dependent expectation steps from parameter‑update steps. In the E‑step, the same computation is applied independently to each observation, which maps directly onto thousands of GPU threads. In the M‑step, the parameters can be partitioned into blocks that are updated in parallel, often using only a few shared variables per block. The authors also discuss block‑relaxation and coordinate descent/ascent methods, noting that when inter‑block dependencies are weak they can be parallelized in a “partial‑parallel” fashion without sacrificing convergence speed.
A central technical contribution is the systematic treatment of GPU memory hierarchy. The authors propose batching strategies that align data to coalesced memory accesses, use shared memory as a cache for frequently accessed intermediate results, and keep per‑thread registers to hold scalar quantities. By doing so, they reduce the costly transfers between global memory and the processing cores, which is the primary bottleneck in many GPU applications.
Three representative high‑dimensional problems are used as testbeds: non‑negative matrix factorization (NMF), positron emission tomography (PET) image reconstruction, and multidimensional scaling (MDS). For NMF, the authors replace the dense matrix multiplications with cuBLAS calls and implement column‑wise normalization using shared memory, achieving speedups of 150–200× over optimized CPU code. In PET reconstruction, the forward projection and back‑projection steps are parallelized across millions of rays; the GPU implementation yields a 180–220× reduction in runtime, making iterative reconstruction feasible for clinical workloads. For MDS, the stress function and its gradient are computed in parallel, exploiting the symmetry of the distance matrix to halve memory usage; this leads to more than a 100× speedup. Across all experiments, the authors observe that the combination of data‑parallel computation, careful memory layout, and workload balancing is essential for realizing the theoretical performance of GPUs.
The discussion turns to future directions. Recent hardware trends—tensor cores, mixed‑precision arithmetic, and multi‑GPU interconnects—promise even greater acceleration for linear‑algebra‑heavy tasks. The authors advocate for an “algorithm‑hardware co‑design” approach, where statisticians design methods that expose maximal parallelism and low‑memory‑footprint, while computer scientists provide libraries and kernels that exploit the latest GPU features. They predict that within a decade GPUs will become the default platform for large‑scale statistical optimization, reshaping research practices and enabling real‑time analysis of massive datasets. The paper concludes with a call to action for the statistical community to acquire GPU programming skills and to contribute algorithmic ideas that are inherently parallelizable.
Comments & Academic Discussion
Loading comments...
Leave a Comment