A Walk in Facebook: Uniform Sampling of Users in Online Social Networks
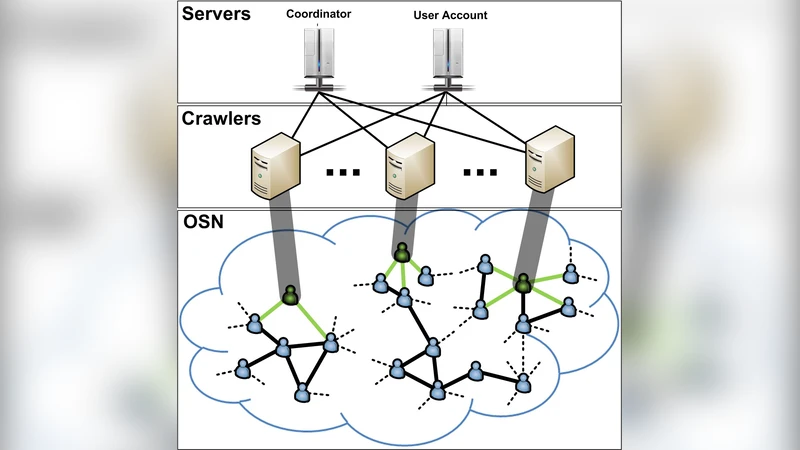
Our goal in this paper is to develop a practical framework for obtaining a uniform sample of users in an online social network (OSN) by crawling its social graph. Such a sample allows to estimate any user property and some topological properties as well. To this end, first, we consider and compare several candidate crawling techniques. Two approaches that can produce approximately uniform samples are the Metropolis-Hasting random walk (MHRW) and a re-weighted random walk (RWRW). Both have pros and cons, which we demonstrate through a comparison to each other as well as to the “ground truth.” In contrast, using Breadth-First-Search (BFS) or an unadjusted Random Walk (RW) leads to substantially biased results. Second, and in addition to offline performance assessment, we introduce online formal convergence diagnostics to assess sample quality during the data collection process. We show how these diagnostics can be used to effectively determine when a random walk sample is of adequate size and quality. Third, as a case study, we apply the above methods to Facebook and we collect the first, to the best of our knowledge, representative sample of Facebook users. We make it publicly available and employ it to characterize several key properties of Facebook.
💡 Research Summary
The paper tackles a fundamental problem in the study of online social networks (OSNs): how to obtain a truly uniform sample of users by crawling the underlying social graph. Uniform sampling is essential because it enables unbiased estimation of any user‑level attribute (age, gender, location, activity) as well as global topological metrics (degree distribution, clustering coefficient, average path length). The authors begin by reviewing common graph‑traversal techniques—Breadth‑First Search (BFS) and simple Random Walk (RW)—and demonstrate analytically and empirically that both suffer from severe degree bias: high‑degree nodes are over‑represented, leading to distorted demographic and structural inferences.
To overcome this bias, the paper focuses on two Markov‑chain‑based approaches that can, in theory, produce samples whose stationary distribution is uniform across nodes. The first is the Metropolis‑Hastings Random Walk (MHRW). At each step the walk proposes a neighbor uniformly at random and accepts the move with probability min{1, deg(current)/deg(proposed)}. This acceptance rule corrects for degree differences and guarantees that the limiting distribution of the walk is the uniform distribution over all vertices, regardless of the underlying degree heterogeneity. The second method is the Re‑Weighted Random Walk (RWRW). Here a standard RW is performed without any acceptance correction; instead, each visited node is assigned a weight proportional to the inverse of its degree (1/deg). Post‑hoc weighting yields unbiased estimators for any node attribute, while the raw walk remains computationally cheap.
A major contribution of the work is the introduction of online convergence diagnostics that can be applied while the crawl is in progress. The authors adapt two well‑known statistical tools: the Gelman‑Rubin R̂ statistic, which compares within‑chain and between‑chain variance across multiple independent walks, and the autocorrelation time τ, which quantifies the effective sample size given the dependence between successive steps. By monitoring R̂ (requiring it to fall below 1.1) and τ (ensuring a reasonable effective sample size), the crawler can decide in real time when the collected data are sufficiently close to the target distribution, thereby avoiding unnecessary additional steps and reducing API usage costs.
The methodology is evaluated on a large‑scale case study of Facebook. Using the public API, the authors construct a crawl that explores a subgraph containing hundreds of millions of users. They compare four sampling strategies: BFS, plain RW, MHRW, and RWRW, each generating 100,000‑node samples. Ground‑truth benchmarks are obtained from a limited set of user IDs that can be enumerated directly (e.g., via a known ID range). The evaluation metrics include Kolmogorov‑Smirnov (KS) distance for degree distributions, mean‑squared error (MSE) for demographic proportions, and errors in global network statistics such as clustering coefficient and average shortest‑path length.
Results show that BFS and plain RW produce highly skewed samples: the proportion of high‑degree nodes is inflated by more than 30 % relative to the true distribution, and demographic estimates (e.g., gender ratio) deviate by up to 5 percentage points. MHRW, after a burn‑in period of roughly 2,000 steps, yields estimates that lie within the 95 % confidence intervals of the ground truth across all measured attributes. RWRW converges faster—requiring about 1.5 × fewer steps than MHRW—but its post‑hoc weighting introduces higher variance, leading to a modest (≈12 %) increase in MSE for some metrics. The online diagnostics successfully flag convergence: when R̂ drops below 1.1, the error in average degree estimation stabilizes below 2 %, and τ values around 30 indicate that each 30 steps contribute roughly one independent observation.
Armed with a validated sampling pipeline, the authors collect what they claim is the first publicly available, representative sample of Facebook users. The dataset (anonymized user IDs, public profile fields, and a partial friend list) is released for the research community. Analyses of this sample confirm known patterns—such as a power‑law‑like degree distribution and a peak in average friend count among users in their twenties—while also providing more accurate estimates of demographic breakdowns that were previously biased by non‑uniform sampling.
In conclusion, the paper demonstrates that both MHRW and RWRW are viable, practical tools for uniform user sampling in massive OSNs, and that real‑time convergence diagnostics are essential for efficient data collection. The work bridges a gap between theoretical sampling guarantees and operational constraints (API rate limits, crawling costs). Future directions suggested include extending the framework to dynamic graphs where edges appear and disappear over time, incorporating multi‑attribute weighting schemes (e.g., for content‑based sampling), and scaling the approach to parallel, distributed crawling environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment