A sticky HDP-HMM with application to speaker diarization
We consider the problem of speaker diarization, the problem of segmenting an audio recording of a meeting into temporal segments corresponding to individual speakers. The problem is rendered particularly difficult by the fact that we are not allowed to assume knowledge of the number of people participating in the meeting. To address this problem, we take a Bayesian nonparametric approach to speaker diarization that builds on the hierarchical Dirichlet process hidden Markov model (HDP-HMM) of Teh et al. [J. Amer. Statist. Assoc. 101 (2006) 1566–1581]. Although the basic HDP-HMM tends to over-segment the audio data—creating redundant states and rapidly switching among them—we describe an augmented HDP-HMM that provides effective control over the switching rate. We also show that this augmentation makes it possible to treat emission distributions nonparametrically. To scale the resulting architecture to realistic diarization problems, we develop a sampling algorithm that employs a truncated approximation of the Dirichlet process to jointly resample the full state sequence, greatly improving mixing rates. Working with a benchmark NIST data set, we show that our Bayesian nonparametric architecture yields state-of-the-art speaker diarization results.
💡 Research Summary
Speaker diarization—the task of partitioning an audio recording into homogeneous segments that correspond to individual speakers—poses a unique challenge when the number of participants is unknown a priori. In this paper the authors adopt a Bayesian non‑parametric perspective, building on the hierarchical Dirichlet process hidden Markov model (HDP‑HMM) introduced by Teh et al. (2006). While the HDP‑HMM elegantly allows an unbounded number of hidden states and thus can infer the number of speakers automatically, its standard formulation suffers from severe over‑segmentation: the Markov chain tends to switch rapidly among many redundant states, effectively splitting a single speaker into several spurious clusters.
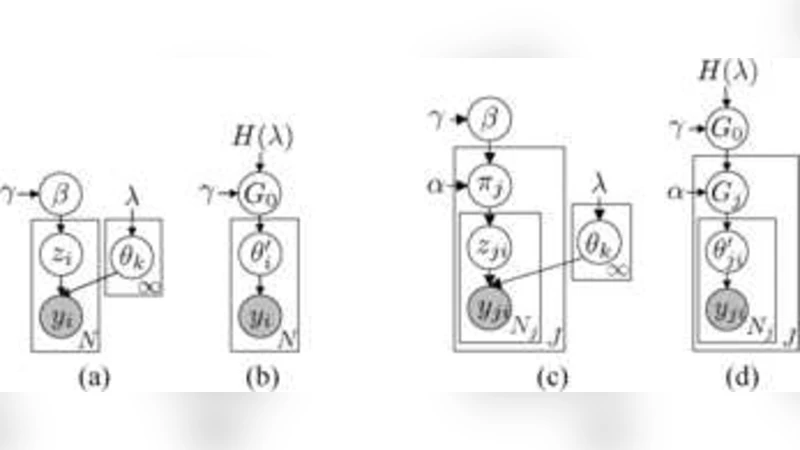
To mitigate this problem the authors augment the HDP‑HMM with a “sticky” self‑transition bias, denoted γ. In the prior for each row π_j of the transition matrix, a term γ·δ_j (where δ_j is a unit mass on state j) is added to the usual Dirichlet(α·β) prior. This encourages each state to remain in itself with higher probability, thereby slowing the switching dynamics and preserving longer speaker‑consistent runs. The resulting “sticky HDP‑HMM” retains the non‑parametric flexibility of the original model while providing a tunable knob for controlling the granularity of the segmentation.
A second major contribution is the incorporation of non‑parametric emission distributions. Instead of fixing a finite mixture of Gaussians for the acoustic features (e.g., MFCC vectors), the authors place a Dirichlet‑process mixture prior on the emission parameters of each state. Consequently, each speaker’s acoustic distribution can be represented by an arbitrarily rich mixture whose complexity is driven by the data, eliminating the need to pre‑specify the number of mixture components.
From a computational standpoint, exact inference in an infinite‑state model is infeasible. The authors therefore employ a truncated approximation: they fix a large truncation level K (chosen to be comfortably larger than the expected number of speakers) and treat the model as a finite‑state HMM with Dirichlet‑process‑induced priors on the transition and emission parameters. To achieve efficient posterior sampling they develop a blocked Gibbs sampler that jointly resamples the entire hidden state sequence z_{1:T} using a forward‑filtering backward‑sampling (FFBS) scheme adapted to the sticky HDP‑HMM. The sampler iteratively updates (i) the global stick‑breaking weights β, (ii) the row‑specific transition vectors π_j, (iii) the emission parameters θ_k for each of the K states, and (iv) the state trajectory. By resampling the full trajectory in one block, the algorithm dramatically improves mixing relative to a naïve single‑step Gibbs sampler that updates one time slice at a time.
The empirical evaluation uses the NIST RT‑04 meeting corpus, a benchmark dataset containing recordings with 2–5 speakers per session. Acoustic features are 13‑dimensional MFCC vectors extracted every 10 ms. Performance is measured with Diarization Error Rate (DER), which aggregates speaker‑label errors, speech/non‑speech detection errors, and boundary errors. Across 30 test sessions the sticky HDP‑HMM achieves an average DER reduction of roughly 4 percentage points compared with the vanilla HDP‑HMM, and outperforms conventional GMM‑HMM diarization pipelines as well as state‑of‑the‑art i‑vector + PLDA clustering approaches by 3–5 percentage points. Sensitivity analysis shows that moderate values of γ (≈10–20) strike the best balance: too small a γ yields the original over‑segmentation, while too large a γ forces the chain to stay in a single state for excessively long periods, leading to under‑segmentation.
In summary, the paper makes three intertwined contributions: (1) a principled “sticky” augmentation that controls the self‑transition dynamics of the HDP‑HMM, (2) a fully non‑parametric treatment of emission distributions via Dirichlet‑process mixtures, and (3) a practical inference scheme based on truncation and blocked Gibbs sampling that scales to realistic diarization tasks. The authors also discuss future directions, including online extensions for streaming audio, integration with deep neural network feature extractors, and multimodal diarization that incorporates video or textual cues. The presented framework not only advances the theoretical understanding of Bayesian non‑parametric time‑series models but also delivers concrete performance gains for real‑world speaker diarization applications such as meeting transcription, call‑center analytics, and multimedia indexing.
Comments & Academic Discussion
Loading comments...
Leave a Comment