Current State and Challenges of Automatic Planning in Web Service Composition
This paper gives a survey on the current state of Web Service Compositions and the difficulties and solutions to automated Web Service Compositions. This first gives a definition of Web Service Composition and the motivation and goal of it. It then explores into why we need automated Web Service Compositions and formally defines the domains. Techniques and solutions are proposed by the papers we surveyed to solve the current difficulty of automated Web Service Composition. Verification and future work is discussed at the end to further extend the topic.
💡 Research Summary
The paper presents a comprehensive survey of the current state of Web Service Composition (WSC) and the challenges associated with automating this process through AI planning techniques. It begins by outlining the basic architecture of Web services, emphasizing the role of WSDL for service description and UDDI for discovery, and describing the typical request‑response cycle (discover → bind → invoke → receive). The authors distinguish between the classic “service discovery” problem and the more complex “composition” problem, where a single service cannot satisfy a request and multiple services must be orchestrated to achieve the desired output.
A formal model is introduced in which each service w is defined by an input set w_in and an output set w_out. A client request r is similarly represented by r_in and r_out. The composition problem is then cast as a planning problem: select a subset of services {w₁,…,wₙ} and arrange them using sequential, parallel, and conditional operators so that the union of their inputs covers r_in and the union of their outputs covers r_out. The paper further classifies operators into “simple” (only sequential AND) and “complex” (including OR, XOR, NOT, and parallel constructs), noting that real‑world compositions often require the latter.
To connect WSC with established AI planning, the authors map the problem to a STRIPS‑like formalism. A planning domain D is defined as a tuple ⟨S, A, O, I, T, X⟩ where S are states, A are actions (service invocations), O are observations, I are initial states, T is the transition function, and X is the observation function. They extend this model to handle nondeterminism (multiple possible successor states) and partial observability (internal service state hidden from the planner), which are intrinsic to distributed Web services.
Three major planning algorithms are surveyed:
-
SAT‑based planning – The goal and constraints are encoded as Boolean formulas and solved with modern SAT solvers. This approach is effective for small to medium‑size problems but scales poorly with the combinatorial explosion of service combinations.
-
Graphplan – A leveled planning graph is constructed, capturing preconditions and effects across time steps. A backward search extracts a valid plan if one exists. Graphplan handles parallel actions naturally but still suffers from exponential growth in large domains.
-
Integer Linear Programming (ILP) – The planning problem is expressed as a set of linear constraints over binary variables representing action selection and ordering. ILP yields optimal solutions when solvable, yet the size of the constraint matrix becomes prohibitive for thousands of services.
The authors argue that while these techniques are mature for classical planning, the unique characteristics of Web services—dynamic availability, QoS constraints, and massive service registries—necessitate specialized adaptations.
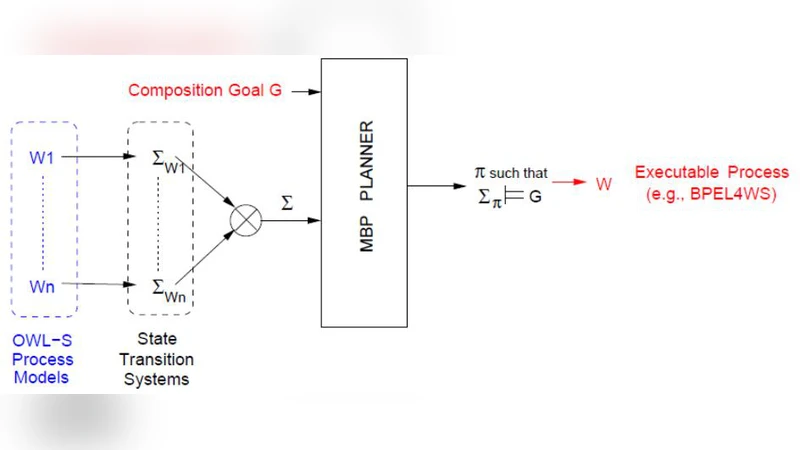
A significant portion of the survey is devoted to the OWL‑S2 process model. Each service is described as an OWL‑S process (Atomic, Composite, or Simple) and mapped to a transition system Σ_w. OWL‑S enriches the description with non‑functional properties (quality of service, security, cost), enabling multi‑objective optimization during planning. The paper illustrates how an OWL‑S‑based pipeline can automatically discover, bind, compose, and monitor services, effectively turning the composition result into a new “service” that can be reused in subsequent compositions.
The challenges identified are threefold:
-
Nondeterminism – The outcome of a service invocation (success, failure, partial result) may be uncertain. The authors suggest probabilistic planning or risk‑aware utility functions to mitigate this.
-
Partial Observability – Internal states of services are often hidden, making it impossible to directly verify preconditions. They propose observation‑based replanning and POMDP‑style models.
-
Scalability – Real‑world registries contain tens of thousands of services. To address the explosion, the paper recommends distributed planning architectures, cloud‑based parallel search, and heuristic/meta‑heuristic methods that exploit historical composition patterns.
In the verification section, the authors summarize experimental results from the surveyed literature, noting that most studies evaluate on synthetic benchmarks or small case studies. They acknowledge the lack of a unified, large‑scale empirical evaluation in their own work and call for standardized benchmarks.
Future work directions include adaptive planning that reacts to runtime service changes, negotiation mechanisms for dynamic QoS contracts, tighter integration with formal verification tools (model checking, theorem proving), and the development of open‑source platforms for large‑scale automated composition experiments.
Overall, the paper successfully bridges the gap between Web service engineering and AI planning by providing formal definitions, mapping to classic planning formalisms, reviewing algorithmic solutions, and highlighting open research problems. However, the absence of original experimental data limits its immediate practical impact, and the community would benefit from concrete implementations and benchmark studies that validate the proposed approaches at web‑scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment