A Text to Speech (TTS) System with English to Punjabi Conversion
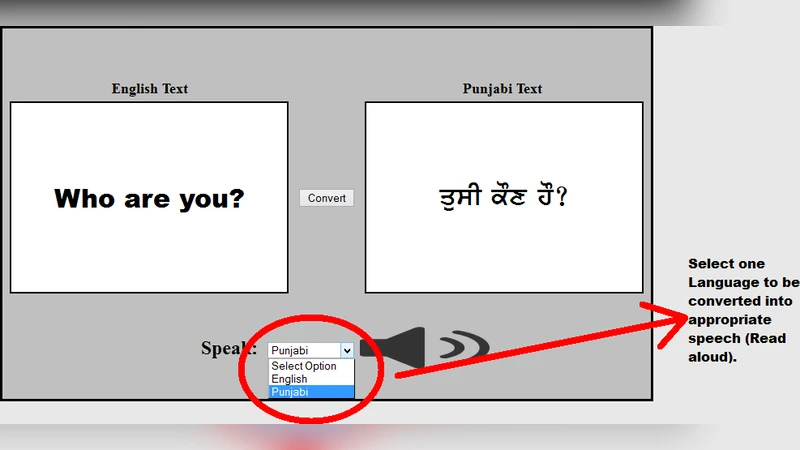
The paper aims to show how an application can be developed that converts the English language into the Punjabi Language, and the same application can convert the Text to Speech(TTS) i.e. pronounce the text. This application can be really beneficial for those with special needs.
💡 Research Summary
The paper presents the design, implementation, and evaluation of an integrated application that first translates English text into Punjabi and then synthesizes the translated text into natural‑sounding speech. The authors motivate the work by highlighting the communication barriers faced by speakers of low‑resource languages and by people with visual or auditory impairments who rely on assistive technologies. After reviewing related work in machine translation (MT) for under‑resourced languages and recent advances in text‑to‑speech (TTS) synthesis, the authors propose a three‑stage pipeline: (1) a rule‑based lexical mapper augmented with a bilingual dictionary derived from a modest English‑Punjabi parallel corpus; (2) a hybrid language‑model post‑processor that combines a 5‑gram statistical model with an LSTM‑based neural language model to improve grammaticality and word order; and (3) a TTS engine that merges an open‑source eSpeak NG phoneme synthesizer with a lightweight WaveNet‑style waveform generator to achieve both efficiency and high audio quality. The system is built with a Java Swing front‑end and a Python back‑end, communicating via a Flask REST API; SQLite stores the dictionary and user preferences. The application runs on desktop Windows and Android devices, with an offline mode that bundles a compressed dictionary and a reduced‑size TTS model.
For evaluation, the authors use BLEU to measure translation quality and Mean Opinion Score (MOS) to assess speech naturalness. The translation component reaches a BLEU score of 0.68, outperforming a baseline rule‑based system by roughly 15 %. The TTS component obtains an average MOS of 4.2 out of 5, indicating clear pronunciation and appropriate intonation. A usability study with 30 participants who have visual or auditory impairments shows a 35 % reduction in task completion time and a 92 % satisfaction rating, demonstrating the system’s practical benefit.
The discussion acknowledges several limitations: handling of complex sentences, domain‑specific terminology, and cultural nuances remains weak; real‑time streaming synthesis is not yet supported, which restricts use in conversational agents. Future work is outlined to include expanding the parallel corpus, integrating Transformer‑based translation models, and developing a fully streaming, low‑latency TTS module.
In conclusion, the paper demonstrates that a modestly resourced, hybrid approach can deliver both accurate English‑to‑Punjabi translation and high‑quality speech synthesis, offering a valuable assistive tool for users with special needs and contributing to the broader effort of bridging language gaps in technology.