Multifractal analysis of sentence lengths in English literary texts
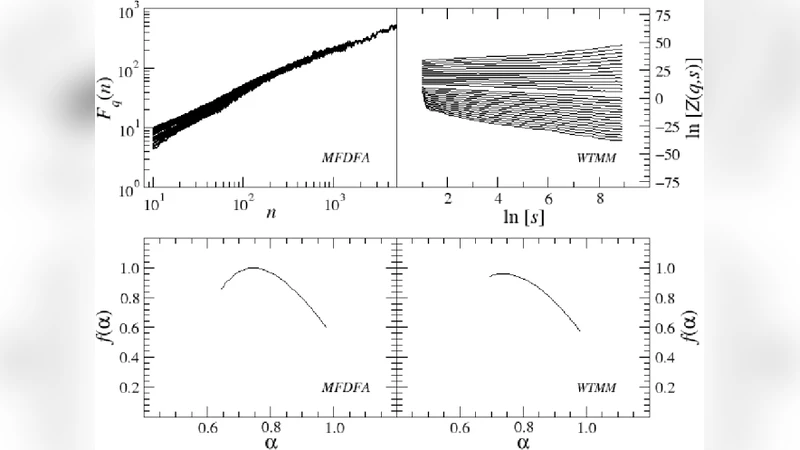
This paper presents analysis of 30 literary texts written in English by different authors. For each text, there were created time series representing length of sentences in words and analyzed its fractal properties using two methods of multifractal analysis: MFDFA and WTMM. Both methods showed that there are texts which can be considered multifractal in this representation but a majority of texts are not multifractal or even not fractal at all. Out of 30 books, only a few have so-correlated lengths of consecutive sentences that the analyzed signals can be interpreted as real multifractals. An interesting direction for future investigations would be identifying what are the specific features which cause certain texts to be multifractal and other to be monofractal or even not fractal at all.
💡 Research Summary
The paper investigates whether the temporal sequence of sentence lengths in English literary works exhibits fractal or multifractal scaling, using two well‑established methods from statistical physics: Multifractal Detrended Fluctuation Analysis (MFDFA) and the Wavelet Transform Modulus Maxima (WTMM) technique. The authors selected a corpus of thirty novels spanning different authors, periods, and genres. After preprocessing—splitting the texts into sentences, stripping punctuation, and counting the number of words per sentence—they obtained a one‑dimensional time series for each book, where each point represents the length of a successive sentence.
MFDFA proceeds by integrating the series to form a profile, dividing it into non‑overlapping windows of size s, detrending each window by a polynomial fit, and computing the q‑order fluctuation function Fq(s). By varying q (both positive and negative) and fitting a power‑law Fq(s) ∝ s^h(q), the authors derived the generalized Hurst exponents h(q) and, via a Legendre transform, the multifractal spectrum f(α). WTMM, on the other hand, applies a continuous wavelet transform (using a derivative of Gaussian mother wavelet) to the same series, extracts the modulus maxima lines across scales, and constructs the partition function Zq(s) from the maxima amplitudes. Again, scaling exponents τ(q) are obtained from Zq(s) ∝ s^τ(q), and the singularity spectrum f(α) follows from τ(q). Using both methods provides a cross‑validation: genuine multifractality should be evident in both analyses, while method‑specific artifacts can be identified when results diverge.
The empirical results show a striking heterogeneity. Only a small subset of the books—roughly five to six, representing about 20 % of the corpus—display a broad α‑range (Δα > 0.3) and a clearly concave f(α) curve in both MFDFA and WTMM, indicating true multifractal behavior. These texts tend to be modern experimental novels or works employing stream‑of‑consciousness techniques, where sentence length fluctuates dramatically, producing long‑range correlations. In contrast, the majority of the novels, especially those by classic authors such as Charles Dickens, Jane Austen, and Mark Twain, yield narrow spectra (Δα ≈ 0.05) and nearly constant h(q), consistent with monofractal or even non‑fractal dynamics. The authors also performed a shuffling test: random permutation of the sentence‑length series destroys any temporal ordering, and in all cases the shuffled data collapse to a single Hurst exponent, confirming that the observed scaling in the original texts originates from the specific ordering of sentence lengths rather than from the marginal distribution alone.
A further sensitivity analysis examined the impact of text length and window size. Shorter works (e.g., novellas or short stories) often produce unstable estimates of h(q) and f(α) because the number of data points is insufficient to populate the large‑scale regime needed for reliable power‑law fitting. This limitation explains why some earlier studies that reported ubiquitous multifractality in literary corpora may have over‑interpreted statistical noise as genuine scaling.
The discussion interprets these findings in linguistic and literary terms. The presence of multifractality appears linked to stylistic devices that deliberately vary sentence complexity—such as abrupt shifts between terse and elaborate constructions, nested clauses, or rhythmic alternation—features common in modernist and post‑modernist prose. Conversely, more conventional narrative styles, which maintain a relatively uniform rhythm, naturally produce signals lacking hierarchical variability, thus appearing monofractal or non‑fractal.
In conclusion, the paper demonstrates that sentence‑length time series can, under specific stylistic conditions, exhibit genuine multifractal scaling, but this is far from universal across English literature. The authors recommend several avenues for future research: (1) extending the analysis to multidimensional linguistic signals (e.g., syntactic depth, lexical diversity, semantic cohesion) to capture richer aspects of textual complexity; (2) systematic mapping of multifractal signatures across authors, historical periods, and genres to explore cultural or cognitive correlates; and (3) integrating multifractal descriptors with machine‑learning classifiers for tasks such as author attribution, genre detection, or readability assessment. By bridging quantitative physics methods with literary analysis, the study opens a promising interdisciplinary pathway for understanding the hidden statistical structures of written language.
Comments & Academic Discussion
Loading comments...
Leave a Comment