An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Catastrophic forgetting is a problem faced by many machine learning models and algorithms. When trained on one task, then trained on a second task, many machine learning models "forget" how to perform the first task. This is widely believed to be a s…
Authors: Ian J. Goodfellow, Mehdi Mirza, Da Xiao
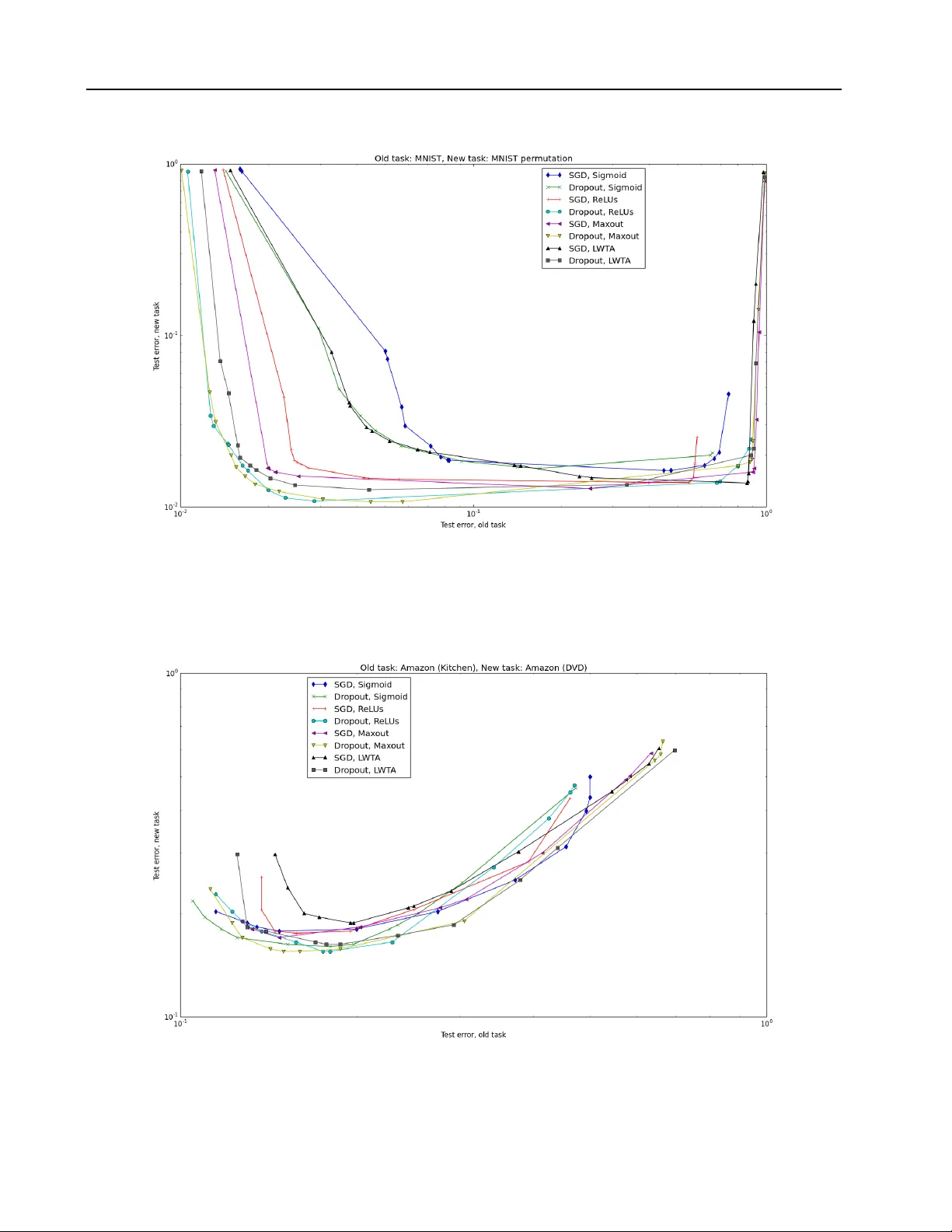
An Empirical In v estigation of Catastrophic F orgetting in Gradien t-Based Neural Net w orks Ian J. Go o dfello w goodfeli@iro.umontreal.ca Mehdi Mirza mirzamom@iro.umontreal.ca Da Xiao xiaod a99@bupt.edu.cn Aaron Courville aaron.cour ville@umontreal.ca Y osh ua Bengio yoshua.bengio@umontreal.ca Abstract Catastr ophic for getting is a problem faced b y many mac hine learning models and al- gorithms. When trained on one task, then trained on a second task, man y machine learning mo dels “forget” ho w to p erform the first task. This is widely b elieved to b e a serious problem for neural net works. Here, w e inv estigate the exten t to whic h the catas- trophic forgetting problem o ccurs for mo d- ern neural net works, comparing b oth estab- lished and recent gradient-based training al- gorithms and activ ation functions. W e also examine the effect of the relationship b et ween the first task and the second task on catas- trophic forgetting. W e find that it is alwa ys b est to train using the drop out algorithm– the dropout algorithm is consisten tly b est at adapting to the new task, remem b ering the old task, and has the b est tradeoff curve be- t ween these t wo extremes. W e find that dif- feren t tasks and relationships b etw een tasks result in v ery differen t rankings of activ ation function performance. This suggests that the c hoice of activ ation function should alw ays b e cross-v alidated. 1. In tro duction Catastrophic forgetting( McCloskey & Cohen , 1989 ; Ratcliff , 1990 ) is a problem that affects neural net- w orks, as w ell as other learning systems, including b oth biological and machine learning systems. When a learning system is first trained on one task, then trained on a second task, it may forget how to perform Co de asso ciated with this paper is av ailable at https:// github.com/goodfeli/forgetting . the first task. F or example, a mac hine learning system trained with a conv ex ob jectiv e will alwa ys reach the same configuration at the end of training on the sec- ond task, regardless of how it w as initialized. This means that an SVM that is trained on t wo differen t tasks will completely forget how to p erform the first task. Whenever the SVM is able to correctly classify an example from the original task, it is only due to c hance similarities b et ween the tw o tasks. A well-supported model of biological learning in h u- man b eings suggests that neo cortical neurons learn using an algorithm that is prone to catastrophic for- getting, and that the neocortical learning algorithm is complemen ted by a virtual exp erience system that re- pla ys memories stored in the hipp o campus in order to con tinually reinforce tasks that hav e not b een recently p erformed ( McClelland et al. , 1995 ). As mach ine learning researchers, the lesson w e can glean from this is that it is acceptable for our learning algorithms to suffer from forgetting, but they may need complemen- tary algorithms to reduce the information loss. De- signing such complemen tary algorithms dep ends on understanding the c haracteristics of the forgetting ex- p erienced by our con temp orary primary learning algo- rithms. In this pap er w e inv estigate the exten t to whic h catas- trophic forgetting affects a v ariety of learning algo- rithms and neural net work activ ation functions. Neu- roscien tific evidence suggests that the relationship be- t ween the old and new task strongly influences the out- come of the t wo successive learning exp eriences ( Mc- Clelland ). Consequen tly , we examine three different t yp es of relationship b etw een tasks: one in which the tasks are functionally identical but with different for- mats of the input, one in whic h the tasks are similar, and one in whic h the tasks are dissimilar. W e find that dropout ( Hinton et al. , 2012 ) is consis- ten tly the b est training algorithm for mo dern feedfor- Catastrophic F orgetting w ard neural nets. The choice of activ ation function has a less consistent effect–differen t activ ation func- tions are preferable dep ending on the task and rela- tionship b et ween tasks, as well as whether one places greater emphasis on adapting to the new task or re- taining performance on the old task. When training with drop out, maxout ( Goo dfellow et al. , 2013b ) is the only activ ation function to consistently app ear some- where on the frontier of p erformance tradeoffs for all tasks w e considered. How ever, maxout is not the best function at all points along the tradeoff curv e, and do es not ha ve as consisten t performance when trained with- out drop out, so it is still advisable to cross-v alidate the c hoice of activ ation function, particularly when train- ing without drop out. W e find that in most cases, drop out increases the opti- mal size of the net, so the resistance to forgetting ma y b e explained mostly by the larger nets having greater capacit y . Ho wev er, this effect is not consistent, and when using dissimilar task pairs, drop out usually de- creases the size of the net. This suggests drop out may ha ve other more subtle b eneficial effects to c haracter- ize in the future. 2. Related w ork Catastrophic forgetting has not b een a well-studied prop ert y of neural net works in recent years. This prop ert y w as w ell-studied in the past, but has not re- ceiv ed muc h attention since the deep learning renais- sance that b egan in 2006. Sriv astav a et al. ( 2013 ) re- p opularized the idea of studying this asp ect of mo dern deep neural nets. Ho wev er, the main focus of this w ork was not to study catastrophic forgetting, so the exp eriments w ere lim- ited. Only one neural netw ork was trained in eac h case. The netw orks all used the same h yp erparameters, and the same heuristically chosen stopping p oint. Only one pair of tasks w as employ ed, so it is not clear whether the findings apply only to pairs of tasks with the same kind and degree of similarity or whether the findings generalize to many kinds of pairs of tasks. Only one training algorithm, standard gradien t descen t w as em- plo yed. W e mo ve b ey ond all of these limitations by training m ultiple nets with different hyperparameters, stopping using a v alidation set, ev aluating using three task pairs with different task similarity profiles, and including the drop out algorithm in our set of exp eri- men ts. 3. Metho ds In this section, w e describ e the basic algorithms and tec hniques used in our exp eriments. 3.1. Drop out Drop out ( Hinton et al. , 2012 ; Sriv astav a , 2013 ) is a recen tly introduced training algorithm for neural net- w orks. Drop out is designed to regularize neural net- w orks in order to improv e their generalization p erfor- mance. Drop out training is a modification to standard sto c hastic gradient descent training. When eac h ex- ample is presented to the netw ork during learning, the input states and hidden unit states of the netw ork are m ultiplied by a binary mask. The zeros in the mask cause some units to b e remov ed from the net- w ork. This mask is generated randomly eac h time an example is presented. Each element of the mask is sampled indep endently of the others, using some fixed probabilit y p . At test time, no units are dropp ed, and the weigh ts going out of each unit are m ultiplied by p to comp ensate for that unit b eing present more often than it was during training. Drop out can b e seen as an extremely efficien t means of training exp onentially man y neural netw orks that share w eights, then av eraging together their predic- tions. This pro cedure resembles bagging, which helps to reduce the generalization error. The fact that the learned features must work well in the context of man y differen t models also helps to regularize the mo del. Drop out is a very effective regularizer. Prior to the in tro duction of drop out, one of the main w ays of re- ducing the generalization error of a neural netw ork w as simply to restrict its capacity by using a small n umber of hidden units. Drop out enables training of noticeably larger netw orks. As an example, w e p er- formed random hyperparameter searc h with 25 exper- imen ts in each case to find the b est t wo-la yer recti- fier net work ( Glorot et al. , 2011a ) for classifying the MNIST dataset. When training with dropout, the best net work according to the v alidation set had 56.48% more parameters than the b est net work trained with- out drop out. W e h yp othesize that the increased size of optimally functioning dropout nets means that they are less prone to the catastrophic forgetting problem than tra- ditional neural nets, which were regularized by con- straining the capacity to b e just barely sufficient to p erform the first task. Catastrophic F orgetting 3.2. Activ ation functions Eac h of the hidden la yers of our neural netw orks trans- forms some input v ector x in to an output vector h . In all cases, this is done by first computing a pr esynaptic activation z = W x + b where W is a matrix of learnable parameters and b is a v ector of learnable parameters. The presynaptic activ ation z is then transformed into a p ost-synaptic activ ation h by an activation function : h = f ( z ). h is then provided as the input to the next la yer. W e studied the following activ ation functions: 1. L o gistic sigmoid : ∀ i, f ( z ) i = 1 1 + exp( − z i ) 2. R e ctifie d line ar ( Jarrett et al. , 2009 ; Glorot et al. , 2011a ): ∀ i, f ( z ) i = max(0 , z i ) 3. Har d L o c al Winner T ake Al l (L WT A) ( Sriv astav a et al. , 2013 ): ∀ i, f ( z ) i = g ( i, z ) z i . Here g is a gating function. z is divided into dis- join t blocks of size k , and g ( i, z ) is 1 if z i is the maximal element of its group. If more than one elemen t is tied for the maximum, w e break the tie uniformly at random 1 . Otherwise g ( i, z ) is 0. 4. Maxout ( Go odfellow et al. , 2013b ): ∀ i, f ( z ) i = max j { z ki , . . . , z k ( i +1) − 1 } W e trained each of these four activ ation functions with eac h of the tw o algorithms we considered, for a total of eight distinct metho ds. 3.3. Random h yp erparameter search Making fair comparisons b etw een different deep learn- ing metho ds is difficult. The p erformance of most deep learning methods is a complicated non-linear function of multiple hyperparameters. F or many applications, the state of the art p erformance is obtained by a hu- man practitioner selecting hyperparameters for some 1 This is a deviation from the implementation of Sriv as- ta v a et al. ( 2013 ), who break ties by using the smallest index. W e used this approach because it is easier to imple- men t in Theano. W e think our deviation from the previous implemen tation is acceptable b ecause we are able to repro- duce the previously rep orted classification p erformance. deep learning metho d. Human selection is problem- atic for comparing metho ds b ecause the human prac- titioner may b e more skillful at selecting hyperparam- eters for metho ds that he or she is familiar with. Hu- man practitioners may also hav e a conflict of interest predisp osing them to selecting better h yp erparameters for metho ds that they prefer. Automated selection of hyperparameters allows more fair comparison of metho ds with a complicated de- p endence on hyperparameters. How ever, automated selection of h yp erparameters is c hallenging. Grid searc h suffers from the curse of dimensionalit y , requir- ing exp onentially many exp erimen ts to explore high- dimensional hyperparameter spaces. In this work, w e use random hyperparameter search ( Bergstra & Ben- gio , 2012 ) instead. This metho d is simple to implemen t and obtains roughly state of the art results using only 25 exp eriments on simple datasets such as MNIST. Other more sophisticated metho ds of h yp erparameter searc h, such as Bay esian optimization, may b e able to obtain b etter results, but we found that random searc h w as able to obtain state of the art p erformance on the tasks we consider, so w e did not think that the greater complication of using these metho ds was jus- tified. More sophisticated metho ds of h yp erparameter feedbac k may also introduce some sort of bias into the exp erimen t, if one of the metho ds w e study satisfies more of the mo deling assumptions of the hyperparam- eter selector. 4. Exp erimen ts All of our experiments follo w the same basic form. F or eac h exp eriment, we define tw o tasks: the “old task” and the “new task.” W e examine the b ehavior of neu- ral net works that are trained on the old task, then trained on the new task. F or each definition of the tasks, we run the same suite of experiments for tw o kinds of algorithms: stochastic gradien t descent training, and drop out training. F or eac h of these algorithms, w e try four different activ a- tion functions: logistic sigmoid, rectifier, hard L WT A, and maxout. F or each of these eight conditions, we randomly gen- erate 25 random sets of hyperparameters. See the co de accompan ying the paper for details. In all cases, w e use a mo del with t wo hidden lay ers follo wed by a softmax classification lay er. The hyperparameters w e search ov er include the magnitude of the max- norm constraint ( Srebro & Shraibman , 2005 ) for eac h la yer, the metho d used to initialize the weigh ts for eac h la yer and any hyper-parameters asso ciated with suc h Catastrophic F orgetting metho d, the initial biases for each lay er, the parame- ters controlling a saturating linear learning rate deca y and momentum increase sc hedule, and the size of each la yer. W e did not search ov er some hyperparameters for whic h go od v alues are reasonably well-kno wn. F or example, for drop out, the b est probabilit y of drop- ping a hidden unit is known to usually b e around 0.5, and the b est probability of dropping a visible unit is kno wn to usually b e around 0.2. W e used these well- kno wn constan ts on all exp erimen ts. This may reduce the maximum p ossible p erformance w e are able to ob- tain using our search, but it mak es the search function m uch b etter with only 25 experiments since few er of the exp eriments fail dramatically . W e did our b est to keep the hyperparameter searc hes comparable b etw een different metho ds. W e alwa ys used the same hyperparameter searc h for SGD as for drop out. F or the differen t activ ation functions, there are some slight differences b etw een the h yp erameter searc hes. All of these differences are related to param- eter initialization schemes. F or L WT A and maxout, w e alwa ys set the initial biases to 0, since randomly initializing a bias for each unit can mak e one unit within a group win the max to o often, resulting in dead filters. F or rectifiers and sigmoids, we randomly select the initial biases, but using different distribu- tions. Sigmoid netw orks can benefit from significan tly negativ e initial biases, since this encourages sparsit y , but these initializations are fatal to rectifier netw orks, since a significantly negativ e initial bias can preven t a unit’s parameters from ever receiving non-zero gra- dien t. Rectifier units can also b enefit from slightly p ositiv e initial biases, b ecause they help preven t rec- tifier units from getting stuck, but there is no known reason to b eliev e this helps sigmoid units. W e thus use a different range of initial biases for the rectifiers and the sigmoids. This was necessary to make sure that eac h metho d is able to achiev e roughly state of the art p erformance with only 25 exp eriments in the random search. Likewise, there are some differences in the wa y we initialize the weigh ts for eac h activ ation function. F or all activ ation functions, w e initialize the w eights from a uniform distribution o ver small v alues, in at least some cases. F or maxout and L WT A, this is alwa ys the metho d we use. F or rectifiers and sig- moids, the hyperparameter searc h ma y also choose to use the initialization metho d advocated by Martens & Sutsk ever ( 2011 ). In this metho d, all but k of the w eights going in to a unit are set to 0, while the re- maining k are set to relatively large random v alues. F or maxout and L WT A, this metho d p erforms po orly b ecause different filters within the same group can b e initialized to hav e extremely dissimilar semantics. In all cases, we first train on the “old task” until the v alidation set error has not improv ed in the last 100 ep ochs. Then w e restore the parameters corresp onding to the b est v alidation set error, and b egin training on the “new task”. W e train until the error on the union of the old v alidation set and new v alidation set has not impro ved for 100 ep o chs. After running all 25 randomly configured exp erimen ts for all 8 conditions, we mak e a p ossibilities frontier curv e showing the minimum amount of test error on the new task obtaining for eac h amount of test error on the old task. Sp ecifically , these plots are made by dra wing a curve that traces out the low er left frontier of the cloud of p oints of all (old task test error, new task test error) pairs encountered by all 25 models dur- ing the course of training on the new task, with one p oin t generated after eac h pass through the training set. Note that these test set errors are computed after training on only a subset of the training data, b ecause w e do not train on the v alidation set. It is p ossible to impro ve further by also training on the v alidation set, but w e do not do so here b ecause w e only care ab out the relativ e p erformance of the differen t metho ds, not necessarily obtaining state of the art results. (Usually p ossibilities frontier curv es are used in sce- narios where higher v alues are b etter, and the curves trace out the higher edge of a conv ex hull of scatter- plot. Here, we are plotting error rates, so the lo wer v alues are b etter and the curves trace out the lo wer edge of a conv ex hull of a scatterplot. W e used error rather than accuracy so that log scale plots would com- press regions of bad performance and expand regions of go od p erformance, in order to highligh t the differences b et ween the b est-p erforming metho ds. Note that the log scaling sometimes mak es the conv ex regions ap ear non-con vex) 4.1. Input reformatting Man y naturally o ccurring tasks are highly similar to eac h other in terms of the underlying structure that m ust b e understo o d, but hav e the input presented in a different format. F or example, consider learning to understand Italian after already learning to understand Spanish. Both tasks share the deep er underlying structure of b eing a natural language understanding problem, and fur- thermore, Italian and Spanish hav e similar grammar. Ho wev er, the sp ecific words in eac h language are differ- en t. A p erson learning Italian thus b enefits from hav- ing a pre-existing representation of the general struc- Catastrophic F orgetting ture of the language. The challenge is to learn to map the new w ords in to these structures (e.g., to attach the Italian w ord “sei” to the pre-existing concept of the second p erson conjugation of the verb “to b e”) without damaging the ability to understand Spanish. The abilit y to understand Spanish could diminish if the learning algorithm inadv ertently modifies the more abstract definition of language in general (i.e., if neu- rons that were used for verb conjugation b efore no w get re-purp osed for plurality agreement) rather than exploiting the pre-existing definition, or if the learning algorithm remo ves the asso ciations b et ween individual Spanish words and these pre-existing concepts (e.g., if the net retains the concept of there b eing a second p er- son conjugation of the v erb “to b e” but forgets that the Spanish word “eres” corresp onds to it). T o test this kind of learning problem, we designed a simple pair of tasks, where the tasks are the same, but with differen t wa ys of formatting the input. Sp ecif- ically , w e used MNIST classification, but with a dif- feren t permutation of the pixels for the old task and the new task. Both tasks th us b enefit from having concepts lik e p enstroke detectors, or the concept of p enstrok es b eing combined to form digits. How ever, the meaning of any individual pixel is different. The net must learn to asso ciate new collections of pixels to penstrokes, without significan tly disrupting the old higher level concepts, or erasing the old connections b et ween pixels and p enstrokes. The classification p erformance results are presented in Fig. 1 . Using dropout impro ved the tw o-task v alida- tion set p erformance for all mo dels on this task pair. W e sho w the effect of drop out on the optimal model size in Fig. 2 . While the nets were able to basically succeed at this task, w e don’t b elieve that they did so by mapping differen t sets of pixels into pre-existing concepts. W e visualized the first lay er weigh ts of the b est net (in terms of combined v alidation set error) and their apparent semantics do not noticeably change b et ween when training on the old task concludes and training on the new task b egins. This suggests that the higher lay ers of the net changed to b e able to ac- como date a relativ ely arbitrary pro jection of the input, rather than remaining the same while the low er lay ers adapted to the new input format. 4.2. Similar tasks W e next considered what happens when the t wo tasks are not exactly the same, but seman tically similar, and using the same input format. T o test this case, w e used sentimen t analysis of t wo pro duct categories of Amazon reviews ( Blitzer et al. , 2007 ) as the t wo tasks. Figure 2. Optimal model size with and without dropout on the input reformatting tasks. Figure 4. Optimal model size with and without dropout on the similar tasks exp eriment. The task is just to classify the text of a pro duct review as positive or negativ e in sentimen t. W e used the same prepro cessing as ( Glorot et al. , 2011b ). The classification p erformance results are presented in Fig. 3 . Using dropout impro ved the tw o-task v alida- tion set p erformance for all mo dels on this task pair. W e sho w the effect of drop out on the optimal model size in Fig. 6 . 4.3. Dissimilar tasks W e next considered what happens when the t wo tasks are seman tically similar. T o test this case, we used Amazon reviews as one task, and MNIST classifica- tion as another. In order to giv e b oth tasks the same output size, we used only t wo classes of the MNIST dataset. T o give them the same v alidation set size, w e randomly subsampled the remaining examples of the MNIST v alidation set (since the MNIST v alidation set w as originally larger than the Amazon v alidation set, and we don’t wan t the estimate of the p erformance on the Amazon dataset to ha ve higher v ariance than the MNIST one). The Amazon dataset as w e prepro cessed it earlier has 5,000 input features, while MNIST has only 784. T o giv e the tw o tasks the same input size, we reduced the dimensionality of the Amazon data with PCA. Classification performance results are presented in Catastrophic F orgetting Figure 1. Possibilities fron tiers for the input reformatting exp erimen t. Figure 3. Possibilities fron tiers for the similar tasks exp erimen t. Catastrophic F orgetting Figure 5. Possibilities fron tiers for the dissimilar tasks exp erimen t. Figure 6. Optimal model size with and without dropout on the disimilar tasks exp eriment. Fig. 5 . Using dropout impro ved the tw o-task v alida- tion set p erformance for all mo dels on this task pair. W e sho w the effect of drop out on the optimal model size in Fig. 6 . 5. Discussion Our exp erimen ts hav e shown that training with drop out is alw ays b eneficial, at least on the relatively small datasets we used in this pap er. Drop out im- pro ved p erformance for all eigh t metho ds on all three task pairs. Drop out works the b est in terms of perfor- mance on the new task, p erformance on the old task, and p oin ts along the tradeoff curve balancing these t wo extremes, for all three task pairs. Drop out’s resistance to forgetting may b e explained in part by the large mo del sizes that can b e trained with drop out. On the input-reformatted task pair and the similar task pair, drop out never decreased the size of the optimal mo del for any of the four activ ation functions we tried. How- ev er, drop out seems to hav e additional prop erties that can help preven t forgetting that we do not y et hav e an explanation for. On the dissimilar tasks experiment, drop out impro ved performance but reduced the size of the optimal mo del for most of the activ ation func- tions, and on the other task pairs, it o ccasionally had no effect on the optimal mo del size. The only recent previous work on catastrophic forget- ting( Sriv astav a et al. , 2013 ) argued that the choice of activ ation function has a significant effect on the catas- trophic forgetting prop erties of a net, and in particu- lar that hard L WT A outp erforms logistic sigmoid and rectified linear units in this respect when trained with sto c hastic gradient descen t. In our more extensive experiments w e found that the c hoice of activ ation function has a less consistent effect than the choice of training algorithm. When w e p er- formed exp erimen ts with differen t kinds of task pairs, w e found that the ranking of the activ ation functions is very problem dep enden t. F or example, logistic sig- moid is the worst under some conditions but the best Catastrophic F orgetting under other conditions. This suggests that one should alw ays cross-v alidate the choice of activ ation function, as long as it is computationally feasible. W e also re- ject the idea that hard L WT A is particular resistant to catastrophic forgetting in general, or that it mak es the standard SGD training algorithm more resistant to catastrophic forgetting. F or example, when train- ing with SGD on the input reformatting task pair, hard L WT A’s p ossibilities frontier is worse than all activ a- tion functions except sigmoid for most points along the curv e. On the similar task pair, L WT A with SGD is the worst of all eight metho ds we considered, in terms of b est performance on the new task, best performance on the old task, and in terms of attaining p oin ts close to the origin of the p ossibilities fron tier plot. How- ev er, hard L WT A do es p erform the b est in some cir- cumstances (it has the best p erformance on the new task for the dissimilar task pair ). This suggests that it is w orth including hard L WT A as one of many ac- tiv ation functions in a hyperparameter searc h. L WT A is how ev er never the leftmost p oint in any of our three task pairs, so it is probably only useful in sequential task settings where forgetting is an issue. When computational resources are to o limited to ex- p erimen t with multiple activ ation functions, we rec- ommend using the maxout activ ation function trained with drop out. This is the only method that app ears on the low er-left frontier of the p erformance tradeoff plots for all three task pairs we considered. A cknowledgments W e w ould like to thank the developers of Theano ( Bergstra et al. , 2010 ; Bastien et al. , 2012 ), Pylearn2 ( Go o dfellow et al. , 2013a ). W e w ould also like to thank NSERC, Compute Canada, and Calcul Qu´ eb ec for pro viding computational resources. Ian Go odfellow is supported by the 2013 Google F ellowship in Deep Learning. References Bastien, F r´ ed´ eric, Lamblin, P ascal, Pascan u, Raz- v an, Bergstra, James, Go odfellow, Ian J., Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Y oshua. Theano: new features and sp eed impro vemen ts. Deep Learning and Unsup ervised F eature Learning NIPS 2012 W orkshop, 2012. Bergstra, James and Bengio, Y oshua. Random searc h for hyper-parameter optimization. Journal of Machine L e arning R ese ar ch , 13:281–305, F ebru- ary 2012. Bergstra, James, Breuleux, Olivier, Bastien, F r´ ed´ eric, Lam blin, P ascal, P ascanu, Razv an, Desjardins, Guillaume, T urian, Joseph, W arde-F arley , David, and Bengio, Y oshua. Theano: a CPU and GPU math expression compiler. In Pr o c e e dings of the Python for Scientific Computing Confer enc e (SciPy) , June 2010. Oral Presentation. Blitzer, John, Dredze, Mark, and P ereira, F ernando. Biographies, b ollyw o o d, b o om-boxes and blenders: Domain adaptation for sen timent classification. In A CL ’07 , pp. 440–447, 2007. Glorot, Xa vier, Bordes, Antoine, and Bengio, Y oshua. Deep sparse rectifier neural net works. In JMLR W&CP: Pr o c e e dings of the F ourte enth International Confer enc e on A rtificial Intel ligenc e and Statistics (AIST A TS 2011) , April 2011a. Glorot, Xa vier, Bordes, Antoine, and Bengio, Y oshua. Domain adaptation for large-scale sentimen t classi- fication: A deep learning approach. In Pr o c e e dings of theTwenty-eight International Confer enc e on Ma- chine L e arning (ICML’11) , volume 27, pp. 97–110, June 2011b. Go odfellow, Ian J., W arde-F arley , Da vid, Lam blin, P ascal, Dumoulin, Vincen t, Mirza, Mehdi, Pascan u, Razv an, Bergstra, James, Bastien, F r´ ed´ eric, and Bengio, Y oshua. Pylearn2: a machine learning researc h library . arXiv pr eprint arXiv:1308.4214 , 2013a. Go odfellow, Ian J., W arde-F arley , David, Mirza, Mehdi, Courville, Aaron, and Bengio, Y oshua. Max- out netw orks. In Dasgupta, Sanjo y and McAllester, Da vid (eds.), Pr o c e e dings of the 30th International Confer enc e on Machine L e arning (ICML’13) , pp. 13191327. ACM, 2013b. URL http://icml.cc/ 2013/ . Hin ton, Geoffrey E., Sriv astav a, Nitish, Krizhevsky , Alex, Sutskev er, Ilya, and Salakhutdino v, Rus- lan. Impro ving neural net works b y prev enting co- adaptation of feature detectors. T echnical report, arXiv:1207.0580, 2012. Jarrett, Kevin, Ka vukcuoglu, Koray , Ranzato, Marc’Aurelio, and LeCun, Y ann. What is the b est m ulti-stage architecture for ob ject recognition? In Pr o c. International Confer enc e on Computer Vision (ICCV’09) , pp. 2146–2153. IEEE, 2009. Martens, James and Sutskev er, Ilya. Learning recur- ren t neural net w orks with Hessian-free optimization. In Pr o c. ICML’2011 . ACM, 2011. Catastrophic F orgetting McClelland, J. L., McNaughton, B. L., and O’Reilly , R. C. Why there are complementary learning sys- tems in the hipp o campus and neo cortex: Insights from the successes and failures of connectionist mo d- els of learning and memory . Psycholo gic al R eview , 102:419–457, 1995. McClelland, James L. McClosk ey , M. and Cohen, N. J. Catastrophic inter- ference in connectionist netw orks: The sequential learning problem. In Bow er, G. H. (ed.), The Psy- cholo gy of L e arning and Motivation, V ol. 24 , pp. 109–164. Academic Press, San Diego, CA, 1989. Ratcliff, R. Connectionist mo dels of recognition mem- ory: constraints imposed b y learning and forget- ting functions. Psycholo gic al r eview , 97(2):285–308, April 1990. ISSN 0033-295X. URL http://view. ncbi.nlm.nih.gov/pubmed/2186426 . Srebro, Nathan and Shraibman, Adi. Rank, trace- norm and max-norm. In Pr o c e e dings of the 18th A nnual Confer enc e on L e arning The ory , pp. 545– 560. Springer-V erlag, 2005. Sriv astav a, Nitish. Impro ving neural netw orks with drop out. Master’s thesis, U. T oronto, 2013. Sriv astav a, Rupesh K, Masci, Jonathan, Kazerou- nian, Sohrob, Gomez, F austino, and Schmidh u- b er, J¨ urgen. Comp ete to compute. In Burges, C.J.C., Bottou, L., W elling, M., Ghahramani, Z., and W einberger, K.Q. (eds.), A dvanc es in Neur al Information Pr o c essing Systems 26 , pp. 2310–2318. 2013. URL http://media.nips.cc/nipsbooks/ nipspapers/paper_files/nips26/1109.pdf .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment