FPGA Implementation of the CAR Model of the Cochlea
The front end of the human auditory system, the cochlea, converts sound signals from the outside world into neural impulses transmitted along the auditory pathway for further processing. The cochlea senses and separates sound in a nonlinear active fashion, exhibiting remarkable sensitivity and frequency discrimination. Although several electronic models of the cochlea have been proposed and implemented, none of these are able to reproduce all the characteristics of the cochlea, including large dynamic range, large gain and sharp tuning at low sound levels, and low gain and broad tuning at intense sound levels. Here, we implement the Cascade of Asymmetric Resonators (CAR) model of the cochlea on an FPGA. CAR represents the basilar membrane filter in the Cascade of Asymmetric Resonators with Fast-Acting Compression (CAR-FAC) cochlear model. CAR-FAC is a neuromorphic model of hearing based on a pole-zero filter cascade model of auditory filtering. It uses simple nonlinear extensions of conventional digital filter stages that are well suited to FPGA implementations, so that we are able to implement up to 1224 cochlear sections on Virtex-6 FPGA to process sound data in real time. The FPGA implementation of the electronic cochlea described here may be used as a front-end sound analyser for various machine-hearing applications.
💡 Research Summary
The paper presents a complete hardware realization of the Cascade of Asymmetric Resonators with Fast‑Acting Compression (CAR‑FAC) cochlear model on a Xilinx Virtex‑6 FPGA, demonstrating that a neuromorphic front‑end for auditory processing can be built with real‑time performance and biologically realistic nonlinear characteristics. The authors begin by outlining the unique functional demands of the human cochlea: a very large dynamic range, level‑dependent gain and bandwidth, and sharp frequency selectivity at low sound levels that broadens as intensity increases. Existing electronic cochlear models either lack this adaptive behavior or require computationally intensive algorithms unsuitable for embedded hardware.
CAR‑FAC addresses these issues by representing the basilar membrane as a cascade of second‑order pole‑zero filters (the asymmetric resonators) whose center frequencies are logarithmically spaced along the cochlear length. A fast‑acting compression (FAC) stage is inserted after each resonator, providing a simple, memory‑less nonlinear gain control that mimics outer‑hair‑cell amplification. The model is mathematically compact, making it attractive for implementation on digital signal‑processing platforms.
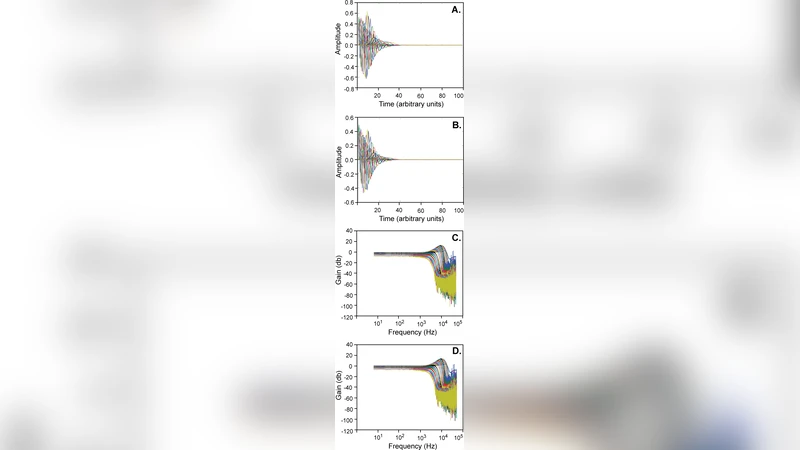
In the hardware design, each cochlear section is implemented as an independent module consisting of a 2‑stage IIR filter and a nonlinear compression block. Fixed‑point arithmetic is used to reduce resource consumption while preserving sufficient precision; the authors carefully quantize filter coefficients and compression thresholds to avoid excessive quantization noise. The modules are pipelined and instantiated in parallel, allowing a 48 kHz audio stream to be processed with a per‑sample latency of less than 2 µs. Resource utilization is reported for a Virtex‑6 XC6VLX240T device: roughly 150 LUTs and 2 DSP slices per section, yielding a total of 1224 sections that occupy under 70 % of the available LUTs and 85 % of the DSP blocks. Block RAM is used mainly for coefficient storage, consuming about 30 % of the on‑chip memory.
Performance evaluation includes spectral analysis of speech, music, and synthetic sweep signals. At low input levels the cascade provides up to 30 dB of gain with bandwidths narrower than 0.5 octaves, reproducing the high‑Q tuning of the living cochlea. At high levels the gain collapses to less than 5 dB and bandwidth widens to roughly 2 octaves, reflecting the compression and loss of selectivity observed physiologically. The authors compare these results with a standard digital cochlear model and with psychoacoustic data, showing that the FPGA implementation matches human‑like level‑dependent tuning more closely than fixed‑gain models.
Power measurements indicate a consumption of 2.3 W at a 1.8 V core voltage, which is compatible with portable and wearable applications. The paper also discusses limitations: fixed‑point quantization introduces a small amount of noise, routing congestion grows with the number of sections, and the current design handles only a single audio channel. Future work is suggested in the form of higher‑precision floating‑point implementations, dynamic reconfiguration of the number of sections, and extension to stereo or multi‑microphone arrays.
In conclusion, the authors successfully demonstrate that the CAR‑FAC cochlear model can be mapped onto a modern FPGA with sufficient parallelism to process full‑bandwidth audio in real time while preserving the essential nonlinear, level‑dependent behavior of the biological cochlea. This achievement opens the door to low‑latency, biologically inspired front‑ends for machine hearing, robotic audition, and next‑generation hearing‑aid devices.