Convolutional Neural Networks for joint object detection and pose estimation: A comparative study
In this paper we study the application of convolutional neural networks for jointly detecting objects depicted in still images and estimating their 3D pose. We identify different feature representations of oriented objects, and energies that lead a network to learn this representations. The choice of the representation is crucial since the pose of an object has a natural, continuous structure while its category is a discrete variable. We evaluate the different approaches on the joint object detection and pose estimation task of the Pascal3D+ benchmark using Average Viewpoint Precision. We show that a classification approach on discretized viewpoints achieves state-of-the-art performance for joint object detection and pose estimation, and significantly outperforms existing baselines on this benchmark.
💡 Research Summary
This paper investigates how convolutional neural networks (CNNs) can be used to jointly detect objects in still images and estimate their 3‑D pose, focusing on the azimuth angle. The authors argue that detection (a discrete class label) and pose estimation (a continuous variable) have conflicting requirements, and they explore several ways of representing oriented objects within a single CNN framework. All experiments are built on the Spatial Pyramid Pooling (SPP) architecture of He et al. (2014) using the “Zeiler5” network pre‑trained on ImageNet; only the three fully‑connected layers on top of the shared convolutional features are fine‑tuned for each task.
Three families of output representations are examined:
-
Discrete Pose Classification (Section 4.1). The azimuth space is quantized into P bins; each bin is treated as a separate class, yielding N × P + 1 output scores (N object categories plus background). A softmax and standard cross‑entropy loss are used. This approach directly re‑uses the successful detection pipeline and requires no special loss design.
-
Continuous Regression (Section 4.2). Here the pose is modeled as a point on the unit circle: (cos θ, sin θ, 0) in a 3‑D feature space. Positive samples are forced to lie on the circle, while negative samples are pushed away using an exponential loss that depends on the Euclidean distance to the circle’s projection. The loss for positives is a simple squared‑error term. This formulation respects the continuity of the viewpoint but introduces a non‑trivial loss landscape that must be carefully balanced (parameters K and δ).
-
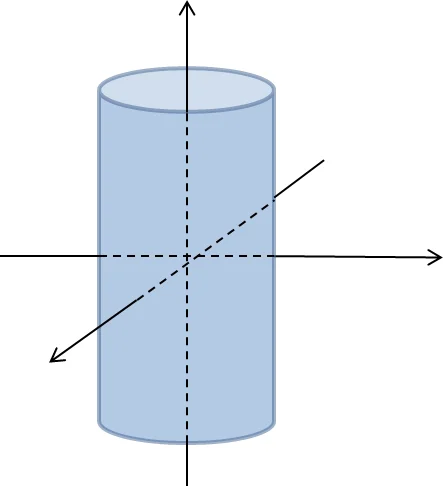
Joint Classification and Continuous Pose Estimation (Section 4.3). The network simultaneously predicts a categorical probability vector (N × 1) and a continuous pose vector. Several manifold choices for the pose vector are tested: a single shared circle for all classes, a per‑class circle, and a per‑class cylinder (i.e., a circle embedded in a higher‑dimensional space). Corresponding loss functions combine cross‑entropy for classification with either regression‑type or distance‑based terms for the pose component.
The authors evaluate all variants on the Pascal3D+ benchmark, which augments the classic Pascal VOC images with 3‑D CAD alignments for 12 object categories. Performance is measured with Average Viewpoint Precision (AVP), which requires a correct detection together with a correctly predicted viewpoint bin.
Key findings:
- The discrete classification approach achieves the highest AVP scores, outperforming the strongest previously reported baseline (a DPM‑based method with 3‑D constraints by Pepik et al., 2012) by roughly 7–10 percentage points when using 24 viewpoint bins.
- The continuous regression model yields lower average angular error but suffers in AVP because the metric penalizes any mis‑alignment of the discrete bin, highlighting the importance of matching the evaluation protocol.
- The joint model improves pure detection AP by about 2 percentage points while maintaining competitive pose estimation, demonstrating that learning detection and pose together provides mutually beneficial cues.
The paper concludes that, given limited training data and the AVP evaluation, discretizing the pose space and treating each bin as a separate class is the most effective strategy. Nevertheless, the continuous formulations are valuable for tasks where fine‑grained angular accuracy matters, and the joint architecture shows that detection can be boosted by sharing pose‑related features.
Overall, the work offers a systematic comparison of representation choices for joint detection and pose estimation, establishes a strong CNN‑based baseline on Pascal3D+, and suggests future directions such as richer continuous manifolds, multi‑angle (pitch, roll) estimation, and end‑to‑end region proposal networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment