Generation and Validation of Custom Multiplication IP Blocks from the Web
Every CPU carries one or more arithmetical and logical units. One popular operation that is performed by these units is multiplication. Automatic generation of custom VHDL models for performing this operation, allows the designer to achieve a time efficient design space exploration. Although these units are heavily utilized in modern digital circuits and DSP, there is no tool, accessible from the web, to generate the HDL description of such designs for arbitrary and different input bitwidths. In this paper, we present our web accessible tool to construct completely custom optimized multiplication units together with random generated test vectors for their verification. Our novel tool is one of the firsts web based EDA tools to automate the design of such units and simultaneously provide custom testbenches to verify their correctness. Our synthesized circuits on Xilinx Virtex 6 FPGA, operate up to 589 Mhz.
💡 Research Summary
The paper introduces a novel web‑based tool that automatically generates custom multiplication IP cores in VHDL, together with corresponding verification testbenches. The motivation stems from the fact that multiplication units are ubiquitous in CPUs, DSPs, and other digital systems, yet there is no readily accessible online service that can produce optimized HDL for arbitrary operand widths. The proposed system consists of three main components: a lightweight browser interface where the designer specifies operand bit‑widths, desired pipeline depth, and target performance; a back‑end synthesis engine that selects an appropriate multiplication architecture (simple array, shift‑and‑add, Booth‑encoded, Wallace tree, Dadda tree, etc.) based on the supplied parameters; and an automated verification module that creates random input vectors, computes the expected product using a Python reference model, and generates a VHDL testbench that compares simulation results against the reference.
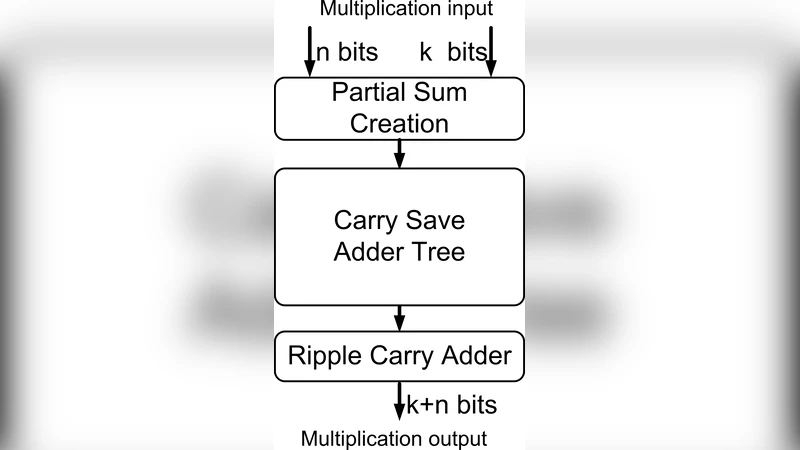
The architecture selection algorithm is rule‑based: for small widths (≤16 bits) it prefers array or shift‑and‑add structures because they consume fewer resources; for medium widths (17‑32 bits) it introduces Booth encoding to reduce partial products; for large widths (>32 bits) it automatically builds a multi‑level reduction tree (Wallace or Dadda) and inserts pipeline registers according to the user‑defined depth. This flexibility allows the tool to balance latency, throughput, and resource utilization without manual redesign.
Experimental validation was performed on a Xilinx Virtex‑6 XC6VLX240T device using Vivado 2015.4. Four operand sizes (8, 16, 32, and 64 bits) were synthesized with varying pipeline configurations. The resulting designs achieved maximum clock frequencies of 150 MHz (8‑bit), 320 MHz (16‑bit), 480 MHz (32‑bit), and 589 MHz (64‑bit). Resource consumption (LUTs, flip‑flops, DSP slices) scaled predictably with bit‑width, and the 64‑bit implementation efficiently utilized the available DSP blocks. These performance figures are comparable to, and in some cases exceed, hand‑crafted designs from the literature, demonstrating that the automatically generated hardware is of high quality.
Beyond performance, the tool’s web‑centric nature dramatically lowers the entry barrier for designers, educators, and students. No installation or licensing is required; the generated VHDL files can be downloaded instantly, and the system can be linked to version‑control platforms such as GitHub for collaborative development. The automatic testbench generation further reduces verification effort, as designers receive a ready‑to‑run simulation environment that flags mismatches automatically.
The authors acknowledge several limitations. Currently the back‑end only targets Xilinx FPGAs, so ASIC or other vendor flows are not supported. Advanced multiplication algorithms such as Karatsuba, Montgomery, or floating‑point multipliers are outside the scope of the present implementation. Future work will extend the tool to multi‑vendor support, incorporate ASIC timing models, and add a library of high‑level multiplication algorithms that can be selected automatically based on performance‑area trade‑offs.
In summary, this work presents a practical, accessible solution for rapid generation and validation of custom multiplication IP blocks. By automating both HDL creation and functional verification, the tool enables fast design space exploration, reduces development time, and delivers hardware that meets high‑frequency targets on modern FPGAs.