An Algorithm for Online K-Means Clustering
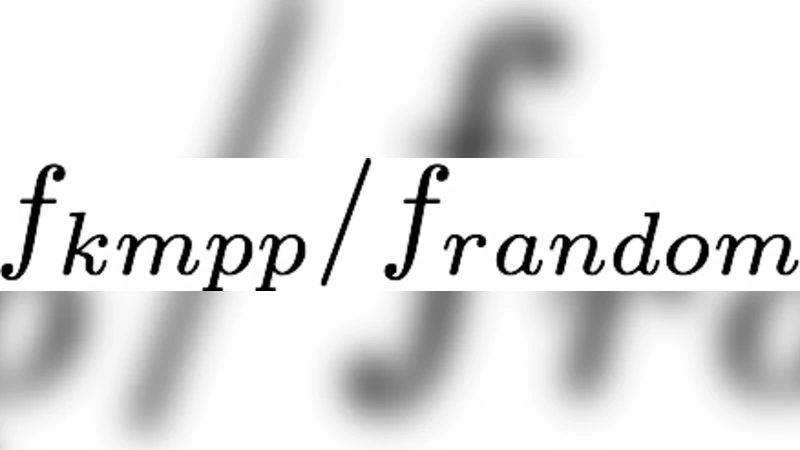
This paper shows that one can be competitive with the k-means objective while operating online. In this model, the algorithm receives vectors v_1,…,v_n one by one in an arbitrary order. For each vector the algorithm outputs a cluster identifier before receiving the next one. Our online algorithm generates ~O(k) clusters whose k-means cost is ~O(W*). Here, W* is the optimal k-means cost using k clusters and ~O suppresses poly-logarithmic factors. We also show that, experimentally, it is not much worse than k-means++ while operating in a strictly more constrained computational model.
💡 Research Summary
**
The paper addresses the problem of performing k‑means clustering in an online setting, where data points arrive one by one in an arbitrary order and the algorithm must assign each point to a cluster immediately, without the ability to revise past decisions. This model is stricter than the streaming model (which allows a single pass and delayed output) and poses significant theoretical challenges: even for one‑dimensional data with k = 2, any deterministic online algorithm can be forced to incur unbounded cost relative to the optimal offline solution.
To overcome these difficulties, the authors propose two algorithms that blend ideas from the online uncapacitated facility‑location problem (Meyerson, 2001) with the k‑means objective (squared Euclidean distances). The central mechanism is a facility cost f_r that controls how aggressively new clusters (facilities) are opened. When a new point v arrives, the algorithm computes the minimum squared distance D²(v, C) to the current set of cluster centers C. It then opens a new cluster with probability p = min{D²(v, C)/f_r, 1}. If a new cluster is opened, v becomes a new center; otherwise v is assigned to its nearest existing center. After a predetermined number of clusters (≈ 3 k (1 + log n)) have been opened in the current phase, the facility cost is doubled (f_{r+1}=2 f_r), making further openings less likely.
Two settings are considered:
- Semi‑online model – The algorithm knows in advance the stream length n and a lower bound w* on the optimal k‑means cost W*. Using this information, the initial facility cost is set to f₁ = w*/(k log n). The algorithm (Algorithm 1) guarantees, in expectation,
- Number of clusters: E
Comments & Academic Discussion
Loading comments...
Leave a Comment