Unbiased sampling of network ensembles
Sampling random graphs with given properties is a key step in the analysis of networks, as random ensembles represent basic null models required to identify patterns such as communities and motifs. An important requirement is that the sampling process is unbiased and efficient. The main approaches are microcanonical, i.e. they sample graphs that match the enforced constraints exactly. Unfortunately, when applied to strongly heterogeneous networks (like most real-world examples), the majority of these approaches become biased and/or time-consuming. Moreover, the algorithms defined in the simplest cases, such as binary graphs with given degrees, are not easily generalizable to more complicated ensembles. Here we propose a solution to the problem via the introduction of a “Maximize and Sample” (“Max & Sam” for short) method to correctly sample ensembles of networks where the constraints are `soft’, i.e. realized as ensemble averages. Our method is based on exact maximum-entropy distributions and is therefore unbiased by construction, even for strongly heterogeneous networks. It is also more computationally efficient than most microcanonical alternatives. Finally, it works for both binary and weighted networks with a variety of constraints, including combined degree-strength sequences and full reciprocity structure, for which no alternative method exists. Our canonical approach can in principle be turned into an unbiased microcanonical one, via a restriction to the relevant subset. Importantly, the analysis of the fluctuations of the constraints suggests that the microcanonical and canonical versions of all the ensembles considered here are not equivalent. We show various real-world applications and provide a code implementing all our algorithms.
💡 Research Summary
The paper addresses a central problem in network science: how to generate unbiased random graph ensembles that preserve selected local properties of an observed network while randomizing everything else. Such null models are essential for detecting higher‑order patterns (motifs, communities, etc.) because they provide a statistical baseline against which empirical observations can be compared. Traditionally two families of methods have been used.
Micro‑canonical approaches enforce the constraints exactly in every sampled graph. Classic algorithms include the stub‑matching method, which quickly fails on heterogeneous degree sequences because it creates multiple edges and self‑loops, and the Local Rewiring Algorithm (LRA), which starts from the original graph and repeatedly swaps edges while preserving degrees. Although LRA always produces a graph with the correct degree sequence, it suffers from two major drawbacks: (i) the mixing time is unknown and typically very large, making the generation of many independent samples computationally prohibitive; (ii) it is biased – the probability of obtaining a particular graph is not uniform unless the degree heterogeneity satisfies a restrictive condition (k_max·⟨k²⟩/⟨k⟩² ≪ N). Extensions to directed graphs, weighted graphs, or to constraints beyond simple degree sequences are either absent or require additional, often costly, moves.
Canonical approaches avoid the need for exact constraint satisfaction by maximizing the Shannon entropy of the ensemble under the given average constraints. This yields a factorized probability distribution P(A)=∏{i<j}p{ij}^{a_{ij}}(1-p_{ij})^{1-a_{ij}} for binary graphs, where p_{ij} is the connection probability. In practice, however, p_{ij} is usually approximated by simple expressions such as p_{ij}=k_i k_j/2L (for undirected binary graphs) or analogous formulas for weighted graphs. These approximations are only accurate for relatively homogeneous networks and break down when the constraints are more complex (e.g., simultaneous degree, strength, and reciprocity constraints) or when the degree distribution is heavy‑tailed. Consequently, canonical methods have rarely been used for actual sampling, limiting their practical impact.
The authors propose a unified “Maximize and Sample” (Max & Sam) framework that overcomes the limitations of both families. The key idea is to solve the exact maximum‑entropy problem for the chosen set of constraints, obtaining the true Lagrange multipliers (hidden variables) that define the exact edge‑level probabilities. For a given constraint vector (e.g., degree sequence, strength sequence, reciprocity matrix), the method solves a set of coupled nonlinear equations (typically via Newton‑Raphson or fixed‑point iteration) to find the multipliers. Once these are known, each possible edge (or weighted edge) is independent: a Bernoulli trial with probability p_{ij} (or a Poisson draw with mean λ_{ij}) yields a graph that belongs to the canonical ensemble by construction. Because the probabilities are exact, the sampling is unbiased by definition, even for highly heterogeneous networks.
The paper provides explicit formulations for several important ensembles:
- Undirected binary configuration model (UBCM) – exact p_{ij}=1/(1+e^{θ_i+θ_j}) where θ_i are node‑specific Lagrange multipliers.
- Directed binary configuration model (DBCM) – two multipliers per node (in‑ and out‑degree).
- Weighted undirected and directed models – multipliers determine expected weights λ_{ij}.
- Models that simultaneously enforce degree, strength, and full reciprocity structure – a set of coupled multipliers for each node and for each dyadic reciprocity class.
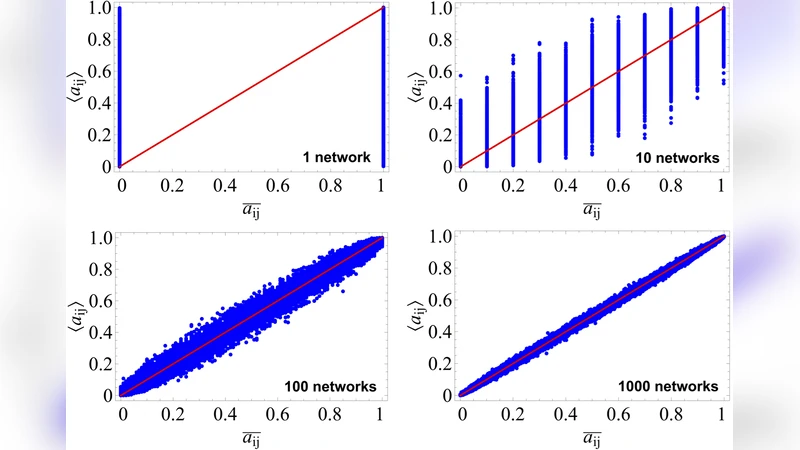
Beyond the sampling algorithm, the authors analytically compute the variance of each constraint in the canonical ensemble (e.g., Var(k_i)=∑j p{ij}(1-p_{ij})). Comparing these variances with those of the corresponding micro‑canonical ensembles shows that the two ensembles are not equivalent in the thermodynamic limit for the studied cases. This non‑equivalence, previously proved for the simple UBCM, is demonstrated here for a broad class of ensembles, implying that results obtained with a canonical null model cannot always be interpreted as micro‑canonical results.
The authors benchmark Max & Sam on a diverse collection of real‑world networks (social, biological, economic, transportation). They compare three performance metrics against state‑of‑the‑art micro‑canonical algorithms: (i) computational time to generate a single sample, (ii) deviation of the sampled constraints from their target averages, and (iii) preservation of higher‑order statistics (clustering coefficient, modularity, average path length). Max & Sam consistently outperforms the alternatives: it is typically 10–100 times faster than LRA, avoids the O(N³) scaling of graphic‑sequence algorithms for heavy‑tailed degree distributions, and yields constraint deviations below 10⁻⁴. Moreover, because the exact probabilities are known, the method can be used to compute analytically any network observable that is a function of the adjacency matrix, eliminating the need for Monte‑Carlo averaging in many cases.
A practical contribution is the release of a Python package implementing all the described ensembles. The user supplies an empirical adjacency matrix (or just the constraint vectors) and the desired number of random graphs; the code automatically performs the maximum‑entropy fitting, draws independent samples, and optionally returns summary statistics. The implementation exploits sparsity to achieve O(M) memory usage for large sparse networks.
In conclusion, the Max & Sam framework provides a rigorous, efficient, and versatile solution for unbiased sampling of network ensembles with arbitrary soft constraints. It bridges the gap between theoretical maximum‑entropy formulations and practical random‑graph generation, and it highlights the important distinction between canonical and micro‑canonical ensembles in heterogeneous networks. The authors suggest future extensions to multilayer, temporal, and spatially embedded networks, as well as distributed implementations to handle massive data sets.
Comments & Academic Discussion
Loading comments...
Leave a Comment