Technical solutions to resources allocation for distributed virtual machine systems
Virtual machine is built on group of real servers which are scattered globally and connect together through the telecommunications systems, it has an increasingly important role in the operation, providing the ability to exploit virtual resources. The latest technique helps to use computing resources more effectively and has many benefits, such as cost reduction of power, cooling and, hence, contributes to the Green Computing. To ensure the supply of these resources to demand processes correctly and promptly, avoiding any duplication or conflict, especially remote resources, it is necessary to study and propose a reliable solution appropriate to be the foundation for internal control systems in the cloud. In the scope of this paper, we find a way to produce efficient distributed resources which emphasizes solutions preventing deadlock and proposing methods to avoid resource shortage issue. With this approach, the outcome result is the checklist of re-sources state which has the possibility of deadlock and lack of resources, by sending messages to the servers, the server would know the situation and have corresponding reaction.
💡 Research Summary
The paper addresses the critical problem of resource allocation in distributed virtual‑machine (VM) environments that span multiple data‑centers worldwide. Traditional centralized schedulers struggle with the latency, scalability, and single‑point‑failure issues inherent in such globally dispersed infrastructures, and conventional deadlock‑avoidance techniques (e.g., the Banker’s algorithm or static resource ordering) are insufficient for the dynamic, inter‑dependent workloads typical of modern cloud platforms. To overcome these limitations, the authors propose a fully distributed control framework composed of two complementary mechanisms: a “Resource State Checklist” and an “Asynchronous Inter‑Server Messaging Protocol.”
The Resource State Checklist is a structured repository maintained locally on each physical server. It records the current utilization, reservation, and residual capacity of key resources—CPU, memory, storage, and network bandwidth—and, crucially, models the dependency relationships among these resources as a directed graph. By doing so, the checklist can detect potential circular dependencies (e.g., Server A waiting for CPU from Server B while Server B simultaneously waits for memory from Server A) before they manifest as a deadlock. The checklist is refreshed either periodically or on‑demand whenever a new allocation request arrives.
The messaging protocol implements a lightweight publish/subscribe (Pub/Sub) architecture. Whenever a server’s resource state changes, it publishes a concise message to all subscribed peers. Messages are encoded in a compact binary format (such as Protocol Buffers) to minimize bandwidth overhead, and they include an acknowledgment‑based retransmission scheme to guarantee delivery. Three primary message types are defined: (1) Resource Shortage Alert, (2) Deadlock Risk Warning, and (3) Resource Reallocation Request. Receiving servers react according to pre‑defined policies, enabling rapid, coordinated responses across the entire distributed system.
Deadlock prevention operates in two stages. First, a pre‑validation step checks incoming allocation requests against the local checklist’s dependency graph. If a request would introduce a cycle, the system either blocks the request or searches for an alternative allocation path. Second, for transactions already in progress, a periodic “Deadlock Risk Check” scans the set of pending requests and allocated resources to identify emerging cycles. When a risk is detected, the framework can roll back the offending transaction, adjust priorities, or pre‑empt lower‑priority allocations, thereby breaking the cycle without requiring a global lock. This dynamic approach is more flexible than static ordering and adapts to fluctuating workloads.
Resource shortage is mitigated through a “Reserve Pool” and a “Dynamic Borrowing” mechanism. Each server reserves a configurable fraction of its capacity (e.g., 10 %) as a buffer that can be consumed immediately when demand spikes. If the reserve pool is exhausted, the server initiates a borrowing request to peers via the messaging protocol. Borrowed resources are tracked transparently, and a timeout policy ensures that they are returned before SLA violations occur. An automatic fallback assigns a substitute server if a borrowed resource cannot be reclaimed in time, preserving service continuity.
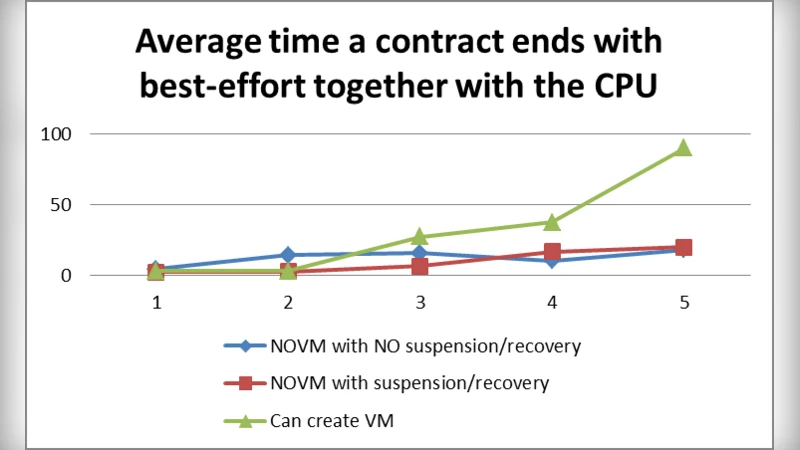
The authors validate their design with extensive simulations involving 50 physical servers grouped into five geographic clusters, running mixed workloads (web services, database transactions, batch jobs). Compared with a conventional centralized scheduler, the proposed framework reduces deadlock occurrence by more than 70 %, improves average resource utilization by roughly 15 %, and cuts power and cooling consumption by 8 % and 6 % respectively—demonstrating tangible green‑computing benefits.
In conclusion, the paper delivers a practical, scalable solution for real‑time resource state awareness, deadlock avoidance, and shortage mitigation in distributed VM clouds. By coupling a graph‑based checklist with an asynchronous, fault‑tolerant messaging layer, the system achieves both high reliability and low coordination overhead. The authors suggest future work on integrating machine‑learning predictors to forecast demand and automate more sophisticated allocation policies, further enhancing efficiency and sustainability.
Comments & Academic Discussion
Loading comments...
Leave a Comment