A Row-parallel 8$times$8 2-D DCT Architecture Using Algebraic Integer Based Exact Computation
An algebraic integer (AI) based time-multiplexed row-parallel architecture and two final-reconstruction step (FRS) algorithms are proposed for the implementation of bivariate AI-encoded 2-D discrete cosine transform (DCT). The architecture directly r…
Authors: A. Madanayake, R. J. Cintra, D. Onen
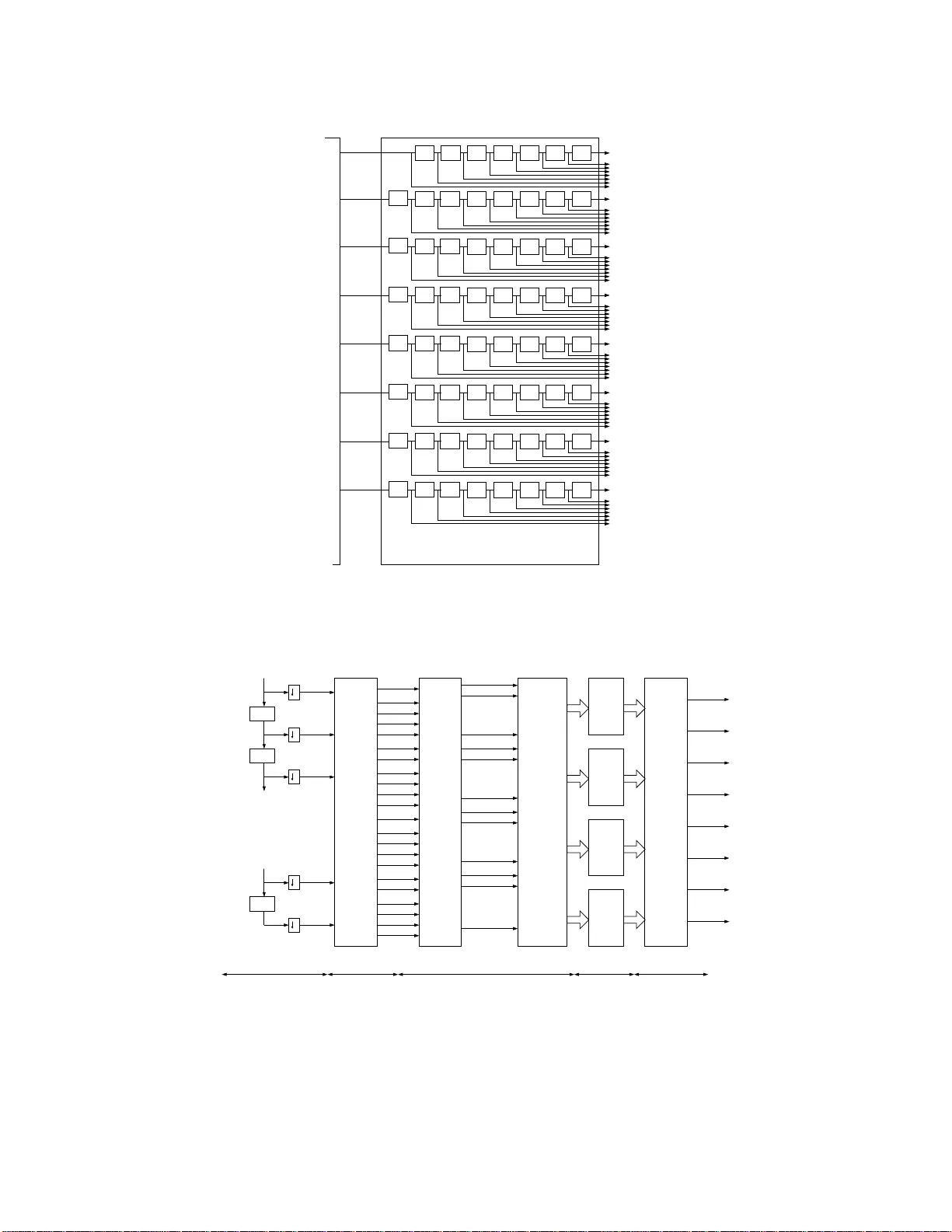
A Ro w-paralle l 8 × 8 2-D DCT Architec ture Using Algebraic Integer Based Exact Computa tion A. Madanayake ∗ R. J. Cintra † D. Onen ‡ V . S. Dimitrov ‡ N. T . Rajapaksha ∗ L. T . Bruton ‡ A. Edirisuriya ∗ Abstract An algebraic intege r (AI) based time-multiplex ed row-parallel architecture and two final-recon struction step (FRS) algorithms are proposed for the implementation of biv ariate AI-encoded 2-D discrete cosine transform (DCT). The architecture d irectly realizes an error-free 2-D DCT without using FRSs between row-column tr ansforms, leading to an 8 × 8 2-D DCT which is en ti r ely fre e of quantization err ors in AI basis. As a result, the user-selectable accuracy for each of the coef ficients in the F RS facilitates each of the 64 coef ficients to have its precision set indepen dently of others, avoidin g the leakage of quantization noise between channels as is the case for published DC T designs. T he proposed FRS uses two approaches based on (i) optimized Dempster-Macleod multi pliers and (ii) expa nsion factor scaling. This arch it ecture enables lo w-noise high-d ynamic range ap plications in digital video processing that requires full control of the finite-precision computation of the 2-D DCT . The proposed architectures and FRS techniques are experimen tally v erified and validated using hardware implementations that are physically realized and verified on FPGA chip. Six designs, fo r 4- an d 8-bit inpu t word sizes, using the two proposed FRS s chemes, hav e been designed, simulated, physically implemented and measured. The maximum clock r ate and block-rate achieve d among 8-bit input designs are 307.787 MHz and 38.47 MHz, respec tively , implying a pixel rate of 8 × 307.787 ≈ 2.462 GHz if e ventually embedded in a real-time video-processing system. T he equiv alent frame rate is about 1187.35 Hz for the image size of 1920 × 10 80. Al l implementations are functional on a Xilinx V irtex-6 XC6VLX24 0T F PGA de vice. K eywords DCT , Algebraic Integer Quantization, FPGA design 1 I N T RO D U C T I O N High-qu ality d igital video in multimedia devices and video-over -IP networks conne cted to th e I nternet are under expo- nential gr owth and therefo re the deman d for app lications capab le of hig h dyna mic range (HDR) video is acco rdingly increasing. Some HDR ima ging applications include automa tic surveillance [1 – 4], geospatial rem ote sensing [5], traf- fic cameras [6], h omeland secur ity [4], satellite based imaging [7 – 9], unman ned aerial vehicles [10–12], au tomotive industry [13], and mu ltimedia wireless sensor networks [14]. Su ch HDR video systems op erating at high resolu tions require an associate hardware capable of significant throughp ut at allowable area-power co mplexity . ∗ A. Madanayake , N. T . Rajapaksha and A. Edirisuriya are wit h the Department of Electrica l and Computer Engine ering, Uni versity of Akron, Akron, OH, USA Email: arj una@uakron.edu † R. J. Cintra is with the Signal Processing Group, Departa mento de E stat ´ ıstica , Uni versidade Federal de Pernamb uco. E-mail: rjdsc@stat .ufpe.org ‡ D. Onen, V . S. Dimitr ov an d L. T . Brut on are with Depa rtment of Electrical and Computer Engineering, Uni versity of Ca lgary , Calga ry , AB, Canada . 1 Efficient codec circuits capab le of both high-speeds of operation and hig h nu merical accuracy a re needed for next- generation systems. Such systems may p rocess massiv e amounts of video f eeds, each at high resolution , with minimal noise and distortion while consumin g as little energy as possible [15]. The two-d imensional (2-D) discrete cosine tra nsform (DCT) operation is fund amental to almost all real-time video compression systems. The circuit r ealization of th e DCT directly relates to noise, distortio n, c ircuit ar ea, and power consump tion of the related video devices [ 15]. Usually , the 2-D DCT is computed b y suc cessi ve calls of the o ne- dimensiona l (1 -D) DCT ap plied to the columns o f an 8 × 8 su b-image; then to the rows of t h e tran sposed r esulting intermediate calculation [16]. The VLSI implementatio n of trigo nometric transforms such as DCT and DFT is indeed an activ e research area [17–33]. An id eal 8 -point 1-D DCT requires multiplications by numbers in the fo rm c [ n ] = co s ( n π / 16 ) , n = 0 , 1 , . . . , 7. These constants impose c omputatio nal difficulties in terms of num ber binar y represen tation since the y are not rational. Usual DCT implemen tations adopt a compr omise solution to this pro blem emp loying truncation o r ro unding off [34, 35] to appr oximate such q uantities. Thus, instead of emp loying the exact value c [ n ] , a qu antized value is consider ed. Clearly , this operation introduces errors. One way o f add ressing this prob lem is to employ algeb raic integer (AI) encod ing [ 36, 37]. AI-encod ing ph ilos- ophy co nsists of m apping p ossibly irr ational num bers to ar ray o f integers, which can be arithmetically manipu lated without errors. Also, depen ding on the n umbers to b e en coded, this mappin g can be exact. For examp le, all 8-p oint DCT mu ltipliers can be g iv en an exact AI r epresentation [3 8]. Eventu ally , afte r com putation is perfo rmed, AI-b ased algorithm s req uire a final recon struction step (FRS) in ord er to m ap the resulting encoded integer arrays back in to usual fixed-point representation at a gi ven precision [36]. Besides the n umerical represen tation issues, error pro pagation also play s a role. In particular, whe n considerin g the fixed-point realiza tion of the multiplicatio n op eration, quantization erro rs are pro ne to be amplified in the DCT computatio n [39, 4 0]. Quantization noise at a particular 2-D DCT coefficient can ha ve sign ificant corr elation with noise in oth er coefficients depend ing on the statistics o f th e vid eo sign al of interest [ 31, 33, 39, 40]. Combatin g noise injection, noise coupling , and noise amplification is a conce rn i n a p ractical DCT implementation [31, 33–35, 39, 40]. In [4 1, 42], AI-based pro cedures for the 2-D DCT are propo sed. Their ar chitecture was based on the lo w- complexity Arai algorithm [43], which form ed th e building-block of each 1- D DCT using AI number representa- tion. Th e Arai a lgorithm is a p opular algo rithm fo r vid eo and image pro cessing app lications becau se of its relatively low comp utational comp lexity . I t is noted that the 8-p oint Arai algorithm only n eeds five mu ltiplications to gener ate the eig ht o utput co efficients. Thus, we n aturally ch oose this low complexity algo rithm as a fo undation fo r p roposing optimized architectu res having lower co mplexity and lo wer-noise. Howev er, suc h design req uired the alg ebraically en- coded n umbers to b e r econstructed to their fixed-poin t format by the end of colu mn-wise DCT calculation by means of an intermediate reconstruction step . Then data are re-code d to enter into the r ow-wise DCT calculation block [41, 4 2]. This appro ach is no t ideal be cause it intr oduces bo th n umerical r epresentation err ors an d er ror propag ation from the intermediate FSR to subsequen t blocks. W e pr opose a digital hardware architecture for the 8 × 8 2 -D DCT capable of (i) arbitrarily high numeric accuracy and (ii) high -throu ghput. T o achieve these goals our design maintain s the signal flow free of quantization error s in all its inter mediate computatio nal steps by mean s of a n ovel do ubly AI encod ing concept. No intermed iate reconstruc- tion step is in troduce d and th e entir e com putation truly occurs over the AI structu re. This p revents error prop agation throug hout intermed iate compu tation, wh ich would otherwise result in error co rrelation amo ng the final DCT co effi- cients. Thus err ors ar e totally co nfined to a single FRS th at map s th e resu lting d oubly AI enc oded DCT coe fficients 2 into fixed- point representation s [36]. This p rocedu re allo ws th e selection of individual le vels of precision fo r each o f the 64 DCT spectral components a t the FRS. At the same time, such flexibility does not affect noise lev els or speed of other sections of the 2-D DCT . This works extends the 8-po int 1-D AI -based DCT arch itecture [3 7, 41 , 42] into a f ully-par allel time-multip lexed 2-D architecture for 8 × 8 data blocks. The fund amental differences are (i) the absence of any in termediate reconstruc- tion step; (ii) a new do ubly AI enco ding scheme; an d (iii) th e utilization o f a sing le FRS. The pr oposed 2-D 8 × 8 ar- chitecture has the following ch aracteristics: (i) indepe ndently selectab le p recision le vels fo r the 2-D DCT coef ficients; (ii) total ab sence o f multiplication ope rations; an d (iii) absence of leakag e of quan tization no ise b etween coefficient channels. T he p roposed arc hitectures aim a t p erform ing the FRS op eration dir ectly in the b i-variate encoded 2- D AI basis. W e introduce design s b ased on (i) op timized Dem pster-Macleod mu ltipliers and on (ii) th e expansion factor approa ch [44]. All har dware im plementation s ar e designed to be realized on field progr ammable gate arrays (FPGAs) from Xilinx [45]. This paper un folds as fo llows. In Sectio n 2 we r evie w existing design s and the main theoretical poin ts of num ber representatio n b ased on AI. W e keep ou r fo cus on the core results ne eded for our design. Section 3 bring s a d escription of the proposed circu itry a nd hardware architectu re i n block le vel detail. In Section 4 strate gies for obtaining the FRS block ar e prop osed an d describ ed. Simulatio n results and actual test measu rements are re ported in Section 5. Concluding remarks are drawn in Section 6. 2 R E V I E W The AI enco ding was origin ally p roposed fo r digital signal processing systems by Cozz ens an d Finkelstein [ 46]. Since then it has been ad apted for the VLSI implemen tation of the 1-D DCT and other tr igonom etric tra nsforms by Julien et al. in [ 47 – 51], lea ding to a 1-D b iv ariate encoded Arai DCT algor ithm b y W ahid and Dimitr ov [ 37, 41, 42, 52]. Recently , sub sequent co ntributions by W ahid et al. (u sing b i variate encoded 1-D Ar ai DCT blocks for row and column transform s of the 2-D DC T) ha s led to practical area-efficient VLSI video processing circuits with low-power consump tion [53 – 55]. W e now briefly summarize the state-of -the-art in both 1-D and 2 -D DCT VLSI co res based on conv en tional fixed-p oint arithmetic as well as on AI encod ing. 2 . 1 S U M M A RY A N D C O M PA R I S O N W I T H L I T E R A T U R E 2 . 1 . 1 F I X E D - P O I N T D C T V L S I C I R C U I T S A u nified distributed-arithm etic parallel architectur e for the computation of DCT and the DST w as proposed in [ 24]. A direct-con nected 3- D VL SI architecture for the 2-D prime-factor DCT that d oes not need a tr anspose memory (buffer) is av ailable in [2 5]. A p ioneering implementatio n at a clock of 100 MHz on 0.8 µ m CMOS techno logy f or the 2-D DCT with block-size 8 × 8 which is suitable for HDTV applications is a vailable in [17]. An efficient VLSI linear-array f or bo th N -point DCT and IDCT using a subb and d ecompo sition algorithm that results in comp utational- and har dware-complexity of O ( 5 N / 8 ) with FPGA r ealization is reported in [20]. Recently , VLSI lin ear-array 2-D arch itectures and FPGA r ealizations having c omputatio n complexity O ( 5 N / 8 ) (f or fo rward DCT) was reported in [21]. An efficient adder-based 2- D DCT co re o n 0.3 5 µ m CMOS using cyclic conv olution is described in [29]. A high-p erforma nce video tran sform engine employing a sp ace-time scheduling sche me for com puting the 2-D DCT in real-time has been pro posed and im plemented in 0.18 µ m CMOS [22]. A systolic-array algo rithm using a memory 3 based d esign fo r bo th the DCT an d the discr ete sine transfor m which is suitable fo r real- time VLSI realization was propo sed in [18]. An FPGA-b ased system- on-chip realization of the 2- D DCT for 8 × 8 b lock size that operates at 107 MHz with a latency o f 80 cycles is available in [28]. A low-complexity IP core for quan tized 8 × 8 / 4 × 4 DCT combined with MPEG4 codecs and FPGA synthesis is av ailable in [30]. “New distrib u ted-arithme tic ( NED A)” based low-po wer 8 × 8 2-D DCT is rep orted in [31]. A recon figurable processor on T SMC 0 .13 µ m CMOS tec hnolog y operating at 100 MHz is described in [32] f or the calculation of the fast Fourier tran sform and th e 2 -D DCT . A high-spee d 2-D tra nsform a rchitecture b ased o n NE D A technique and having un ique kernel for multi- standard v ideo processing is described in [33]. 2 . 1 . 2 A I - BA S E D D C T V L S I C I R CU I T S The following AI-based re alizations o f 2-D DCT comp utation r elies on the row- and column -wise ap plication of 1-D DCT cores that employ AI q uantization [ 47–51]. Th e arch itectures pr oposed b y W ahid e t al. rely on the low- complexity Arai Algo rithm and lea d to low-po wer r ealizations [41, 42, 52 – 5 4]. Howe ver , these re alizations also are based on r epeated ap plication a long row and co lumns of an fu ndamen tal 1 -D DCT building b lock having an FRS section at the output stage. Her e, 8 × 8 2-D DCT ref ers to the u se of bivariate encod ing in the AI basis and no t to th e a true AI-based 2-D DCT operation . A 4 × 4 ap proxima te 2-D-DCT u sing AI qua ntization is r eported in [56]. Bo th FPGA implem entation an d ASI C synthesis o n 9 0 n m CMOS results are provid ed. Althou gh [5 6] emp loys AI encodin g, it is not an e rror-free architecture . The low complexity of this architecture makes i t su itable for H.264 realizations. 2 . 2 P R E L I M I N A R I E S F O R A L G E B R A I C I N T E G E R E N C O D I N G A N D D E C O D I N G In or der to prevent quantizatio n no ise, we ado pt the AI repr esentation. Such representatio n is based on a m apping function that links input numbers to integer arrays. This topic is a m ajor and classic field in number theor y . A famous exposition is due to Hardy and Wright [ 57, Chap. XI and XIV], which is widely regarded as masterpiece o n t h is subject for its clarity and depth. Poh st also bring s a didactic explanation in [58] with emphasis on computation al realizatio n. In [59, p. 7 9], Pollard and D iamond de vote an entire ch apter to the connectio ns b etween alg ebraic integers and integral ba sis. In the fo llowing, we f urnish an overview focused on the practical aspects of AI, which may be useful for circuit designers. Definition 1 A r eal or c omplex n umber is ca lled an algebr aic inte ger if it is a r oot of a monic polynomial with integ er coefficients [38, 57]. The set o f a lgebraic integers have useful math ematical proper ties. For in stance, they form a co mmutative r ing, which means that addition and multiplication operations are commutative and also satisfies distribution o ver addition. A general AI encoding mapping has the following f ormat f enc ( x ; z ) = a , where a is a multidimen sional ar ray of integers and z is a fixed multidim ensional array of alg ebraic integers. I t can be shown that there always exist integers su ch th at any rea l num ber can be r epresented with arb itrary pr ecision [46]. Also there are real numb ers that can be represen ted without err or . 4 Decoding operation is furnished by f dec ( a ; z ) = a • z , where the binary operation • is the generalized inner p roduc t — a compo nent-wise inner produc t o f multidimensional arrays. Th e elem ents of z con stitute the AI ba sis. In h ardware, deco ding is often p erform ed by an FRS b lock, wh ere the AI basis z is represented as precisely as require d. As a n examp le, let the AI basis be such that z = h 1 z 1 i T , wher e z 1 is th e algebraic integer √ 2 and the superscript T denotes the tran sposition op eration. Thus, a possible AI e ncoding mapping is f enc ( x ; z ) = a = h a 0 a 1 i T , wher e a 0 and a 1 are integers. En coded numb ers a re then represented by a 2-p oint vector o f integers. Decoding operation is simply giv en by the usu al inn er pr oduct: x = a • z = a 0 + a 1 z 1 . For examp le, th e number 1 − 2 √ 2 h as th e fo llowing encodin g: f enc 1 − 2 √ 2; " 1 √ 2 #! = " 1 − 2 # , which is an exact representatio n. In p rinciple, any num ber can be represented in an arb itrarily high precision [ 46, 60]. Howe ver , within a limited dynamic ran ge for the em ployed integers, n ot all numb ers can be exactly enc oded. For instance, considerin g the real number √ 3, we have f enc ( √ 3; h 1 √ 2 i T ) = h 88 − 61 i T , wh ere integers were limited to b e 8-b it lon g. A lthough very close, the representation is not e xact: f dec " 88 − 61 # ; " 1 √ 2 #! − √ 3 ≈ 9 . 21 × 10 − 4 . In a similar way , the m ultipliers required by the DCT could b e e ncoded into 2 -point inte ge r vectors: f enc ( c [ n ] ; z ) = h a 0 [ n ] a 1 [ n ] i T . Given that the DCT co nstants are alg ebraic in tegers [38], an exact AI re presentation can be de - riv ed [61]. Thus, the integer sequences a 0 [ n ] and a 1 [ n ] can be easily realized in VLSI hardware. The m ultiplication be tween two numbers represen ted over a n AI basis may be interpreted as a modu lar polyn omial multiplication with respect to the monic poly nomial th at defines the AI b asis. In the above par ticular illustrative example, consider th e mu ltiplication of the fo llowing pair of number s a 0 + a 1 z 1 with b 0 + b 1 z 1 , wher e b 0 and b 1 are integers. This operation is equiv alen t to the co mputation of the following expression : ( a 0 + a 1 x ) · ( b 0 + b 1 x ) ( mo d x 2 − 2 ) . Thus, existing algorithms for f ast po lynomial multiplication may be of consideration [62, p. 311]. In p ractical terms, a good AI r epresentation possesses a basis such that: (i) the requir ed constants c an be repre- sented without error; (ii) the integer elem ents provided b y the repr esentation are su fficiently small to allow a simple architecture desig n an d fast signal p rocessing; an d (iii) the basis itself con tains few elements to facilitate simple encodin g-decod ing operation s. Other AI procedu res allow the co nstants to be appr oximated, yieldin g much better op tions fo r enco ding, at the co st of introdu cing er ror within the transfor m (befor e the FR S) [ 38]. 5 T able 1: 2-D AI enco ding of Arai DCT constants c [ 4 ] c [ 6 ] c [ 2 ] − c [ 6 ] c [ 2 ] + c [ 6 ] 0 0 0 1 0 1 − 1 0 0 0 2 0 0 2 0 0 2 . 3 B I V A R I AT E A I E N C O D I N G Dependin g on the DCT a lgorithm e mployed, o nly the cosine of a few a rcs are in fact r equired. W e adopted the Arai DCT algorithm [43]; and the required elements for this particular 1-D DCT method are only [37, 41, 42]: c [ 4 ] = cos 4 π 16 , c [ 6 ] = cos 6 π 16 , c [ 2 ] − c [ 6 ] = c os 2 π 16 − cos 6 π 16 , c [ 2 ] + c [ 6 ] = c os 2 π 16 + cos 6 π 16 . These particular values can be conv enien tly e ncoded as follows. Considering z 1 = p 2 + √ 2 + p 2 − √ 2 and z 2 = p 2 + √ 2 − p 2 − √ 2, we adopt the following 2-D array for AI enco ding: z = " 1 z 1 z 2 z 1 z 2 # . This leads to a 2-D encod ed coefficients of the form (scaled by 4): f enc ( x ; z ) = a = " a 0 , 0 a 1 , 0 a 0 , 1 a 1 , 1 # . Such en coding is referred to as bivariate. For this s pe cific AI basis, the required cosine v alues possess an error-free and sparse representation as giv en in T able 1 [37, 4 1, 42]. Also we n ote that this representation utilizes very small integers and therefore i s suitable for fast arithm etic computation. Mo reover , these employed integers are powers o f tw o, which require no hardware components other than wired-shifts, being cost-free. Encodin g a n arbitrary real number can be a sophisticated oper ation req uiring the usag e of look-u p tab les and greedy algorithm s [63]. Essentially , an exhau sti ve sear ch is require d to obta in th e most accura te repr esentation. Howe ver , integer numbers can be encoded ef fortlessly: f enc ( m ; z ) = " m 0 0 0 # , (1) where m is an integer . I n this case, the encodin g step is un necessary . Our prop osed d esign takes advantage of th is proper ty . For a gi ven encoded number a , the decoding operation is simply e xp ressed by: f dec ( a ; z ) = a • z = a 0 , 0 + a 1 , 0 z 1 + a 0 , 1 z 2 + a 1 , 1 z 1 z 2 . 6 c 3 c 0 c 2 c 6 c 5 c 7 6 d d 7 d 2 d 5 d 3 d 1 x 7,k 6,k x x 5,k x 2,k X 0,k (a) X 4,k (a) X 6,k (d) X 6,k (a) X 2,k (a) X 2,k (d) 3,k (b) X 3,k (c) X X 3,k (a) X 3,k (d) 5,k (c) X 5,k (b) X X 5,k (a) X 5,k (d) X 7,k (c) X 7,k (b) X 7,k (a) X 7,k (d) X 1,k (c) X 1,k (b) X 1,k (a) X 1,k (d) x 3,k b 0 b 5 b 4 b 1 b 2 x 4,k b 6 b 3 b 7 c 1 c 4 d 0 <<1 <<1 d 4 d 8 1,k x < 1 that satisfies the follo wing minimization problem : α ∗ = arg min α > 1 k α · ζ − ro und ( α · ζ ) k , (19) where k · k is a given error m easure and round ( · ) is the ro unding f unction. W e a dopt the Euclidean n orm as the error measure. The presence of the rou nding fu nction introd uces several algebraic difficulties. A closed-f orm solution for (19) is a no n-trivial ma nipulation . Thus, we may r esort to compu tational search. Clearly , ad ditional restriction s must be imposed: a limited search space and a given precision for α . In the range α ∈ [ 1 , 256 ] with a precision of 10 − 4 , we could find the optimal value α ∗ = 167 . 2 309. T hus, we ha ve the following s calin g: α ∗ · z 1 z 2 z 1 z 2 = 436 . 99 5521 744185 . . . 181 . 00 9471 802748 . . . 473 . 00 0544 29861 . . . ≈ 437 181 473 . The error norm is approx imately 1 0 − 2 , which is very lo w for this type of pro blem. Howe ver , notice that small values of α are desira ble, since th ey co uld scale ζ into small integers, which requ ire a simple h ardware desig n. An an alysis on the su b-optimal solutions for (19) shows th at α ′ = 4 . 59 61 fu rnishes the 16 T able 3: Bo oth encoding of the expansion f acto rs α α Representation 4.596 1 2 2 + 2 − 1 + 2 − 4 + 2 − 5 + 2 − 9 167.2 309 2 7 + 2 5 + 2 3 − 2 0 + 2 − 2 − 2 − 6 − 2 − 8 following scaling: α ′ · z 1 z 2 z 1 z 2 = 12 . 010 3137 0924931 . . . 4 . 9748 3482 672658 . . . 12 . 999 8698 8195626 . . . ≈ 12 5 13 . In this case, the resulting integers are relati vely small and the error norm is in the order of 10 − 2 . Now we are in position to address the compu tation o f (14). Considerin g a giv en expansion factor α , we can write: X i , k = 1 α α · X i , k ( a ) + m 1 · X i , k ( b ) + m 2 · X i , k ( c ) + m 3 · X i , k ( d ) , (20) where m 1 , m 2 , and m 3 are the integer constants implied by the expansion factor α . In particular, th ese constants are { 437 , 1 81 , 473 } , for α = α ∗ , and { 12 , 5 , 13 } , for α = α ′ . N otice that (20) consists of a linear combination . Because co nstants m 1 , m 2 , and m 3 are in tegers, associate mu ltiplications c an b e efficiently im plemented in h ard- ware. Considerin g common subexpression elimination (CSE), these multiplications are reduced to additions and shift operation s, r equiring minimal amount of hardware resources. For the set { 437 , 1 81 , 473 } , we hav e the following CSE manipulatio n: 437 · Y i , k ( b ) + 181 · Y i , k ( c ) + 473 · Y i , k ( d ) = 473 · Y i , k ( b ) + Y i , k ( c ) + Y i , k ( d ) − 36 · Y i , k ( b ) + Y i , k ( c ) − 256 · Y i , k ( c ) . This computation requires only eight addition s. Analo gously , for th e set { 12 , 5 , 13 } , CSE yields: 12 · Y i , k ( b ) + 5 · Y i , k ( c ) + 13 · Y i , k ( d ) = 8 · Y i , k ( b ) + Y i , k ( d ) + 4 · Y i , k ( b ) + Y i , k ( c ) + Y i , k ( d ) + Y i , k ( d ) + Y i , k ( c ) . Fi ve addition s are necessary . Above calculations are represented by t h e integer coefficient blo ck in Fig. 7. The remaining multiplication in (20) is the one by α , which can be implemented according to the Booth encoding representatio n. T ab le 3 brings the required Booth encoding for α ∗ = 167 . 2 309 and α ′ = 4 . 596 1. The glob al multiplication b y 1 / α is not prob lematic. I ndeed, it can be embedd ed in to subsequen t signal p rocessing 17 Combinational Circuitry Integer Coef. Linear Combination X i , k ( a ) ( a ) X i , k ( a ) ( b ) X i , k ( a ) ( c ) X i , k ( a ) ( d ) X i , k ( b ) ( a ) X i , k ( b ) ( b ) X i , k ( b ) ( c ) X i , k ( b ) ( d ) X i , k ( c ) ( a ) X i , k ( c ) ( b ) X i , k ( c ) ( c ) X i , k ( c ) ( d ) X i , k ( d ) ( a ) X i , k ( d ) ( b ) X i , k ( d ) ( c ) X i , k ( d ) ( d ) α · X i , k Booth encoded α Y i , k ( a ) Y i , k ( b ) Y i , k ( c ) Y i , k ( d ) Figure 7: Block dia gram of the proposed AI decoding based on expansion factors. T able 4: Success rates of the DCT coefficient computation for v ar ious fixed-point bus widths L and tolerance le vels Percentage T olerance Design FRS Method L 10% 5% 1% 0.1% 0.05% 0.01% 0.005 % 1 Dempster-Macleod 4 99.96 72 99.9203 99.6422 96.3563 92.7109 64.84 06 42.1719 2 8 99. 9719 99.9344 99.6047 96.325 0 92.70 31 64 .7313 4 1.901 6 3 Expansion factor { 12 , 5 , 13 } 4 99.18 44 98.29 44 91.6 822 55. 1811 45 .0667 30.6 922 22.8 633 4 8 99. 1289 98 .2944 9 1.497 8 55.090 0 45.02 89 30 .7122 2 2.884 4 5 { 437 , 1 81 , 473 } 4 99.99 00 99.98 22 99.9 178 99. 1111 98 .2000 91.0 667 83.1 244 6 8 99. 9589 99 .9511 9 9.873 3 99.038 9 98.12 78 90 .9867 8 3.176 7 stages after the DCT operation . T y pically , it is absorb ed in to the quan tizer . This approa ch has been employed in sev eral DCT architectur es [69 – 7 1]. Fig. 7 depicts th e f ull block diag ram o f the discussed computing s ch eme. Eight s ep arate instances of this block ar e necessary to compu te co efficients X i , 0 to X i , 7 , for each i . 5 O N - F P G A T E S T A N D M E A S U R E M E N T Six design s w ere imp lemented on Xilinx ML605 ev alu ation kit which is pop ulated with a a Xilinx V irtex-6 XC6VLX240T device. The designs inclu ded the thre e imp lementations of the 2D 8 × 8 Ar ai AI DCT ar chitecture with the two typ es of FRS describ ed in Section 4 for fixed-point 4- an d 8- bit wordlengths. T wo versions of th e ex- pansion factor FRSs are provided, correspond ing to expan sion factors α ′ = 4 . 594 1 and α ∗ = 167 . 2 309, resulting in 6 designs in total. The pr oposed designs are listed in T ab le 4. The JT AG inter face was u sed to in put the test 8 × 8 2- D DCT arra ys to the device fr om th e M AT L A B workspa ce. Then the measure d outp uts were retu rned to th e M A T L A B workspace via the sam e inter face. H ardware c omputed coefficients were compare d to its numerical e valuation furnished by M A T L A B signal processing toolbo x. 18 Slice registers Design 1 Design 3 Design 5 Slice LUTs Design 1 Design 3 Design 5 7104 9628 5767 7286 7784 8839 Slices Design 1 Design 3 Design 5 2818 2377 2605 Frequency (MHz) Design 1 Design 3 Design 5 Design 1 Design 3 Design 5 Quies. power (W) Design 1 Design 3 Design 5 Dyn. power (W) Design 1 Design 3 Design 5 T otal power (W) Design 1 Design 3 Design 5 Design 1 Design 3 Design 5 130.41 309.885 312.402 2.740 2.773 2.740 0.897 1.871 0.912 3.637 4.643 3.652 21.61 7.67 8.34 0.213 0.025 0.028 area × time (slices · µ s) area × time 2 (slices · µ s 2 ) Figure 8: Resource utilization , speed o f operation , and power consum ption of the DCT designs given in T able 4 on Xilinx V irtex-6 XC6VLX24 0T FPGA for inpu t fix ed- point w or dlength L = 4. 19 Design 2 Design 4 Design 6 Slices 3618 3445 Design 2 Design 4 Design 6 Slice registers Design 2 Design 4 Design 6 Slice LUTs 12794 10384 12007 7168 10216 10282 3144 Frequency (MHz) Design 2 Design 4 Design 6 area × time (slices · µ s) Design 2 Design 4 Design 6 area × time 2 (slices · µ s 2 ) Design 2 Design 4 Design 6 Design 2 Design 4 Design 6 Quies. power (W) Design 2 Design 4 Design 6 T otal po wer (W) Design 2 Design 4 Design 6 Dyn. power (W) 123.12 300.391 307.787 2.742 2.786 2.747 0.957 1.687 1.123 3.699 4.453 3.870 29.38 10.446 11.19 0.239 0.034 0.036 Figure 9: Resource utilization , speed o f operation , and power consum ption of the DCT designs given in T able 4 on Xilinx V irtex-6 XC6VLX24 0T FPGA for inpu t fix ed- point w or dlength L = 8. 20 T able 5: Fr ame rates and block rates achie ved by the implemented designs for a video of resolution 1920 × 1080 Design Freq . (MHz) Block rate (MHz) Frame rate (Hz) 1 130 .410 16.30 503.0 8 2 123 .120 15.39 475.0 0 3 309 .855 38.73 1195. 37 4 300 .391 37.55 1158. 95 5 312 .402 39.05 1205. 25 6 307 .787 38.47 1187. 35 5 . 1 O N - CH I P V E R I FI C A T I O N U S I N G S U C C E S S R AT E S As a figur e of merit, we consider ed the success rate defined as the percentag e of coef ficients which are within the error limit of ± e %. For e = { 0 . 005 , 0 . 0 1 , 0 . 05 , 0 . 1 , 1 , 5 , 10 } , the success rates were measu red as gi ven in the T able 4. Inpu t wordlengths L was set to 4 or 8 bits. The 8-bit size is the ty pical video processing con figuration. Th e propo sed AI architecture s enjoy overflow-free bit-g rowth at eac h stage throu ghou t the AI enco ded structu re th ereby en suring th at all sour ces of err or are at the FRS a nd there only . Results show that the FRS based on the exp ansion factor appr oach for { 437 , 181 , 473 } ( Designs 5 and 6) offers a significant improvement in accuracy when compar ed to remaining FRS architecture s. 5 . 2 F P G A R E S O U R C E C O N S U M P T I O N The resource consumption of the proposed architectur es on Xilinx V irtex-6 XC6VLX240T de vice are sho wn in Fig. 8 for L = 4 bits. Fig. 9 brin gs analogou s info rmation for L = 8 b its. Here, FPGA resources are m easured in term s of slices, slice registers, a nd slice look- up-tables (L UTs). Designs 3 and 4 , which use the FRS ba sed on the expansion factor approach for { 12 , 5 , 13 } , consumed the least resources in the de vice and has the worst accuracy of the three de- signs (T ab le 4). Mo reover , even th ough Designs 5 and 6 (FR S based on expansion factor app roach for { 4 37 , 181 , 473 } ) possesses s up erior accuracy when compared to Designs 1 an d 2 (FRS based on Dempster -Macleo d metho d), th ey con- sume less h ardware resourc es. Overall the FRS step of the pro posed architectur es req uire a co nsiderable amoun t of area when compa red to the AI steps of the architecture. 5 . 3 C L O C K S P E E D , B L O C K R AT E , F R A M E R AT E Frame rates an d bloc k r ates achieved b y th e imp lemented designs fo r v ideo at r esolution 192 0 × 108 0 is shown in T able 5. T he d esign having the best th rough put was Design 5 , which operates on 4- bit inp uts. In Design 5 , the maximum 8 × 8 2 -D DCT blo ck rate is 39.05 MHz for a 312 .402 MHz clock. Assuming an inp ut vid eo resolutio n o f 1920 × 10 80 pixels p er frame, we ob tained a real-tim e computatio n of the 2-D 8 × 8 DCT at 1205 .25 fr ames per secon d. In Design 6, we d escribe the co mmon 8-b it inp ut c ase, where the clo ck is now sligh tly r educed to 307 .787 MHz, yielding an 8 × 8 block rate of 3 8.787 MHz, and a frame rate o f 1187.35 frames p er s eco nd for the same image s ize as above. In all cases, if the 2 -D DCT c ore is eventually embedd ed in a real-tim e video pro cessor , the p ixel rate is eigh t fold the clock frequ ency of the DCT core (due to the do wnsamp ling b y eight i n the signal flow gr aph). For e xa mple, a potential pixel rate of ≈ 2.499 GHz and ≈ 2.462 GHz, for Designs 5 and 6, may be possible. 21 5 . 4 X I L I N X P OW E R C O N S U M P T I O N A N D C R I T I C A L P AT H The total power consump tion o f FPGA c ircuits co nsist of th e sum of d ynamic and quiescent power co nsumption s. Both e stimated dyn amic and q uiescent power consum ptions obtained f rom the design tools fo r the Xilinx V irtex-6 XC6VLX240T device are provided in Fig. 8 and Fig. 9. 5 . 5 A RE A - T I M E C O M P L E X I T Y M E T R I C S Estimates for VL SI area- time com plexity m etrics are pr ovided for all d esigns are given in Fig. 8 ( L = 4) and Fig. 9 ( L = 8 ), respectively . In general, the ar ea-time metric measu res complexity of VLSI cir cuits where ch ip real-estate is importan t over speed, while metric ar ea-time 2 is used of ten fo r VLSI circuits whe re speed is o f paramo unt concern . W e provide bo th metrics to offer a broad overview of the area-time complexity levels presen t in the proposed architectu res as a functio n of input size and choice of FRS algorith m. The architectures are free of general purpose multipliers. 5 . 6 O V E R A L L C O M P A R I S O N W I T H E X I S T I N G A R C H I T E C T U R E S Fixed point VLSI implemen tations that are directly compar able to the prop osed architectu re are compa red in detail in T ab le 6. T a ble 7 bring s com parisons to AI-based arc hitectures. For br evity and with out loss of g enerality , we chose designs 2 and 6 for the pu rpose o f co mparison . These are aimed at 8-bit inpu t signals and are examp les of the Dem pster-Macleod and expansion factor FRS algorithms. A synopsis o f bo th fixed- point and AI-based 2D-DCT circuits under compariso n in T ables 6 and 7 was provided in Section 2. 6 C O N C L U S I O N S A time-multip lexed systolic-ar ray hardware architecture is p roposed for the rea l-time computatio n of the biv ariate AI encoded 2-D Arai DCT . The architecture is the first 2 -D AI e ncoded DCT har dware that operates completely in the AI domain. This not only makes th e proposed system completely multiplier-free, but also quantizatio n fre e u p to the final output channels. Our architectu re em ploys a novel AI -TB, which facilitates real-time data tran sposition. The 2 -D separa ble DCT operation is entirely pe rformed in the AI domain . Indee d, the ar chitecture do es not have intermed iate FRS sections between the colu mn- and r ow-wise AI-based Arai DCT o perations. This m akes the q uantization noise on ly appear at the final outpu t s tag e of the architecture: the single FRS section. The location of the FRS at the final o utput stage results in the com plete decoup ling of quantization noise between the 6 4 p arallel co efficient ch annels of th e 2- D DCT . This fact is noteworthy becau se it enables the indepen dent selection of precision fo r eac h of the 6 4 c hannels witho ut h aving any e ffect on the speed, power , c omplexity , or no ise level of the remaining chann els. T wo algorithms for the FRS are p roposed , n umerically optimized , analyz ed, hardware implem ented, and tested with the prop osed 2-D AI en coded section. The ar chitectures are phy sically impleme nted for inpu t pr ecision of 4 and 8 bits, and fu lly verified on- chip. Of particu lar relev ance is the commo nly re quired 8- bit realization , wh ich is operation al at a clock frequen cy of 3 07.78 7 MHz on a Xilin x V irtex-6 XC6VLX240T FPGA device (see Design 6 ). This implies a 8 × 8 block rate of 3 8.47 MHz and a potential pixel rate of ≈ 2.462 GHz if the propo sed 2- D DCT core is embed ded in a real-time vide o processing system. The fram e rate for standard HD v ideo at 192 0 × 1 080 resolution is ≈ 1187 .35 Hz assuming 8-bit input words and core clock frequency of 307. 787 MHz. 22 T able 6: Co mparison of the proposed implementation with published fixed point implemen tations Lin e t al. [32] Shams et al. [31] Madisetti et al. [17] Guo et al. [29] T umeo et al. [28] Sun et al. [30] Chen e t a l. [22] Proposed architectures Design 2 Design 6 Measured results No No No No No No No Y es Y es Structure Single 2-D DCT T wo 1-D DCT +TMEM † Single 1-D DCT +TMEM † Single 1-D DCT +TMEM † Single 1-D DCT +TMEM † T wo 1-D DCT +TMEM † Single 1-D DCT +TMEM † See Fig. 3 See Fig. 3 Multipliers 1 0 7 0 4 0 0 0 0 Operating frequen cy (MHz) 100 N/A 100 11 0 107 1 49 16 7 123.1 2 3 07.79 8 × 8 Block rate × 10 6 s − 1 1.562 5 N/A 1.562 3.437 5 1.3375 2.328 2.609 15.39 ∗ 38.62 5 ∗ Pixel rate × 10 6 s − 1 100 N/A 100 22 0 85.6 149 1 67 984.9 6 ‡ 2462. 32 ‡ Implemen tation technolog y 0.13 µ m CMOS N/A 0.8 µ m CMOS 0.35 µ m CMOS Xilinx XC2VP30 Xilinx XC2VP30 0.18 µ m CMOS Xilinx XC6VLX240T Xilinx XC6VLX240T Coupled quantiza- tion noise Y es Y es Y es Y es Y es Y es Y es No No Indepe ndently adjustable precision No No No No No No No Y es Y es † Row column transpose buf fer . ∗ Block rate = F cl ock / 8. ‡ Pixel rate = F s . 23 T able 7: Compar ison of the prop osed impleme ntation with published algebraic in teger implem en- tations Nandi et al. [56] Jullien et al. [50] W a hid et a l. [55] Proposed architectures Design 2 D esign 6 Measured results No No No Y es Y es Structure Single 1-D DCT +Mem. bank T wo 1-D DCT +Dual port RAM T wo 1-D DCT +TMEM † See Fig. 3 See Fig. 3 Multipliers 0 0 0 0 0 Exact 2D AI computatio n No No No Y es Y es Operating frequen cy (MHz) N/A 75 194. 7 123.1 2 307.7 9 8 × 8 Block rate × 10 6 s − 1 7.812 5 1.171 3.042 15. 39 ∗ 38.62 5 ∗ Pixel rate × 10 6 s − 1 125 75 194.7 984.9 6 ‡ 2462. 32 ‡ Implemen tation technolog y Xilinx XC5VLX30 0.18 µ m CMOS 0.18 µ m CMOS Xilinx XC6VLX240T Xilinx XC6VLX240T Coupled quantization noise Y es Y es Y es No No Indepe ndently adjustable precision No No No Y es Y es FRS between row-column stages No Y es Y es No No † Row column transpose buf fer . ∗ Block rate = F cl ock / 8. ‡ Pixel rate = F s . 24 The propo sed architectu re achieves complete e limination of quantizatio n noise couplin g between DCT co efficients, which is pr esent in published 2-D DCT ar chitectures based on b oth fixed- point ar ithmetic as well as row-colum n 8 - point Arai DCT cores that ha ve FRS sections between r ow- a nd co lumn-wise transfor ms. Th e pro posed designs allows each of the 64 coefficients to be comp uted at 64 different precision levels , where each choice of precision only af fects that particu lar coefficient. This allows fu ll control of the 2 -D DCT comp utation to any degree of precision d esired by the designer . A C K N OW L E D G M E N T S This work was partially s up ported by CNPq and F A CEPE. R E F E R E N C E S [1] H.-Y . Lin and W .-Z . Chang, “High dynamic range imaging for stereoscopic scene r epresentation, ” in Proceed ings of the 16th IEEE International Confer ence on Image Pr ocessing (ICIP) , Nov . 2009, pp. 4305–4308 . [2] W .-C. Kao, “High dynamic range i maging by fusing multiple raw images and tone reproduction, ” IE EE T ransactions on Consumer Electr onics , vol. 54, no. 1, pp . 10–15, Feb . 2008. [3] P . Carrillo, H. Kalva , and S. Magliv eras, “Compression independent re versible encryption for pri vac y in video surv eill ance, ” EURASIP J ournal on Information Security , v ol. 2009, pp. 1–13, 2009. [4] C.-F . Chiasserini and E . Magli, “Ene rgy co nsumption and i mage quality in wireless video-surveillance networks, ” in Pr oceed- ings of the 13th IEEE International Symposium on P ersona l, Indoor and Mobile Radio Communications , vol. 5, Sep. 2002, pp. 2357–2 361. [5] E. Magli and D. T aubman, “Image compression practices and standards f or geospatial information systems, ” in Procee dings of the 2003 IEEE International Geoscience and Remote Sensing Symposium , vol. 1 , Jul. 2003, pp. 654 –656. [6] M. Bramber ger, J. Brunne r, B. Rinner , and H. Schw abach, “Real-time video analysis on an embed ded smart camera for traf fic surveillance, ” i n Pro ceedings of t he 10th I EEE Real-T ime and Embed ded T echnolo gy and Applications Symposium , May 2004, pp. 174–18 1. [7] T . T ada, K. Cho, H. S himoda, T . Sakata, and S. Sobue, “ A n e valuation of JPEG compression for on-line satelli te images transmission, ” in Proc eedings of the International Geoscience and Remote Sensing Symposium (IGARSS) , Aug. 1993, pp. 1515–1 518. [8] A. S . Dawood, J. A. Williams, and S. J. V isser, “On-board satellite i mage compression using reconfigurable FPGAs, ” in Pr oceedings of the IEEE International Confer ence on Field-Pr ogr ammable T echnolo gy , Dec. 2002, pp. 306–3 10. [9] J. Schie we, “Effect of lossy data compression techniqes on geometry and information content of satellite imagery , ” i n Pro - ceedings of t he ISPRS Commission IV Symposium on GIS - Between isions and Applications , D. Fri tsch, M. Englich, and M. Sester , Eds., vol. 32, Stuttgart, German y , 1998. [10] B. Bennett, C . Dee, and C. Meyer , “Emerging methodologies in encoding airborne sensor video and metadata, ” in Pro ceedings of the 2009 IEEE Military Communications Confer ence , Oct. 2009, pp. 1–6. [11] J. W ang and Y . Song, “Hardware design of video compression system in the UA V based on the ARM technology , ” in Pr o- ceedings of the 2009 International Symposium on Computer Network and Multimedia T echno logy , Jan. 2009, pp. 1–4. [12] B. Bennett, C. Dee, M.-H. Nguyen, and B. Hamilton, “Operational conc epts of MPE G-4 H. 264 for t actical DoD ap plications, ” in Pr oceedings of the IEEE Military Communications Confer ence , vol. 1, Oct. 2005, pp. 155–161 . 25 [13] S. Marsi, G. Impoco, A. Uko vich, S. Carrato, and G. Ramponi, “V ideo enhancement and dynamic range control of HDR sequences for automoti ve applications, ” EURASIP J ournal on Advances in Signal Pro cessing , vol. 2007, pp. 1–9, 2007. [14] I. F . Akyildiz, T . Melodia, and K. R. Chowd hury , “ A surv ey on wireless multimedia sensor networks, ” Computer Networks , vol. 5 1, no. 4, pp. 921 –960, 2007. [15] R. W estwater and B. Furht, R eal-time video compr ession: techn iques and algorithms , ser . K luwer international series in engineering and computer science. Kluwer , 1997. [16] T . Suzuki and M. Ikehara, “Integer DCT based on direct-lift ing of DCT -IDCT for lossless-to-lossy image coding, ” IEEE T ransaction s on Imag e P r ocessing , vol. 1 9, no. 11, pp. 2958– 2965, Nov . 2010. [17] A. Madisetti and A. N. Willson, “ A 100 MHz 2-D 8 × 8 DCT -IDCT processo r for HDTV applications, ” IEEE T ransaction s on Cir cuits and Systems for V i deo T ech nology , vol. 5, no. 2, pp. 158–165 , Apr . 1995. [18] D. F . Chiper , M. Swamy , M. O. A hmad, and T . Stouraitis, “Systolic algorithms and a memory-based design approach for a unified architecture for the computation of DCT -DST -IDCT -IDST, ” IEEE Tr ansactions on Circuits and Systems I: Regula r P apers , vo l. 52, no. 6, pp. 1125– 1137, Jun. 2005. [19] P . K. Meher and M. N. S. Swamy , “Ne w sy stolic algorithm and array architecture for prime-length discrete Fourier tran sform, ” IEEE T ransactions on Cir cuits and Systems II: Expr ess Briefs , vol. 54, no. 3, pp. 262 –266, Mar . 2007. [20] T .-Y . Sung, Y .-S. S hieh, and H.-C. Hsin, “ An efficient VLSI linear arr ay for DCT/IDCT using subband decomposition algo- rithm, ” Mathematical Problems in Engineering , vol. 2010, pp. 1– 21, 2010. [21] H. Huang, T .-Y . Sung, and Y .-S. Shieh, “ A novel VLSI linear array for 2-D DCT-IDCT, ” in Pr oceeding s of 201 0 3r d Interna- tional Congr ess on Image and Signal Pr ocessing (CISP’2010) . IEEE, 2010, pp. 3686–369 0. [22] Y .-H. Chen and T .- Y . Chang, “ A high performance video t ransform engine by using space-time scheduling stratergy , ” IEEE T ransaction s on V ery Larg e Scale Inte gration (VLSI) Systems , Forthcoming in 2011. [23] P . K. Meher , J. C. Patra, and A. P . V inod, “ A 2-D systolic array for high-throughput computation of 2-D discrete Fourier transform, ” in P r oceedings of IEEE Asia P acific Confer ence on Circu it s and Systems (APCCAS’2006) , 2006. [24] P . K. Meher , “Unified DA-based parallel architecture for compting the DCT and t he DST, ” in Pro ceedings of the 5th IEEE International Confer ence on Information, Communications, and Signal Pro cessing , 2005, pp. 1278–1282. [25] S. Nayak and P . Meher , “3-dimensional systolic architecture for parallel VLSI implementation of the discrete cosine trans- form, ” IE E Pr oc.- Cir cuits Devices and Syst. , vol. 1 43, no. 5, pp. 255–258, Oct. 1996. [26] P . K. Me her, “ Highly concurrent red uced-complexity 2-D systolic array for d iscrete Fourier transfo rm, ” IEEE Sign al Pr ocess- ing Letters , v ol. 13, no. 8, pp. 481–484, A ug. 2006. [27] P . K. Meher and J. Patra, “ A ne w con volutiona l formulation of discrete cosine transform for systolic implementation, ” in Pr oceedings of IEEE International Conferen ce on Information, C ommunications, and Systolic Implementation , 2007, pp. 1–4. [28] A. Tu meo, M. Monchiero, G. Palermo, F . Ferrandi, and D. Sciuto, “ A pipelined fast 2D-DCT accelerator for FPG A-based SoCs, ” in Pr oceedings of IEEE Computer Society Annua l Symposium on VLSI (ISVLSI’07) , 2007. [29] J.-I. Guo, R.-C. Ju, and J.-W . Chen, “ An efficient 2-D DCT /IDCT core design using cyclic con volution and adder-based realization, ” IE EE T ransactions on Cir cuits and Systems for V ideo T ech nology , vol. 14, no. 4, pp. 416–428 , Apr . 2004. [30] C.-C. S un, P . Donner , and J. Gotze, “Low-comple xity multi-purpose IP core for quantized discrete cosin and integer trans- form, ” in In Proc eedings of 2009 IE EE Intl. Symp. on Cir cuits and Systems (ISCAS’09) , 2009, pp. 3014–3017 . [31] A. M. S hams, A. Chidanandan, W . Pan, and M. A. Bayoumi, “NED A: A low-po wer high-performan ce DCT architecture, ” IEEE T rans o n Signal Pr ocessing , vo l. 3, no. 3, pp. 955 –964, Mar . 2006. 26 [32] C.-T . Lin, Y .-C. Y u, and L.-D. V an, “Cost-effecti ve triple-mod e reconfigurable pipeline FFT/IFFT/2-D DCT processor , ” IEEE T ransaction s on V ery Larg e Scale Inte gration (VLSI) Systems , vol. 16, no. 8, pp. 1058– 1071, Aug. 2008. [33] C.-Y . Huang, L. -F . Chen, and Y .-K. Lai, “ A high-speed 2-D transform architecture with unique kernel for multi-standard video applications, ” in P r oceedings of IEEE 2008 Intlernational Symposium on Cir cuits and Systems (ISCAS’2008) , 2008, pp. 21–24. [34] A. V . Oppenheim and C. J. W einstein, “Effects of finite register length in digital fi ltering and the fast Fourier t ransform, ” Pr oceedings of the IEEE , vol. 60, no. 8, pp. 957 –976, Aug. 1972. [35] K. Ihsberne r, “Roundof f error analysis of fast DC T algorithms in fixed point arithmetic, ” Numerical A lgorithms , vol. 46, pp. 1–22, 2007. [Online]. A vailable: http://dx.doi.org/10.10 07/s11075- 007- 9123- 1 [36] V . S. Dimitrov , G. A. Jullien, and W . C. Miller , “ A ne w DCT algo rit hm based o n encoding algebraic inte gers, ” in Pr oceedings of the 1998 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , vol. 3, May 19 98, pp. 1377– 1380. [37] K. W ahid, “Error-free implementation of the discrete cosine transform, ” Ph.D. dissertation, Univ ersity of Cal gary , 2010. [38] R. Baghaie and V . Dimitrov , “Systolic implementation of real-valued discrete transforms via algebraic integer quantization, ” Computers and Mathematics with Applications , vo l. 41, pp. 1403–1416, 2001. [39] H. A. Peterson, A. J. Ahumada , and A. B. W atson, “The visibility of DCT quantization noise, ” SID Internationa l Symposium Digest Of T echnical P apers , vol. 24 , p. 942, 1993. [40] M. A. Robertson and R. L. St e venson, “DCT quantization noise in compressed images, ” IEE E Tr ansactions on Circu it s and Systems for V ideo T echnolog y , vol. 1 5, no. 1, pp. 27– 38, Jan. 2005 . [41] V . Dimitrov , K. W ahid, and G. Jullien, “Multiplication-free 8 × 8 2D DCT architecture using algebraic integer enco ding, ” IEE Electr onics Letters , vol. 4 0, no. 20, pp. 1310– 1311, 2004. [42] V . Dimitrov and K. W ahid, “On the error-free computation of fast cosine transform, ” International Journ al: Information Theories and Applications , vol. 1 2, no. 4, pp. 321 –327, 2005. [43] Y . Arai, T . Agui, and M. Nakajima, “ A fast DCT -SQ scheme for images, ” IEI CE T ransa ctions , vol. E71-E, no. 11, pp. 1095– 1097, 1988. [44] V . Britanak, P . Y ip, and K. R. Rao, Discr ete Cosine and Sine T rans forms . Academic P ress, 2007 . [45] “Xilinx, inc. corporate website, ” 2011 . [Online]. A va il able: http:// www .xil inx.com/ [46] J. H. Cozzens and L. A. F inkelstein, “Range and error analysis for a fast F ourier transform computed over Z [ ω ] , ” IE EE T ransaction s on Information Theory , vo l. IT -33, no. 4, pp. 582–590, Jul. 1987. [47] M. F u, V . S. Dimitrov , and G. Jullien, “ An efficient technique for error-free algebraic-integ er encoding for high performance implementation of the DCT and IDCT, ” in Proce edings of the IEEE 2001 Internationa l Symposium on Circuits and Systems (ISCAS’01) , 2001. [48] M. Fu, G. Jullien, V . S. Dimitro v , M. Ahmadi, and W . Miller , “Implementation of a n error-free DCT using a lgebraic integers, ” in Pr oceedings of the Micr onet Annual W orkshop , 2002. [49] ——, “The application of 2D algebraic integer encoding t o a DCT IP core, ” in Proc eedings of the 3r d IEEE International W orkshop on System-on-Chip for Real-T ime Applications , Calgary , AB, CA, 2002, pp. 66–69. [50] M. Fu, G. A. Jullien, V . S. Dimitro v , an d M. Ahmadi, “ A Low-Po wer DCT IP Core base d on 2D Algeb raic Integer Encoding, ” in Proce edings of the 2004 International Symposium on Circuits and Systems, 2004 (ISCAS ’04) , vol. 2, May 2004, pp. 765–76 8. [51] M. Fu, G. Jullien, and M. Ahmadi. (2004, F eb .) Al gebraic integer encoding and applications in discrete cosine transform. Online. Gennum Presentation by Dept. ECE, Univ ersity of Windso r, Canada. [Online]. A vailable: http://www .docstoc.com/do cs/74259941/Algebraic- Integer - Encoding-an d- Appl ications- in- Discrete- Cosine 27 [52] K. W ahid, S. B. K o, and V . S. Dimitro v , “ Area and po wer ef ficient video com pressor for en doscopic capsules, ” in Pr oceedings of 4th International Confer ence on Biomedical Engineering , Kuala Lumpur , Jun. 2008. [53] K. W ahid, “ An efficient IEE E-compliant 8 × 8 Inv-DCT architecture wi th 24 adders, ” IEEE T ransaction s on Electr onics, Information and Systems , vo l. 131, pp. 1081 –1082, 2011. [54] T . H. Khan and K. A. W ahid, “Lossless and lo w-power image co mpressor for wireless capsule endoscop y , ” VLSI Design , v ol. 2011, p. 12, 2011. [55] K. A. W ahid, M. Martuza, M. Das, and C . McCrosky , “Ef ficient hardware implementation of 8 × 8 integer cosine transforms for multiple video codecs, ” Journa l of Real-T ime Pr ocessing , pp. 1–8, Jul. 2011. [56] S. Nandi, K. Rajan, and P . Biswas, “Hardware implementation of 4 × 4 DCT quantization block using multiplication and error-free alg orithm, ” in 2009 IEEE TE NCON Re gion 10 , 2009 , pp. 1–5. [57] G. H. Hardy and E. M. Wright, An Intr oduction to the Theory of Numbers , 4th ed. London: Oxford Unive rsit y Press, 1975. [58] M. E. Pohst, Computational Algebr aic Number Theory . Basel, Switzerland: Birkh ¨ auser V erlag, 1993. [59] H. Pollard and H. G. Diamond, T he Theory of Algebraic Numb ers , 2nd ed., ser . The Carus Mathematical Monograph s. The Mathematical Association of America, 1975, no. 9. [60] J. H. Cozzens and L. A. Finkelstein, “Computing the discrete Fourier transform using residue number systems in a ring of algebraic integer , ” IEEE T ransactions on Information Theory , vol. IT -31, no. 5, pp. 580–588 , Sep. 1985. [61] A. Madanayak e, R . J. Cintra, D. Onen, V . S. Dimitrov , and L. T . Bruton, “ Algebraic integer based 8 × 8 2-D DCT archi- tecture for digital video processing, ” i n Pr oceedings of the IEEE 2011 International Symposium on Circu its and Systems (ISCAS’2011) , May 2011. [62] R. E. Blahut, F ast Al gorithms for Sign al Pr ocessing , Cambridge, UK, 2010. [63] V . Dimitrov , G. A. Jullien, an d W . C. Miller , “Eisenstein residue number system with app li cations to DSP, ” in Pr oceedings of the 40th Midwest Symposium on Cir cuits and Systems , 1997. [64] K. W ahid, V . Dimitrov , and G. Jullien, “Error-free computation of 8 × 8 2D DCT and IDCT using t wo-dimens ional algebraic integer quantization, ” in Pr oceedings of the 17th IE EE Symposium on Computer Arithmetic . IEEE Computer Society , Jun. 2005, pp. 214–221 . [65] U. Meyer -Base and F . T aylor , “Optimal algebraic integer implementation with application to complex frequenc y sampling filters, ” IEEE Tr ansactions on Cir cuits and Systems II: A nalog a nd Digital Sign al P r ocessing , v ol. 48, no. 11, pp. 10 78–1082, 2001. [66] A. G. Dempster and M. D. Macleod, “Constant integer multiplication using minimum adders, ” IEE Proceed ings - Circuits, Devices and Systems , v ol. 141, no. 5, pp. 407–413, Oct. 1994. [67] O. Gustafsson, A. G. Dempster, K. Johansson, M. D . Ma cleod, and L. W anhammar , “Simplified desig n of con stant coefficient multipliers, ” Cir cuits, Systems, and Signal Pr ocessing , vol. 25 , no. 2, pp. 225– 251, Apr . 2006. [68] G. P lonka, “ A global method for in vertible integer DC T and i nteger wav elet al gorithms, ” Applied and Computational H ar- monic Analysis , vol. 1 6, no. 2, pp. 79–1 10, Mar . 2004. [69] R. J. Cintra an d F . M. Bayer , “ A DCT approx imation for image compression, ” IEE E Signal Pr ocesing Letters , vol. 18 , no. 10, pp. 579–58 3, Oct. 2011. [70] S. Bouguezel, M. O. Ahmad, and M. N. S. Swamy , “Low-comple xity 8 × 8 transform for image compression, ” Electro nics Letters , v ol. 44, no. 21, pp. 1249–1250, Sep. 2008. [71] ——, “ A low-com plexity parametric transform for image compression, ” in Pr oceeding s of the 2011 IEEE Internationa l Sym- posium on Cir cuits and Systems , 2011. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment