An evaluation framework for event detection using a morphological model of acoustic scenes
This paper introduces a model of environmental acoustic scenes which adopts a morphological approach by ab-stracting temporal structures of acoustic scenes. To demonstrate its potential, this model is employed to evaluate the performance of a large set of acoustic events detection systems. This model allows us to explicitly control key morphological aspects of the acoustic scene and isolate their impact on the performance of the system under evaluation. Thus, more information can be gained on the behavior of evaluated systems, providing guidance for further improvements. The proposed model is validated using submitted systems from the IEEE DCASE Challenge; results indicate that the proposed scheme is able to successfully build datasets useful for evaluating some aspects the performance of event detection systems, more particularly their robustness to new listening conditions and the increasing level of background sounds.
💡 Research Summary
**
The paper presents a novel evaluation framework for acoustic event detection that is built upon a morphological model of environmental acoustic scenes. Recognizing the rapid growth of large‑scale audio recordings in fields such as eco‑acoustics and urban sound monitoring, the authors note that existing evaluation practices rely heavily on manually recorded and annotated datasets, which are costly to acquire and often lack sufficient variability. To address this gap, they propose a “source‑driven” simulation approach that abstracts the temporal structure of a scene into a skeleton of discrete events laid over a background texture.
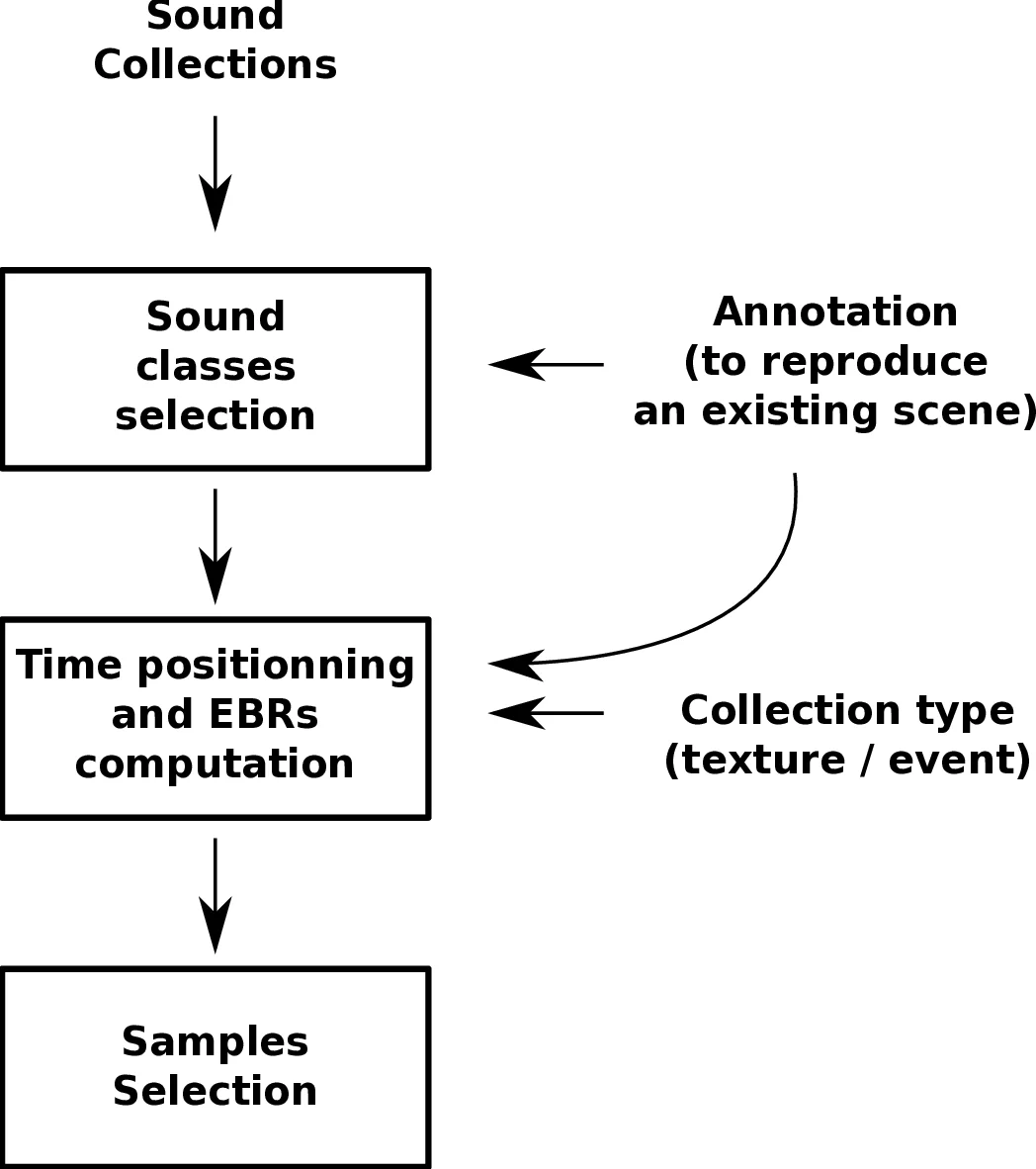
Two fundamental building blocks are defined: event collections and texture collections. Event collections consist of clearly identifiable, short‑duration sounds (e.g., car horns, door slams) that can be treated as individual events. Texture collections, by contrast, represent long‑lasting or statistically homogeneous sounds such as rain, traffic hum, or the rhythmic pattern of horse hooves. The authors argue that human auditory perception naturally separates sound sources (streams) and that this separation can be mirrored in the simulation by treating each source as an independent stream drawn from a dedicated collection.
Labeling of collections follows a “source‑action” paradigm, inspired by cognitive studies on sound categorization. By pairing a source (e.g., “car”) with an action (e.g., “passing”), the intra‑class variability is reduced, making the training data more consistent with the intended semantic meaning. This taxonomy also aligns with hierarchical categorization levels (superordinate, basic, subordinate) identified in the literature, thereby providing a principled way to control the granularity of the simulated data.
The simulation pipeline proceeds in three stages. First, a set of sound collections is curated from publicly available recordings. Second, for each collection, the temporal parameters—onset times, durations, and amplitudes—are sampled from statistical models (Poisson processes for event occurrence, Gaussian distributions for amplitude, etc.). Third, the sampled audio snippets are placed on a timeline and mixed to produce a final acoustic scene. Crucially, the framework exposes high‑level morphological parameters such as background noise level, event density, number of concurrent sources, and inter‑event intervals, allowing researchers to systematically vary listening conditions.
To validate the framework, the authors applied it to the IEEE DCASE Challenge (years 2013 and 2016), evaluating more than ten state‑of‑the‑art event detection systems submitted by different research teams. Both simulated scenes and the original recorded test sets were used for cross‑validation. Performance was measured using precision, recall, and F‑score. The experiments revealed several key findings:
- Background Noise Robustness – As the signal‑to‑noise ratio of the texture background decreased, most systems suffered a steep drop in F‑score, indicating limited ability to separate events from a dense acoustic texture.
- Event Density Effects – Higher event densities led to increased temporal overlap, which in turn raised false‑positive rates. Systems that relied heavily on frame‑wise classification were particularly vulnerable.
- Texture vs. Pure Event Backgrounds – When the background was a texture collection (e.g., rain) rather than a set of isolated events, performance differences among systems widened, highlighting the importance of modeling holistic acoustic statistics in detection algorithms.
The paper’s contributions can be summarized as follows: (i) a flexible, parameter‑driven simulation framework that makes the morphological aspects of acoustic scenes explicit and controllable; (ii) a perceptually motivated methodology for constructing sound collections that reduces labeling ambiguity and aligns with human categorization processes; (iii) a comprehensive empirical analysis of how morphological factors impact the robustness of contemporary event detection algorithms, offering concrete guidance for future algorithmic improvements.
The authors acknowledge limitations: simulated scenes, while controllable, cannot fully replicate the acoustic intricacies of real‑world recordings; the construction of sound collections still involves subjective labeling decisions; and the current model does not incorporate spatial cues or binaural rendering, which are relevant for many applications. Future work is suggested to integrate more sophisticated physical acoustic modeling, automate collection labeling using machine‑learning‑based taxonomy induction, and combine the simulation framework with human listening experiments to further validate perceptual realism.
Comments & Academic Discussion
Loading comments...
Leave a Comment