maxDNN: An Efficient Convolution Kernel for Deep Learning with Maxwell GPUs
This paper describes maxDNN, a computationally efficient convolution kernel for deep learning with the NVIDIA Maxwell GPU. maxDNN reaches 96.3% computational efficiency on typical deep learning network architectures. The design combines ideas from cuda-convnet2 with the Maxas SGEMM assembly code. We only address forward propagation (FPROP) operation of the network, but we believe that the same techniques used here will be effective for backward propagation (BPROP) as well.
💡 Research Summary
The paper introduces maxDNN, a high‑performance convolution kernel specifically engineered for NVIDIA’s Maxwell‑based GPUs. By merging the memory‑layout strategy of cuda‑convnet2 with the assembly‑level optimizations found in the Maxas SGEMM64 implementation, the authors achieve forward‑propagation (FPROP) computational efficiencies that approach the theoretical peak of the hardware, reporting an average of 96.3 % efficiency across a range of realistic deep‑learning network layers.
The authors begin by outlining the limitations of existing GPU‑based deep‑learning libraries such as cuDNN and cuda‑convnet2. While these libraries provide functional correctness and broad applicability, their reported efficiencies often fall below 80 % because they conflate algorithmic complexity, memory‑access overhead, and raw compute throughput. The paper argues that the bottleneck is not the hardware—Maxwell GPUs can sustain near‑peak throughput, as demonstrated by the 96 % efficient SGEMM kernel in the Maxas project—but rather the lack of low‑level control in the standard CUDA toolkit.
To address this, maxDNN adopts the channel‑first data layout used by cuda‑convnet2, which transforms a minibatch of N_b multi‑channel feature maps and a bank of N_o filters into two matrices: an input matrix of size N_b × (S_k² N_c) and a filter matrix of size (S_k² N_c) × N_o. The convolution then reduces to a matrix‑multiply operation. The key contribution is the re‑implementation of this matrix multiply in hand‑written Maxwell assembly, based on the Maxas SGEMM64 kernel. Several sophisticated techniques are employed:
- 128‑bit texture loads replace many scalar loads, reducing global‑memory traffic and eliminating a large portion of address arithmetic.
- Double‑buffering of global and shared memory loads hides latency completely, allowing the arithmetic pipeline to stay fully occupied.
- Pre‑computation of pixel‑channel offsets into constant memory eliminates the three‑level nested loops (channels, rows, columns) that would otherwise dominate the inner loop; the inner loop now consists of a single iteration over pre‑computed offsets.
- Zero‑padding of the input map simplifies boundary handling and enables the kernel to treat all accesses as regular loads.
These optimizations raise the proportion of floating‑point instructions in the inner loop to 98.3 % and result in an overall computational efficiency of 96.3 % for the kernel. The authors also discuss the measurement methodology. They define computational efficiency (C_E) as the ratio of executed floating‑point instructions to the product of 128 (the number of FLOPs per fused‑multiply‑add) and the number of processor clock cycles. To avoid inflating efficiency by counting “extra” instructions (e.g., padding, fixed overhead), they adjust C_E by the theoretical FLOP count of direct convolution, yielding a more faithful metric.
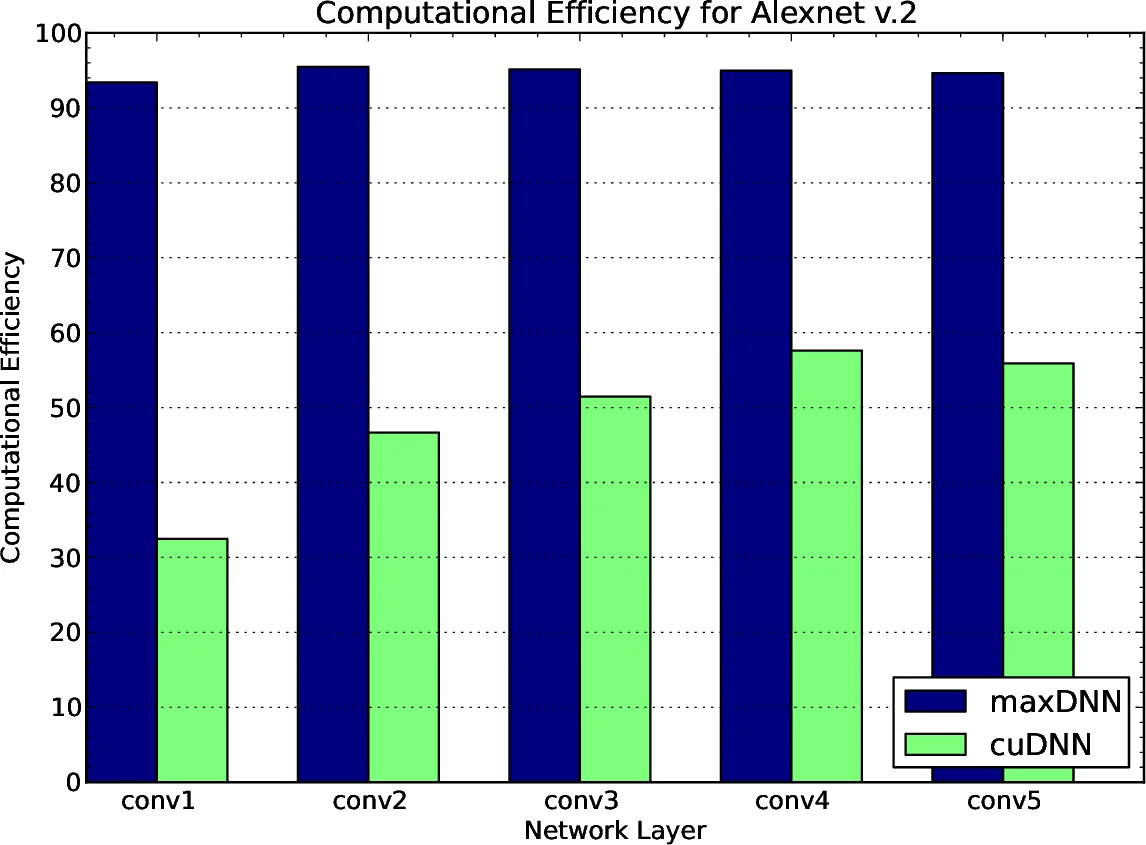
Experimental evaluation is performed on a GTX 980 (GM204) GPU. Two well‑known image‑classification networks—AlexNet‑v2 and OverFeat—are used as benchmarks, with a minibatch size of 128. The results, summarized in Table 1 of the paper, show that maxDNN consistently outperforms cuDNN v2 RC1 across all layers. For AlexNet‑v2, maxDNN’s efficiency ranges from 93.4 % to 95.5 %, whereas cuDNN varies dramatically between 32.5 % and 57.6 %. OverFeat exhibits a similar pattern: maxDNN reaches 96.3 % on the deepest layers, dropping to 70.3 % only on the first layer where the number of filters (96) is not a multiple of the 64‑by‑64 block size used by the kernel. The authors attribute this drop to increased integer‑instruction overhead for indexing and suggest that alternative block sizes (e.g., 64 × 32) could mitigate the issue.
The paper concludes that high‑efficiency convolution on Maxwell GPUs is achievable when developers have fine‑grained control over instruction scheduling, register allocation, and memory‑access patterns. By demonstrating that a convolution kernel can match the efficiency of the best SGEMM implementations, the authors provide a “proof‑of‑concept” that challenges the prevailing belief that high‑level libraries must sacrifice performance for flexibility. They also note that the same assembly‑level techniques should be applicable to backward‑propagation (BPROP), opening the door for a fully optimized training pipeline. Future work includes extending the approach to other GPU architectures (e.g., Volta, Ampere), automating block‑size selection for arbitrary minibatch sizes, and integrating the kernel into higher‑level deep‑learning frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment