Understanding Kernel Ridge Regression: Common behaviors from simple functions to density functionals
Accurate approximations to density functionals have recently been obtained via machine learning (ML). By applying ML to a simple function of one variable without any random sampling, we extract the qualitative dependence of errors on hyperparameters.…
Authors: Kevin Vu, John Snyder, Li Li
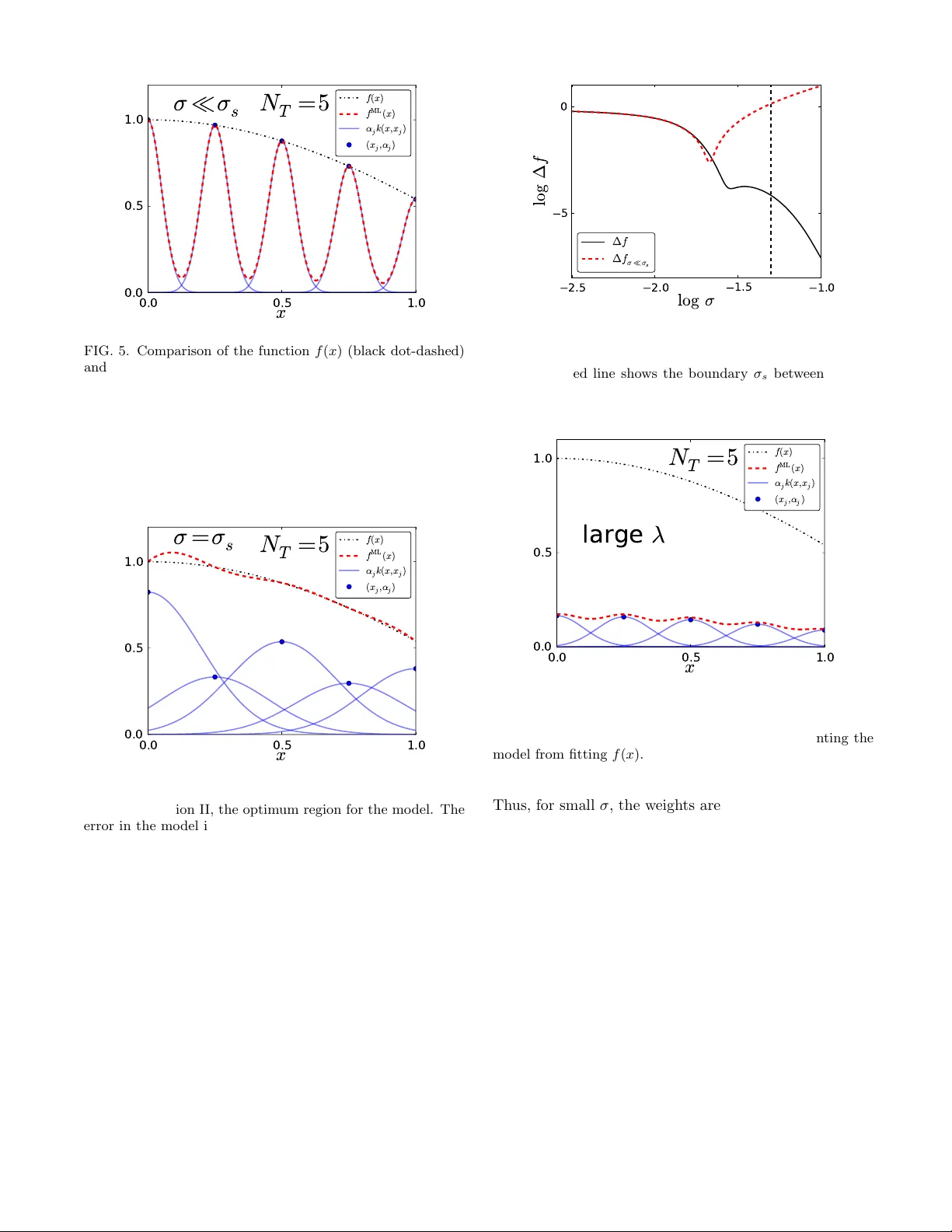
Understanding Kernel Ridge Regression: Common b eha viors from simple functions to densit y functionals Kevin V u , 1 John Sn yder , 2, 3 Li Li , 1 Matthias Rupp , 4 Brandon F. Chen , 5 T arek Khelif , 5 Klaus-Rob ert M¨ uller , 2, 6 and Kieron Burk e 1, 5 1 Dep artment of Physics and Astr onomy, University of California, Irvine, CA 92697 2 Machine L e arning Gr oup, T e chnic al University of Berlin, 10587 Berlin, Germany 3 Max Planck Institute of Micr ostructur e Physics, Weinb er g 2, 06120 Hal le (Saale), Germany 4 Dep artment of Chemistry, University of Basel, Klingelber gstr. 80, 4056 Basel, Switzerland 5 Dep artment of Chemistry, University of California, Irvine, CA 92697 6 Dep artment of Br ain and Co gnitive Engine ering, Kor e a University, Anam-dong, Se ongbuk-gu, Se oul 136-713, Kor e a (Dated: January 29, 2015) Accurate approximations to density functionals hav e recently b een obtained via mac hine learning (ML). By applying ML to a simple function of one v ariable without an y random sampling, w e extract the qualitative dependence of errors on hyperparameters. W e find universal features of the b ehavior in extreme limits, including b oth v ery small and very large length scales, and the noise-free limit. W e show ho w such features arise in ML mo dels of density functionals. I. INTR ODUCTION Mac hine learning (ML) is a p ow erful data-driven metho d for learning patterns in high-dimensional spaces via induction, and has had widespread success in many fields including more recent applications in quantum c hemistry and materials science [ 1 – 9 ]. Here we are in- terested in applications of ML to construction of densit y functionals [ 10 – 14 ], which ha v e fo cused so far on approx- imating the kinetic energy (KE) of non-interacting elec- trons. An accurate, general approximation to this could mak e orbital-free DFT a practical reality . Ho wev er, ML methods hav e been developed within the areas of statistics and computer science, and hav e b een applied to a huge v ariety of data, including neuroscience, image and text processing, and rob otics [ 15 ]. Thus, they are quite general and hav e not b een tailored to account for sp ecific details of the quantum problem. F or example, it w as found that a standard metho d, k ernel ridge regres- sion, could yield excellen t results for the KE functional, while never yielding accurate functional deriv atives. The dev elopment of methods for b ypassing this difficulty has b een important for ML in general [ 13 ]. ML pro vides a whole suite of tools for analyzing data, fitting highly non-linear functions, and dimensionalit y re- duction [ 16 ]. More imp ortan tly in this context, ML pro- vides a completely different wa y of thinking ab out elec- tronic structure. The traditional ab-initio approach [ 17 ] to electronic structure inv olv es deriving carefully con- structed approximations to solving the Schr¨ odinger equa- tion, based on physical intuition, exact conditions and asymptotic behaviors [ 18 ]. On the other hand, ML learns b y example. Giv en a set of training data, ML algorithms learn via induction to predict new data. ML pro vides limited interpolation ov er a sp ecific class of systems for whic h training data is av ailable. A system of N interacting electrons with some exter- nal p oten tial is c haracterized by a 3 N co ordinate wa ve- function, which b ecomes computationally demanding for large N . In the mid 1960’s, Hohenberg and Kohn prov ed a one-to-one correspondence b etw een the external poten- tial of a quantum system and its one-electron ground- state density [ 19 ], showing that all prop erties are func- tionals of the ground-state densit y alone, which can in principle b e found from a single Euler equation for the densit y . Although these fundamental theorems of DFT pro ved the existence of a universal functional, essentially all mo dern calculations use the KS scheme [ 20 ], which is muc h more accurate, b ecause the non-interacting KE is found exactly by using an orbital-scheme [ 21 ]. This is far faster than traditional approaches for large N , but remains a b ottleneck. If a sufficiently accurate den- sit y functional for the non-in teracting electrons could b e found, it could increase the size of computationally tractable systems b y orders of magnitude. The Hohenberg-Kohn theorem guaran tees that all prop erties of the system can b e determined from the elec- tronic density alone. The basic tenet of ML is that a pattern must exist in the data in order for learning to b e p ossible. Thus, DFT seems an ideal case to apply ML. ML learns the underlying pattern in solutions to the Schr¨ odinger equation, b ypassing the need to directly solv e it. The HK theorem is a statement concerning the minimal information needed to do this for an arbitrary one-b ody p oten tial. Some of us recently used ML to learn the non- in teracting KE of fermions in a one-dimensional b ox sub ject to smo oth external p oten tials [ 10 ] and of a one-dimensional model of diatomics where we demon- strated the ability of ML to break multiple b onds self- consisten tly via an orbital-free densit y functional theory (DFT) [ 11 ]. Such KE data is effectively noise-fr e e , since it is generated via deterministic reference calculations, b y solving the Sc hr¨ odinger equation or KS equations nu- merically exactly . (The limited precision of the calcu- lation might b e considered “noise,” as different imple- 2 3 0 3 6 l o g σ 4 0 4 l o g ∆ T 40 100 200 400 800 λ = 1 0 − 1 0 FIG. 1. The error of the mo del, ∆T (Hartree), for the KE of particles in a box (Section IV ) as a function of σ , for fixed λ = 10 − 10 . N T v alues for each curv e are given in the legend. men tations might yield answers differing on the order of mac hine precision, but this is negligble.) There is no noise, in the traditional sense, as is typically asso ciated with exp erimental data. Note that what is considered “noise” dep ends on what is considered ground truth, i.e., the data to b e learned. In particular, if a single refer- ence metho d is used, its error with respect to a universal functional is not considered noise for the ML mo del. A p erfect ML mo del should, at b est, precisely repro duce the single-reference calculation. As an example, in Fig. 1 w e plot a measure of the er- ror of ML for the KE of up to 4 noninteracting spinless fermions in a b ox under a p oten tial with 9 parameters (giv en in detail in Ref. [ 10 ]), fitted for different n um- b ers of ev enly spaced training densities as a function of the h yp erparameter σ (called the length scale), for fixed λ (a h yp erparameter called the regularization strength) and sev eral differen t n um b er of training p oin ts N T . The scale is logarithmic [ 22 ], so there are large v ariations in the fitted error. W e will giv e a more in-depth analysis of the mo del p erformance on this data set in a later section after we ha v e formally defined the functions and hyperpa- rameters inv olv ed, but for now it is still useful to observe the qualitative b eha viors that emerge in the figure. Note that the curv es assume roughly the same shap e for eac h N T o ver the range of σ , and that they all p ossess distinct features in differen t regimes of σ . T o b etter understand the behavior with respect to h y- p erparameters seen in Fig 1, we hav e chosen in this pa- p er to apply them to the protot ypical regression problem, that of fitting a simple function of one co ordinate. W e also remov e all sto chastic elemen ts of the pro cedure, b y considering data p oin ts on uniform grids, defining errors in the contin uum limit, etc. This is shown in Fig. 2 , where w e plot a measure of the error of ML for a simple function cos x , fitted in the region b et ween 0 and 1, inclu- siv e, for several N T (represen ted as v alues on a grid) as a function of σ . Note the remark able similarit y b etw een the features and characteristics of the curves of this fig- 2 1 0 1 2 l o g σ 10 5 0 l o g ∆ f λ = 1 0 − 6 5 9 17 33 FIG. 2. Dependence of the mo del error (as a function of σ ) when fitting cos x b et ween 0 and 1 (Section I I I ) for v arious N T (sho wn in the legend) for λ = 10 − 6 . ure and those of Fig. 1 (lik e Fig. 1 before it, we will giv e a more in-depth analysis of Fig. 2 later). W e explore the b eha vior of the fitting error as a function of the num ber of training parameters and the hyperparameters that are used in k ernel ridge regression with Gaussian kernel. W e find the landscap e to b e surprisingly rich, and we also find elegant simplicities in v arious limiting cases. After this, w e will b e able to characterize the b eha vior of ML for systems lik e the one shown in Fig. 1 . Lo oking at Fig. 2 , we see that the b est results (low- est error) are alwa ys obtained from the middle of the curv es, which can b ecome quite flat with enough training data. Th us, any metho d for determining hyperparame- ters should usually yield a length scale somewhere in this v alley . F or very small length scales, all curves con verge to the same p o or result, regardless of the num ber of train- ing p oints. On the other hand, notice also the plateau structure that dev elops for v ery large length scales, again with all curves conv erging to a certain limit. W e sho w for whic h ranges of hyperparameters these plateaus emerge and ho w they can b e estimated. W e also study and ex- plain many of the features of these curves. T o show the v alue of this study , w e then apply the same reasoning to the problem that was tackled in Ref. [ 10 , 12 ], which we sho wcased in Fig. 1 . F rom the machine learning p erspec- tiv e our study may app ear unusual as it considers prop er- ties in data and problems that are uncommon. Namely there are only a few noise free data p oints and all are lo w dimensional. Nev ertheless, from the physics p oint of view the toy data considered reflects very well the essen- tial prop erties of a highly relev ant problem in quantum ph ysics: the mac hine learning of DFT. 3 I I. BA CK GROUND In this work, we will first use ML to fit a very simple function of one v ariable, f ( x ) = cos x, (1) on the in terv al x ∈ [0 , 1]. W e will fo cus on exploring the prop erties of ML for this simple function b efore pro ceed- ing to our DFT cases. W e choose a set of x -v alues and corresp onding f ( x ) v alues as the “training data” for ML to learn from. In ML, the x -v alues { x j } for j = 1 , . . . , N T are known as fe atur es , and corresponding f -v alues, { f j } , are kno wn as lab els . Here N T is the n umber of training samples. Usually , ML is applied with considerable ran- dom elemen ts, suc h as in the c hoice of data p oints and se- lection of test data. In our case, we c hoose evenly spaced training p oin ts on the interv al [0 , 1]: x j = ( j − 1) / ( N T − 1) for j = 1 , . . . , N T . Using this dataset, we apply kernel ridge regression (KRR), whic h is a non-linear form of regression with reg- ularization to prev ent ov erfitting [ 16 ], to fit f ( x ). The general form of KRR is f ML ( x ) = N T X j =1 α j k ( x, x j ) , (2) where α j are the weights , k is the kernel (whic h is a measure of similarity b et ween features), and the hyper- parameter λ controls the strength of the regularization and is linked to the noise level of the learning problem. W e use the Gaussian kernel k ( x, x 0 ) = exp − ( x − x 0 ) 2 / 2 σ 2 , (3) a standard choice in ML that works well for a v ariet y of problems. The hyperparameter σ is the length scale of the Gaussian, which controls the degree of correlation b et w een training points. The w eights α j are obtained through the minimization of the cost function C ( α ) = N T X j =1 f ML ( x j ) − f j 2 + λ α T K α , (4) where α = ( α 1 , . . . , α N T ) T . (5) The exact solution is given by α = ( K + λ I ) − 1 f , (6) where I is the N T × N T iden tity matrix, K is the k er- nel matrix with elements K ij = k ( x i , x j ), and f = ( f 1 , . . . , f N T ) T . The tw o parameters λ and σ not determined by Eq. ( 6 ) are called h yp erparameters and m ust b e determined from the data (see section I I I C ). σ can b e viewed as the c har- acteristic length scale of the problem b eing learned (the scale on which changes of f tak e place), as discernible from the data (and th us dep enden t on, e.g., the n um b er of training sam ples). λ controls the leewa y the model has to fit the training p oin ts. F or small λ , the mo del has to fit the training points exactly , whereas for larger λ some deviation is allow ed. Larger v alues of λ therefore cause the mo del to b e smo other and v ary less, i.e., less prone to ov erfitting. This can b e directly seen in Gaussian pro- cess regression [ 23 ], a related Bay esian ML mo del with predictions identical to those of KRR. There, λ formally is the v ariance of the assumed additive Gaussian noise in v alues of f . KRR is a metho d of in terp olation. Here, w e are mainly concerned with the error of the mac hine learning appro x- imation (MLA) to f ( x ) in the interp olation r e gion , whic h in this case is the interv al x ∈ [0 , 1]. As a measure of this error, w e define ∆f = Z 1 0 dx ( f ( x ) − f ML ( x )) 2 . (7) In the case of the Gaussian k ernel, we can expand this and deriv e the integrals that app ear analytically . T o sim- plify the analytical pro cess, w e define ∆f 0 = Z 1 0 dx f 2 ( x ) , (8) as the benchmark error when f ML ( x ) ≡ 0. F or the cosine function in Eq. ( 1 ), ∆f 0 = Z 1 0 dx cos 2 ( x ) = 1 2 + sin(2) 4 ≈ 0 . 7273 . (9) Our goal is to c haracterize the dependence of the p er- formance of the model on the size of the training data set ( N T ) and the hyperparameters of the mo del ( σ, λ ). F or this simple mo del, w e discuss different regions of qual- itativ e behavior and deriv e the dependence of ∆f for v arious limiting v alues of these hyperparameters; we do all of this in the next few sections. In Section IV , we discuss ho w these results can b e qualitatively generalized for the problem of using ML to learn the KE functional for non-in teracting fermions in the b o x for a limited class of potentials. I II. ANAL YSIS W e b egin by analyzing the structure of ∆f as a func- tion of σ for fixed λ and N T . Fig. 2 sho ws ∆f as a function of σ for v arious N T while fixing λ = 10 − 6 . The curv es hav e roughly the same “v alley” shap e for all N T . The b ottom of the v alley is an order of magnitude deep er than the walls and may ha ve m ultiple lo cal min- ima. These v alleys are nearly identical in shap e for suf- ficien tly large N T , which indicates that this particular 4 1 10 -4 10 -8 10 -12 FIG. 3. Dependence of the mo del error (as a function of σ ) for v arious λ with N T = 33. The lab els give the v alue of λ for each curv e. feature arises in a systematic manner as N T increases. Moreo ver, this central v alley op ens up to the left (i.e., smaller σ ) as N T increases— as the training samples b e- come more densely pack ed, narro wer Gaussians are b et- ter able to interpolate the function smo othly . Th us, with more training samples, a wider range of σ v alues will yield an accurate mo del. In addition, a “cusp” will b egin to app ear in the region to the left of the v alley , and its general shap e remains the same for increasing N T . This is another recurring feature that app ears to dev elop systematically like the v alley . F or a fixed N T , and starting from the far left, the ∆f curv e b egins to decrease monotonically to the right, i.e., as σ increases. The cusps mark the first break in this mono- tonic behavior, as ∆f increases briefly after reac hing this lo cal minimum b efore resuming its monotonic decrease for increasing σ (until this monotonicity is interrupted again in the v alley region). The cusps shift to the left as N T increases, following the trend of the v alleys. This indicates that they are a fundamen tal feature of the ∆f curv es and that their app earances coincide with a par- ticular b ehavior of the mo del as it approaches certain σ v alues. Note that ∆f decreases nearly monotonically as N T increases for all σ . This is as exp ected, since each additional training sample adds another weigh ted Gaus- sian, whic h should impro v e the fit. Fig. 3 again shows ∆f as a function of σ , but for v ari- ous λ with N T fixed at 33. As λ decreases, ∆f again de- creases nearly monotonically and the central region op ens up to the right (i.e., larger σ ). Note that the curves for each λ coincide up to a certain σ b efore they split off from the rest, with the low er λ -v alued curves break- ing off further along to the right than those with larger λ . This shows a w ell-known phenomenon, namely that regularization strength λ and kernel length scale σ b oth giv e rise to regularization and smo othing [ 24 ]. Addition- ally , we observe the emergence of “plateau”-like struc- tures on the right. These will b e explored in detail in Section II I A 2 . 2 0 2 l o g σ 10 5 0 l o g ∆ f I I I I I I FIG. 4. Mo del error ∆f as a function of σ for N T = 20 and λ = 10 − 6 . W e divide the range of σ into three qualitativ ely distinct regions I, I I and I I I. The b oundaries b etw een the regions are given by the v ertical dashed lines. A. Regions of qualitativ e b ehavior In Fig. 4 , we plot ∆f as a function of σ for fixed λ and N T . The three regions lab eled I, I I, and I II denote areas of distinct qualitativ e b ehavior. They are delin- eated by t w o arbitrary b oundaries we denote b y σ s ( s for small, b et ween I and I I) and σ l ( l for large, b etw een I I and I I I). In region I, ∆f decreases significantly as σ in- creases. The region ends when there is significant ov erlap b et w een neigh b oring Gaussians (i.e., when k ( x j , x j +1 ) is no longer small). Region I I is a “v alley” where the global minim um for ∆f resides. Region I I I b egins where the v alley ends and is p opulated by “plateaus” that corre- sp ond to f ML ( x ) assuming a p olynomial form (see Sec- tion I I I A 2 ). In the following sections, we examine each region separately . In particular, w e are interested in the asymptotic b eha vior of ∆f with resp ect to N T , σ and λ . 1. L ength scale to o smal l The ML mo del for f ( x ), giv en in Eq. ( 2 ), is a sum of weigh ted Gaussians centered at the training p oin ts, where the weigh ts α j are chosen to b est repro duce the unkno wn f ( x ). Fig. 5 sho ws what happens when the width of the Gaussian kernel is to o small—the mo del is incapable of learning f ( x ). W e call this the “comb” re- gion, as the shape of f ML ( x ) arising from the narrow Gaussians resembles a comb. In order for f ML ( x ) to ac- curately fit f ( x ), the weigh ted Gaussians m ust ha v e sig- nifican t ov erlap. This b egins when σ is on the order of the distance b et ween adjacent training p oints. A corre- sp onding general heuristic is to use a multiple (e.g., four times) of the me dian ne ar est neighb or distanc e ov er the training set [ 11 ]. F or equally spaced training data in one dimension, this is ∆x ≈ 1 / N T , so w e define σ s = 1 / N T (10) 5 0.0 0.5 1.0 x 0.0 0.5 1.0 f ( x ) f M L ( x ) α j k ( x , x j ) ( x j , α j ) σ ¿ σ s N T = 5 FIG. 5. Comparison of the function f ( x ) (blac k dot-dashed) and the ML mo del f ML ( x ) (red dashed), for N T = 5, σ = 0 . 05 σ s ( σ s = 0 . 2), and λ = 10 − 6 . When summed, the w eighted Gaussians, α j k ( x, x j ) (blue solid), giv e f ML ( x ). The blue dots show the lo cation of the training p oin ts and the v alue of the corresponding weigh ts. In this case, the mo del is in the “comb” region, when σ σ s . The width of the Gaus- sians is muc h smaller than the distance ∆x b etw een adjacen t training p oints, and so the model cannot repro duce the exact function. 0.0 0.5 1.0 x 0.0 0.5 1.0 f ( x ) f M L ( x ) α j k ( x , x j ) ( x j , α j ) σ = σ s N T = 5 FIG. 6. Same as Fig. 5 , but for σ = σ s = 0 . 2. Here, the mo del is in region II, the optim um region for the mo del. The error in the mo del is very small for all x in the in terp olation region. The width of the Gaussians is comparable to the size of the interpolation region, and the weigh ts are large. to be the b oundary betw een regions I and I I. In Fig. 6 , as the ov erlap betw een neighboring Gaussians b ecomes sig- nifican t the model is able to reproduce the mo del well but still with significan t error. Note that the common heuris- tics of choosing the length scale in radial basis function net works [ 25 ] are very muc h in line with this finding. In the comb region, ∆f decreases as σ increases in a c har- acteristic wa y as the Gaussians b egin to fill up the space b et w een the training p oints. F or λ → 0, the w eights are appro ximately given as the v alues of the function at the corresp onding training p oints: α j ≈ f j , σ σ s . (11) 2.5 2.0 1.5 1.0 l o g σ 5 0 l o g ∆ f ∆ f ∆ f σ ¿ σ s FIG. 7. Same as Fig. 4 , but comparing ∆f against our expan- sion of ∆f for σ σ s (blue dashed), given in Eq. ( A1 ). The v ertical dashed line shows the b oundary σ s b et w een regions I and I I. The expansion breaks down b efore w e reach σ s , as the approximation that α j ≈ f ( x j ) is no longer v alid. 0.0 0.5 1.0 x 0.0 0.5 1.0 f ( x ) f M L ( x ) α j k ( x , x j ) ( x j , α j ) l a r g e λ N T = 5 FIG. 8. Same as Fig. 5 , but for σ = 0 . 1, and λ = 5. In this case, known as o ver-regularization, λ is too large, forcing the magnitude of the weigh ts α j to b e small and prev enting the mo del from fitting f ( x ). Th us, for small σ , the w eigh ts are indep enden t of σ . Let ∆f σ σ s b e the error of the mo del when α j = f ( x j ). This approximation, shown in Fig. 7 , captures the initial decrease of ∆f as σ increases, but breaks down b efore w e reach σ s . The qualitativ e nature of this decay is in- dep enden t of the t yp e of function f ( x ), but its lo cation and scale will dep end on the specifics. As σ → 0 (for fixed λ and N T ), f ML ( x ) b ecomes the sum of infinitesimally narrow Gaussians. Thus, in this limit, the error in the mo del becomes lim σ → 0 ∆f = ∆f 0 . (12) Note that this limit is indep enden t of λ and N T . Fig. 8 shows what happ ens when the regularization b ecomes to o strong. (Although shown for σ in region I, the qualitativ e b eha vior is the same for any σ .) The regularization term in Eq. ( 4 ) forces the magnitude of the weigh ts to b e small, preven ting f ML ( x ) from fitting 6 f ( x ). As λ → ∞ , the w eights are driv en to zero, and so w e obtain the same limit as in Eq. ( 12 ): lim λ →∞ ∆f = ∆f 0 . (13) 2. L ength scale to o lar ge W e define the b oundary σ l b et w een regions I I and I I I as the last local minimum of ∆f (with resp ect to σ ). Th us, in region I I I (see Figs. 2 and 3 ) ∆f is monotoni- cally increasing. As σ b ecomes large, the k ernel functions b ecome wide and flat ov er the interpolation region, and in the limit σ → ∞ , f ML ( x ) is appro ximately a constan t o ver x ∈ [0 , 1]. F or small λ , the optimal constant will b e the a v erage v alue ov er the training data lim σ, 1 /λ →∞ ˆ f ( x ) = 1 N T N T X j =1 f ( x j ) . (14) Note that the order of limits is imp ortant here: first σ → ∞ , then λ → 0. If the order is reversed, f ML ( x ) b ecomes the b est p olynomial fit of order N T . W e will show this explicitly for N T = 2. F or smaller σ in region I I I, as λ decreases, the emergence of “plateau”-like structures can b e seen (see Fig. 3 ). As will b e shown, these flat areas corresp ond to the mo del b eha ving as p olynomial fits of different orders. These can b e derived by taking the limits σ → ∞ and λ → 0 while maintaining σ in a certain proportion to λ . a. N T = 2 : In this case, the ML function is f ML ( x ) = α 1 e − x 2 / 2 σ 2 + α 2 e − ( x − 1) 2 / 2 σ 2 , (15) and the w eigh ts are determined by solving α 1 α 2 = 1 + λ e − 1 / 2 σ 2 e − 1 / 2 σ 2 1 + λ − 1 f 1 f 2 , (16) where f j = f ( x j ). The solution is α 1 = ( f 1 (1 + λ ) − e − 1 / 2 σ 2 f 2 ) /D , (17) α 2 = ( f 2 (1 + λ ) − e − 1 / 2 σ 2 f 1 ) /D , (18) where D = det( K + λI ) = 1 + 2 λ + λ 2 − e − 1 / 2 σ 2 . First, w e expand in p o w ers of σ as σ → ∞ , keeping up to first order in 1 / 2 σ 2 : α 1 ≈ (( f 1 − f 2 ) + f 1 λ + f 2 / 2 σ 2 ) /D , (19) α 2 ≈ (( f 2 − f 1 ) + f 2 λ + f 1 / 2 σ 2 ) /D , (20) where D ≈ 2 λ + λ 2 + 1 / 2 σ 2 . (21) Finally f ML ( x ) ≈ ¯ α + ( α 2 (2 x − 1) − ¯ αx 2 ) / 2 σ 2 , (22) where ¯ α = α 1 + α 2 . Next, we take λ → 0. In this limit D v anishes and the w eights div erge. The relative rate at which the limits are taken will affect the asymptotic b eha vior of the weigh ts. The form of D suggests we take β = 1 2 λσ 2 , (23) where β is a constan t. T aking σ → ∞ , we obtain a linear form: f ML β ( x ) = β f 1 + f + β ( f 2 − f 1 ) x β + 1 , (24) where f = 1 2 ( f 1 + f 2 ). The parameter β smo othly con- nects the constan t and linear plateaus. When β → 0, we reco ver the constant form f ML ( x ) = f ; when β → ∞ , w e reco ver the linear form f ML ( x ) = f 1 + x ( f 2 − f 1 ). W e can determine the shape of the transition b etw een plateaus by substituting Eq. ( 24 ) for f ML ( x ) into Eq. ( 7 ) for ∆f . F or simplicity’s sake, we first define h ij = Z 1 0 dx x i f j ( x ) , (25) since expressions of this form will show up in subsequent deriv ations in this w ork. Finally , w e obtain ∆f β = − 2( f + f 1 β ) h 01 1 + β + 2 β ( f 1 − f 2 ) h 11 1 + β + (3 + 6 β + 4 β 2 ) f 2 − f 1 f 2 β 2 3(1 + β 2 ) + h 02 . (26) In Fig. 9 , we compare our numerical ∆f with the ex- pansion Eq. ( 26 ) showing the transition b etw een the lin- ear and constant plateaus. In the case of N T = 2, only these t w o plateaus exist. In general, there will b e at most N T plateaus, each corresp onding to successiv ely higher order polynomial fits. How ev er, not all of these plateaus will necessarily emerge for a given N T ; as w e will show, the plateaus only b ecome apparent when λ is sufficien tly small, i.e., when the asymptotic b ehavior is reached, and when σ and λ are prop ortional in a certain w ay similar to ho w w e defined β . This analysis reveals the origin of the plateaus. In the series expansion for σ → ∞ , λ → 0, cer- tain terms corresp onding to p olynomial forms b ecomes dominan t when σ and λ remain proportional. b. N T = 3 : W e pro ceed in the same manner for N T = 3, using β and substituting into the analytical form of f ML ( x ) for this case to obtain an expression for ∆f β (sho wn in the app endix). This expression is plotted in Fig. 10 . T o deriv e the limiting v alue of ∆f at each plateau for large N T and small λ , we minimize the cost function Eq. ( 4 ) (whic h is equiv alen t to Eq. ( 7 ) in this limit), assuming an n -th order p olynomial form for f ML ( x ). W e define c n as the limiting v alue of ∆f for the n -th order plateau: c n = lim σ ∝ λ − 1 / 2 ,N T →∞ = min ω i Z 1 0 dx ( f ( x ) − n X i =0 ω i x i ) 2 . (27) 7 2 0 2 4 l o g σ 4 3 2 1 0 l o g ∆ f N T = 2 , λ = 1 0 − 6 ∆ f ∆ f β FIG. 9. Comparing the numerical ∆f (black solid), for N T = 2 and λ = 10 − 6 , with our asymptotic form ∆f β (red dashed) giv en by Eq. ( 26 ). The asymptotic form accurately reco vers the b ehavior of ∆f in the plateau regions, but fails for small σ as exp ected. 2 0 2 4 l o g σ 8 6 4 2 0 l o g ∆ f N T = 3 , λ = 1 0 − 6 ∆ f ∆ f β FIG. 10. Comparing the n umerical ∆f (blac k solid), for N T = 3 and λ = 10 − 6 , with our asymptotic form ∆f β (red dashed). The asymptotic form accurately recov ers the behavior of ∆f in the plateau regions, but fails for small σ as exp ected. F or the constant plateau, f ML ( x ) assumes the constant form a ; to minimize Eq. ( 7 ) with respect to a , w e solv e d da Z 1 0 dx ( f ( x ) − a ) 2 = 0 (28) for a , obtaining a = Z 1 0 dx f ( x ) , (29) so that f ML ( x ) = h 01 . (30) Th us, w e obtain c 0 = − h 2 01 + h 02 . (31) F or our case with f ( x ) = cos( x ), c 0 = 0 . 0193. F or the linear plateau, f ML ( x ) assumes the linear form ax + b ; minimizing Eq. ( 7 ) with resp ect to a and b , we find that f ML ( x ) = (12 h 11 − 6 h 01 ) x + 4 h 01 − 6 h 11 , (32) yielding, via Eq. ( 27 ), c 1 = h 02 − 4 h 2 01 − 3 h 01 h 11 + 3 h 2 11 . (33) F or our case with f ( x ) = cos( x ), c 1 = 1 × 10 − 3 . The same procedure yields c 2 = 2 . 25 × 10 − 6 . Next, w e define = 1 2 λ 1 / 2 σ 2 (34) as another parameter to relate σ and λ . W e c hoose to de- fine this using the same motiv ation as for β , i.e., we exam- ined our analytical expression for f ML ( x ) and pic ked this parameter to substitute in order for σ and λ to remain prop ortional in a sp ecific wa y as they approach certain limits and to see what v alues ∆f takes for these limits (in particular, w e are interested to see if we can obtain all 3 plateaus for N T = 3). In doing this, we obtain an expansion analogous to that of Eq. ( 26 ) (shown as ∆f in the appendix). W e plot this expression in Fig. 11 , alongside our numer- ical ∆f and the plateau limits, for N T = 3 and v arying λ . Note that the curves of the expansions are con tingen t on the v alue of λ ; w e do not retrieve all 3 plateaus for all of the expansions. Only the expansion curves corre- sp onding to the smallest λ (10 − 10 , the blue curv e) and second smallest λ (10 − 6 , the yello w curve) sho w broad, definitiv e ranges of σ where they take the v alue of each of the 3 plateaus (for the dashed blue curve, this is ev- iden t for c 1 and c 2 ; the curv e approaches c 0 for larger σ ranges not shown in the figure), suggesting a sp ecific prop ortion b et ween σ and λ is needed for this to o ccur. F or the solid numerical curv es, only the blue curve mani- fests all 3 plateaus (lik e its expansion curve counterpart, it approac hes c 0 for larger σ ranges not sho wn); the other t wo do not obtain all 3 plateaus, regardless of the range of σ (the solid red curve do es not ev en go do wn as far as c 2 ). Ho w ev er, there app ears to b e a singularity for eac h of the expansion curv es (the sharp spikes for the dashed curv es) at certain v alues of σ ( ) dep ending on λ . This singularit y emerges b ecause our substitution of leads to an expression with in the denominator of our ∆f ana- lytical form, which naturally has a singularity for certain v alues of dep ending on λ . F ollo wing the precedent set for N T = 2 and N T = 3, w e can pro ceed in the same w ay for larger N T and p erform the same analysis, where w e exp ect to find higher order plateaus and the same b eha vior for limiting v alues of the parameters, including sp ecific plateau v alues for ∆f when σ and λ are v aried with resp ect to each other in certain wa ys analogous to that of the previous cases. W e w ould like to remark that 8 2 0 2 4 l o g σ 6 4 2 0 l o g ∆ f c 0 c 1 c 2 N T = 3 1 0 − 2 1 0 − 6 1 0 − 1 0 FIG. 11. The dep endence of the mo del error on σ , for N T = 3 and v arying λ . The solid curves are numerical; the dashed curv es are expansions derived by using our expression for in Eq. ( 34 ) and substituting into f ML ( x ) in Eq. ( 7 ). The legend giv es the colors (for b oth the dashed and solid curves) corresp onding to each λ . 15 10 5 0 5 l o g λ 20 10 0 l o g ∆ f ( ˜ σ ) 3 5 9 17 33 65 ∆ f ( ˜ σ ) ∝ λ FIG. 12. The dep endence of ∆f ( ˜ σ ) on λ for v arious N T . Here, ˜ σ minimizes ∆f for fixed N T and λ . N T v alues for eac h curv e are giv en in the legend. The dashed line shows a linear prop ortionalit y b et ween ∆f ( ˜ σ ) and λ . plateau-lik e b eha viors are w ell-known in statistical (on- line) learning in neural netw orks [ 26 ]. Ho wev er, those plateaus are distinct from the plateau effects discussed here since they corresp ond to limits in the (online) learn- ing b eha vior due to symmetries [ 27 , 28 ] or singularities [ 29 , 30 ] in the mo del. 3. L ength scale just right In the central region (see Fig. 4 ), ∆f as a function of σ has the shap e of a v alley . The optim um mo del, i.e., the mo del whic h gives the low est error ∆f , is found in this region. F or fixed N T and λ , we define the σ that gives the global minimum of ∆f as ˜ σ . In Fig. 12 , w e plot the b eha vior of ∆f ( ˜ σ ) as a function of λ . Again, w e observe three regions of different qualitativ e b ehavior. F or large 5 9 17 33 FIG. 13. Same as Fig. 2 , except with σ replaced by γ σ , where γ = 10 for the solid curves and γ = 1 for the dashed curves. The lab els give the v alue of N T for each curv e. λ , w e ov er-regularize (as was shown in Fig. 8 ), giving the limiting v alue ∆f 0 in Eq. ( 13 ). F or mo derate λ , we observ e an approximately linear prop ortionalit y b et ween ∆f ( ˜ σ ) and λ : ∆f ( ˜ σ ) ∝ λ. (35) Ho wev er, for small enough λ , there is v anishing regular- ization α NF = lim λ → 0 ( K + λ I ) − 1 f , (36) yielding the noise-fr e e limit of the mo del: f ML NF ( x ) = N T X j =1 α NF j k ( x, x j ) . (37) In this case (for the Gaussian k ernel), this limit exists for all σ . The error of the noise-free mo del is ∆f NF = lim λ → 0 ∆f . (38) B. Dep endence on function scale W e no w introduce the parameter γ into our simple one v ariable function, so that Eq. ( 1 ) b ecomes f ( x ) = cos( γ x ) . (39) F or large v alues of γ , Eq. ( 39 ) b ecomes highly oscilla- tory; we extend our analysis here in order to observe the b eha vior of the mo del in this case. Fig. 13 shows ∆f as a function of γ σ for v arious N T while fixing λ = 10 − 6 and γ =10 (solid lines), γ = 1 (dashed lines). This is the same as that of Fig. 2 , except with the additional γ parameter. This figure demon- strates that the qualitative b ehaviors we observ ed in Fig. 2 persist with the inclusion of the γ parameter, com- plete with the characteristic “v alley” shap e emerging in 9 1 10 -4 10 -8 10 -12 FIG. 14. Same as Fig. 3 , except with σ replaced by γ σ , where γ = 10 for the solid curves and γ = 1 for the dashed curves. The lab els give the v alue of λ for eac h curve. the mo derate σ region for eac h N T . Similarly , we see that ∆f decreases nearly monotonically for increasing N T for all γ σ , while op ening up to the left as the Gaussians are b etter able to in terp olate the function. The cusps, though not as pronounced, are still presen t to the left of the v alleys, and their general shap es remain the same for increasing N T . Fig. 14 shows ∆f as a function of γ σ for v arious λ while fixing N T = 33 and γ =10 (solid lines), γ = 1 (dashed lines). This is the same as Fig. 3 , except with the γ parameter included. Like in Fig. 3 , as λ decreases ∆f decreases nearly monotonically . The same qualita- tiv e features still hold, including the splitting-off of eac h lo wer-v alued λ curv e further along σ . Next, w e lo ok at how the optimal mo del dep ends on N T . In Fig. 15 , we plot ∆f ( ˜ σ ) as a function of N T , for v arious γ . F or small N T , there is little to no im- pro vemen t in the mo del, dep ending on γ . F or large γ , f ML ( x ) is rapidly v arying and the mo del requires more training samples before it can begin to accurately fit the function. At this p oin t, ∆f ( ˜ σ ) decreases as N − c T , where c ≈ 27 is a constant indep enden t of γ . This fast learn- ing rate drops off considerably when ∆f is on the order of λ (i.e., at the limit of machine precision), and ∆f ( ˜ σ ) lev els off (as λ corresp onds to the leew ay the mo del has for fitting training f ( x ) v alues, i.e., to the accuracy with whic h the model can resolve errors during fitting, it can- not improv e the error m uch beyond this v alue). In fact, it is known that the learning rate in the asymptotic limit is 1 / N T for faithful mo dels (i.e., models that capture the structure of the data) and 1 / √ N T for unfaithful mo dels [ 16 , 31 ]. How ev er, b efore the regularization kicks in ∆f is appro ximately the noise-free limit ∆f NF . If the noise- free limit were taken for all N T , it app ears that ∆f ( ˜ σ ) w ould decrease con tin ually at the same learning rate: ∆f NF ∝ N − c T . (40) The learning rate here resem bles the error decay of an in tegration rule, as our simple function is smo oth and 0.5 1.0 1.5 l o g N T 20 15 10 5 0 l o g ∆ f ( ˜ σ ) l i m λ → 0 ∆ f ( ˜ σ ) ∝ N − c T c ≈ 2 7 γ = 1 γ = 5 γ = 1 0 FIG. 15. The dep endence of ∆f ( ˜ σ ) on N T for v arious γ . Here, ˜ σ minimizes ∆f for fixed N T and λ . The solid portion of the line represen ts the limit at λ → 0 (the noise-free curv e), while the dot-dashed contin uation shows the deca y for finite λ ( λ = 10 − 14 is shown here). F or large enough N T and λ → 0, ∆f has the asymptotic form given appro ximately by the linear fit here (dashed line). Note that, although this asymptotic form is indep enden t of γ , for larger γ the asymptotic region is reached at larger N T . can alwa ys b e approximated lo cally by a T aylor series expansion with enough p oints on the in terv al. How ev er, the mo del here uses an expansion of Gaussian functions instead of p olynomials of a particular order, and the error deca ys muc h faster than a standard integration rule such as Simpson’s, which decays as N − 4 T in the asymptotic limit. Additionally , Eq. ( 40 ) is indep endent of γ since, for large enough N T , the functions app ear no more complex lo cally . The larger y-intercepts for the larger γ curv es in Fig. 15 arise due to the larger num b er of p oin ts needed to reach this asymptotic regime, so the errors should b e comparativ ely larger. C. Cross-v alidation In previous works (Ref. [ 10 , 12 ]) applying ML to DFT, the h yp erparameters of the mo del w ere optimized in or- der to find the b est one, i.e., we needed to find the hy- p erparameters suc h that the error for the mo del is min- imal on the en tire test set, which has not b een seen b y the machine in training [ 8 ]. W e did this by using cross-v alidation, a technique whereby we minimize the error of the mo del with resp ect to the hyperparameters on a partitioned subset of the data w e denote as the v alidation set . Only after we hav e chosen the optimal h yp erparameters through cross-v alidation do w e test the accuracy of our mo del by determining the error on the test set. W e fo cus our attention on leav e-one-out cross- v alidation, where the training set is randomly partitioned in to N T bins of size one (each bin consisting of a distinct training sample). A v alidation set is formed by taking the first of these bins, while a training set is formed from the rest. The mo del is trained on the training set, and 10 0.4 0.2 0.0 0.2 0.4 l o g σ 10.0 9.5 9.0 8.5 8.0 7.5 l o g ∆ f λ = 1 0 − 6 N T = 9 , 3 3 FIG. 16. The dep endence of ∆f on σ , for λ = 10 − 6 and N T = 9 (curv e shown in red with dashed lines) and 33 (curv e sho wn in blue with solid lines). The crosses denote ∆f for the optimized σ v alues found from p erforming lea ve-one-out cross-v alidation (some of these are degenerate, so there are less than N T distinct crosses shown), while the dots denote ∆f ( ˜ σ ), the global minimum of ∆f o ver σ (the crosses and dots are matched in color with the curv es for eac h N T ). optimal hyperparameters are determined by minimizing the error on the singleton v alidation set. This procedure is rep eated for each bin, so N T pairs of optimal hyper- parameters are obtained in this manner; w e take as our final optimal hyperparameters the median of each h yp er- parameter on the en tire set of obtained h yperparameters. The generalization error of the mo del with optimal h y- p erparameters will finally b e tested on a test set, whic h is inaccessible to the machine in cross-v alidation. Our previous works [ 10 – 12 ] demonstrated the efficacy of cross-v alidation in pro ducing an optimal mo del. Our aim here is to show how this pro cedure optimizes the mo del for our simple function on ev enly-spaced training samples. W e hav e th us far trained our mo del on evenly spaced points on the in terv al [0 , 1]: x j = ( j − 1) / ( N T − 1) for j = 1 , . . . , N T . W e wan t to compare how the mo del error determined in this wa y compares to the mo del er- rors using leav e-one-out cross-v alidation to obtain opti- mal hyperparameters. In Fig. 16 , we plot the mo del er- ror ov er a range of σ v alues (we fix λ = 10 − 6 and we use N T = 9 and N T = 33; c ompare this with Fig. 2 ). F or each N T , we p erform leav e-one-out cross -v alidation (using our fixed λ so that we obtain optimal σ ), yield- ing N T optimal σ v alues; we plot the mo del errors for eac h of these σ . W e also include the global minimum error ∆f ( ˜ σ ) for each N T to show how they compare to the errors for the optimal σ . Lo oking at Fig. 16 , w e see that the optimal σ v alues all yield errors near ∆f ( ˜ σ ) and within the characteristic “v alley” region, demonstrating that lea ve-one-out cross-v alidation indeed optimizes our mo del. With this close proximit y in error v alues estab- lished, we can thus reasonably estimate the error of the mo del for the optimal σ (for a giv en λ ) by using ˜ σ . IV. APPLICA TION TO DENSITY FUNCTIONALS A canonical quantum system used frequen tly to ex- plore basic quan tum principles and as a pro ving ground for approximate quantum metho ds is the particle in a b o x. In this case, we confine one fermion to a 1d b o x with hard walls at x = 0 , 1, with the addition of the ex- ternal p otential v ( x ) in the interv al x ∈ [0 , 1]. The equa- tion that gov erns the quan tum mec hanics is the familiar one-b ody Schr¨ odinger equation − 1 2 ∂ 2 ∂ x 2 + v ( x ) φ ( x ) = φ ( x ) . (41) A solution of this equation gives the orbitals φ j ( x ) and energies j . F or one fermion, only the low est energy level is o ccupied. The total energy is E = 1 , the p otential energy is V = Z dx n ( x ) v ( x ) (42) (where n ( x ) = | φ ( x ) | 2 is the electron density), and the KE is T = E − V . In the case of one particle, the KE can b e expressed exactly in terms of the electron density , kno wn as the v on W eizs¨ ac ker functional [ 32 ] T W = Z dx n 0 ( x ) 2 8 n ( x ) , (43) where n 0 ( x ) = dn/dx . Our goal here in this section is not to demonstrate the efficacy of ML approximations for the KE in DFT (which is the sub ject of other works [ 10 , 11 ]), but rather to study the prop erties of the ML appro ximations with respect to those applications. W e c ho ose a simple p oten tial inside the box, v ( x ) = − D sin 2 π x, (44) to mo del a well of depth D , which has also b een used in the study of semiclassical metho ds [ 33 ]. T o generate reference data for ML to learn from, we solv e Eq. ( 41 ) n umerically by discretizing space onto a uniform grid, x j = ( j − 1) / ( N G − 1), for j = 1 , . . . , N G , where N G is the num b er of grid points. Numerov’s metho d is used to solv e for the lo west energy orbital and its corresp onding eigen v alue. W e compute T and n ( x ), which is represented b y its v alues on the grid. F or a desired n umber of training samples N T , we v ary D uniformly ov er the range [0 , 100], inclusiv e, generating N T pairs of electron densities and exact KEs. Additionally , a test set with 500 pairs of electron densities and exact KEs is generated. As in the previous sections, we use KRR to learn the KE of this mo del system. The formulation is identical to that of Ref. [ 10 ]: T ML [ n ] = N T X j =1 α j k [ n, n j ] , (45) 11 4 2 0 2 4 l o g σ 5 0 5 l o g ∆ T 3 5 9 17 33 65 λ = 1 0 − 6 FIG. 17. The error of the model, ∆T (Hartree), as a function of σ , for fixed λ = 10 − 6 . N T v alues for each curve are given in the legend. where k is the Gaussian k ernel k [ n, n 0 ] = exp( −k n − n 0 k 2 / (2 σ 2 )) , (46) and k n − n 0 k 2 = ∆x N G X j =1 ( n ( x j ) − n 0 ( x j )) 2 , (47) where ∆x = 1 / ( N G − 1) is the grid spacing. The weigh ts are again given by Eq. ( 6 ), found b y minimizing the cost function in Eq. ( 4 ). In analogy to Eq. ( 7 ), w e measure the error of the mo del as the total squared error integrated ov er the in- terp olation region ∆T = Z 100 0 dD ( T ML [ n D ] − T [ n D ]) 2 , (48) where n D is the exact density for the p oten tial with w ell depth D , and T [ n D ] is the exact corresp onding KE. W e appro ximate the in tegral by Simpson’s rule ev aluated on D sampled ov er the test set (i.e., 500 v alues spaced uni- formly ov er the interpolation region). This sampling is sufficien tly dense ov er the interv al to giv e an accurate appro ximation to ∆T . In Fig. 17 , we plot ∆T as a function of the length scale of the Gaussian kernel, σ , for v arious training set sizes N T . Clearly , the trends are very similar to Fig. 2 : the transition σ s b et w een the regions I and I I b ecomes smaller as N T increases, the v alley in region I I widens, and region I II on the right remains largely unchanged. The dep endence of σ s on N T app ears to follo w the same p o w er law σ s ∝ N p T , but the v alue of p is different in this case. A rough estimate yields p ≈ − 0 . 8, which is similar to p = − 1 for the simple cosine function explored in the previous sections, but the details will dep end on the specifics of the data. Similarly , Fig. 18 sho ws the same plot but with N T fixed and λ v aried. Again, the same features are present 10 -2 10 -8 10 -10 1 10 -4 10 -6 10 -12 10 -14 FIG. 18. The error of the model, ∆T (Hartree), as a function of σ , for v arious λ with N T = 33. The lab els giv e the v alue of λ for eac h curve. as in Fig. 3 , i.e., three regions with different qualitative b eha viors. In region I, ∆T has the same decay shape as the kernel functions (Gaussians) b egin to ov erlap signif- ican tly , making it p ossible for the regression to function prop erly and fit the data. F or large v alues of the regu- larization strength λ , the model o ver-regularizes, yielding high errors for an y v alue of σ . As λ decreases, the weigh ts are giv en more flexibility to conform to the shap e of KE functional. Using the same definition for the estimation of σ s in Eq. ( 10 ), the median nearest neigh b or distance o ver this training set gives σ s = 0 . 019. W e then hav e log σ s = − 1 . 72, which matc hes the boundary b et ween re- gions I and I I in Fig. 18 . In region I I I, the same plateau features emerge for small λ . Again, these plateaus occur when p olynomial forms of the regression mo del b ecome dominan t for certain combinations of the parameters σ , λ , and N T . F rom Eq. ( 12 ) and Eq. ( 13 ), w e show ed that the model error will tend to the b enchmark error while σ → 0 or λ → ∞ . Similarly to Eq. ( 8 ), w e can also define the b enc hmark error when T ML [ n ] ≡ 0 for this data set as ∆T 0 = Z 100 0 dD T 2 [ n D ] . (49) Ev aluating the abov e in tegral numerically on the test set, w e obtain log ∆T 0 = 3 . 7. This matches the error when σ → 0 in Fig. 17 and Fig. 18 . W e define the σ that giv es the global minimum of ∆T as ˜ σ ; similarly to Fig. 12 , we plot the optimal mo del error ∆T ( ˜ σ ) as a function of λ in Fig. 19 . F or large λ , w e o v erregularize the mo del; the mo del error tends to the b enc hmark error in Eq. ( 49 ). F or moderate λ , w e observ e the same linear prop ortionality ∆T ( ˜ σ ) ∝ λ as in Fig. 12 . In this to y system, the prediction of the KE from KRR mo dels shares prop erties similar to those that we ex- plored in learning the 1d cosine function. Now w e will consider up to 4 nonin teracting spinless fermions under 12 14 5 4 l o g λ 12 4 4 l o g ∆ T ( ˜ σ ) 3 5 9 17 33 65 FIG. 19. The dep endence of ∆T ( ˜ σ ) on λ for v arious N T . Here, ˜ σ minimizes ∆f for fixed N T and λ . N T v alues for eac h curv e are giv en in the legend. a potential with 9 parameters as reported in Ref. [ 10 ]. v ( x ) = − 3 X i =1 a i exp − ( x − b i ) 2 / (2 c 2 i ) . (50) These densities are represen ted on N G = 500 ev enly spaced grid p oin ts in 0 ≤ x ≤ 1. Here a mo del is built using N T / 4 pairs of electron densities and exact KEs for eac h particle num ber N = 1 , 2 , 3 , 4, resp ectively . Th us, the size of the training set is N T . 1000 pairs of electron densities and exact KEs are generated for each N , so the size of the test set is S = 4000. Since there are 9 param- eters in the p otential, we cannot define the error as an in tegral, so we use summation instead. Thus, the error on the test set is defined as the mean square error (MSE) on the test densities ∆T = S X j =1 ( T ML [ n j ] − T [ n j ]) 2 /S. (51) Fig. 1 shows the error of the mo del as a function of σ with v arious N T for fixed λ = 10 − 10 . Although this system is more complicated than the previous tw o sys- tems discussed in this pap er, the qualitative b eha viors in Fig. 1 are similar to Fig. 2 and Fig. 17 . T able I in Ref. [ 10 ] only shows the model error with optimized hyperparam- eters for N T = 400. In Fig. 20 , model errors v arying with a wide range of σ v alues are shown for 4 different v alues of λ [ 34 ]. The qualitative prop erties in Fig. 20 are similar to Fig. 3 and Fig. 18 . F or example, the ex- istence of three regions with distinctly differen t b eha vior for the mo del error can b e ascertained just lik e b efore. In region I, error curves with different λ will all tend to the same b enc hmark error limit when σ → 0. The median nearest neigh b or distance o ver this training se t giv es σ s = 0 . 022. In Fig. 20 , the b oundary b et ween re- gion I and region I I is w ell estimated b y log σ s = − 1 . 66. In region I II, the familiar plateau features emerge. In region I I, where σ is such that the mo del is optimal or 3.2x10 -14 10 -10 10 -6 10 -2 FIG. 20. Dep endence of the model error (as a function of σ ) for v arious λ . The lab els give the v alue of λ for each curve. The λ = 3 . 2 × 10 − 14 curv e is not plotted for log σ > 5 . 5 due to the numerical instability that o ccurs when λ is small for large σ . close to it, we find that the mo del with hyperparame- ters σ = 1 . 86 , λ = 3 . 2 × 10 − 14 p erforms the b est. The MSE for this mo del is 1 . 43 × 10 − 7 Hartree. A nother com- mon measure of error is the mean absolute error (MAE), whic h is also used in Ref. [ 10 ]. The MAE of this mo del is 1 . 99 × 10 − 4 Hartree = 0 . 12 k cal / mol. This result is consis- ten t with the mo del p erformance rep orted in Ref. [ 10 ][ 35 ]. V. CONCLUSION In this work, we hav e analyzed the properties of KRR mo dels with a Gaussian kernel applied to fitting a simple 1d function. In particular, we hav e explored regimes of distinct qualitativ e b ehavior and deriv ed the asymptotic b eha vior in certain limits. Finally , we generalized our findings to the problem of learning the KE functional of a single particle confined to a b ox and sub ject to a well p oten tial with v ariable depth. Considering the v ast dif- ference in nature of the tw o problems compared in this w ork, a 1d cosine function and the KE as a functional of the electron densit y (a v ery high-dimensional ob ject), the similarities of the measures of error ∆f and ∆T b et ween eac h other are remark able. This analysis demonstrates that m uch of the b ehavior of the mo del can b e rational- ized b y and distilled do wn to the properties of the k ernel. Our goal in this work was to deep en our understanding of how the p erformance of KRR dep ends on the param- eters qualitatively , in particular in the case that is rele- v an t for MLA in DFT, namely the one of noise-free data and high-dimensional inputs, and how one may deter- mine a-priori whic h regimes the mo del lies in. F rom the ML p ersp ectiv e the scenario analyzed in this w ork w as an unusual one: small data, virtually no noise, low di- mensions and high complexity . The effects found are not only interesting from the physics p erspective, bu t are also 13 illuminating from a learning theory p oin t of view. How- ev er, in ML practice the extremes that contain plateaus or the “comb” region will not b e observ able, as the prac- tical data with its noisy manifold structure will confine learning in the fav orable region I I. F uture work will fo- cus on theory and practice in order to impro ve learning tec hniques for lo w noise problems. A CKNOWLEDGMENTS The authors would lik e to thank NSF Gran t No. CHE- 1240252 (JS, LL, KB), the Alexander von Humboldt F oundation (JS), the Undergraduate Research Opp ortu- nities Program (UR OP) and the Summer Undergraduate Researc h Program (SURP) (KV) at UC Irvine for fund- ing. MR thanks O. Anatole von Lilienfeld for supp ort via SNSF Gran t No. PPOOP2 138932. App endix A: Expansion of ∆f for σ σ s ∆f = Z 1 0 dx f ( x ) 2 − 2 N T X j =1 α j Z 1 0 dx f ( x ) k ( x, x j ) + N T X i,j =1 α i α j Z 1 0 dx k ( x, x i ) k ( x, x j ) . (A1) where the first integral is given in Eq. ( 9 ). Next Z 1 0 dx f ( x ) k ( x, x j ) = r π 8 σ e − ( γ σ ) 2 / 2 ( C j + C ∗ j ) , (A2) where C j = e i γ x j erf x j − i γ σ 2 σ √ 2 + erf 1 − x j + i γ σ 2 σ √ 2 , (A3) erf is the error function, and C ∗ denotes the complex conjugate of C . The last in tegral is Z 1 0 dx k ( x, x i ) k ( x, x j ) = σ √ π 2 e − ( x i − x j ) 2 / (4 σ 2 ) × erf x i + x j 2 σ − erf x i + x j − 2 2 σ . (A4) App endix B: ∆f β for N T = 3 ∆f β = h 01 1 3 ( − 5 f 1 − 2 f 2 + f 3 ) + f 1 − f 3 β + 1 + 2 β h 11 ( f 1 − f 3 ) β + 1 + h 02 + C , (B1) where C = ( β 2 (7 f 2 1 + 2 f 1 (4 f 2 + f 3 ) + 4 f 2 2 + 8 f 2 f 3 + 7 f 2 3 ) + 36(2 β + 1) f 2 ) / (36( β + 1) 2 ) , (B2) and where f = 1 3 ( f 1 + f 2 + f 3 ). App endix C: ∆f for N T = 3 ∆f = C 1 h 01 + C 2 h 11 + C 3 h 21 + h 02 + C 4 , (C1) where C 1 = (( √ λ (48 f − 2 (17 f 1 + 4 f 2 + f 3 )) − 2 ( f 1 ( 2 − 20) − 8 f 2 + 4 f 3 ) − 4 λ ( f 2 + 4 f 3 ))) / (( √ λ + )( − 8( λ + 3) + 2 + 8 √ λ )) , (C2) C 2 = (2 (2 √ λ (9 f 1 + 2 f 2 + f 3 ) + 3 f 1 2 − 24 f 1 + 8 λ ( f 2 + 2 f 3 ) − 4 f 2 2 + f 3 2 + 24 f 3 )) / (( √ λ + )( − 8( λ + 3) + 2 + 8 √ λ )) , (C3) C 3 = 4 ( − f 1 + 2 f 2 − f 3 ) − 12 f √ λ − 8( λ + 3) + 2 + 8 √ λ , (C4) C 4 = (2 √ λ ( 4 (75 f 2 1 + 2 f 1 (58 f 2 − 5 f 3 ) + 48 f 2 2 + 116 f 2 f 3 + 75 f 2 3 ) − 480 2 (5 f 2 1 + 5 f 1 f 2 + 2 f 1 f 3 + 2 f 2 2 + 5 f 2 f 3 + 5 f 2 3 ) + 34560 f 2 ) + 3 λ ( 4 (273 f 2 1 + 232 f 1 f 2 + 226 f 1 f 3 + 48 f 2 2 + 232 f 2 f 3 + 273 f 2 3 ) − 160 2 (7 f 2 1 + 15 f 1 ( f 2 + 2 f 3 ) + 4 f 2 2 + 15 f 2 f 3 + 7 f 2 3 ) + 11520 f 2 ) + 8 λ 3 / 2 ( 2 (40 f 2 1 + 91 f 1 f 2 + 400 f 1 f 3 + 16 f 2 2 + 91 f 2 f 3 + 40 f 2 3 ) − 240 f (4 f 1 + f 2 + 4 f 3 )) + 4 6 (2 f 2 1 + 2 f 1 f 2 − f 1 f 3 + 8 f 2 2 + 2 f 2 f 3 + 2 f 2 3 ) − 80 4 (5 f 2 1 + 10 f 1 f 2 − 2 f 1 f 3 + 8 f 2 2 + 10 f 2 f 3 + 5 f 2 3 ) + 16 λ 2 2 (48 f 2 1 + 16 f 1 ( f 2 + f 3 ) + 3 f 2 2 + 16 f 2 f 3 + 48 f 2 3 ) + 960 2 (7 f 2 1 + 2 f 1 (4 f 2 + f 3 ) + 4 f 2 2 + 8 f 2 f 3 + 7 f 2 3 )) / (60( √ λ + ) 2 ( − 8( λ + 3) + 2 + 8 √ λ ) 2 ) , (C5) and where f = 1 3 ( f 1 + f 2 + f 3 ). 14 [1] Klaus-Rob ert M ¨ uller, Sebastian Mik a, Gunnar R¨ atsc h, Ko ji Tsuda, and Bernhard Sc h¨ olkopf, “An Introduc- tion to Kernel-Based Learning Algorithms,” IEEE T rans. Neural Netw ork 12 , 181–201 (2001). [2] Igor Kononenko, “Mac hine learning for medical diagno- sis: history , state of the art and p erspective,” Artificial In telligence in medicine 23 , 89–109 (2001). [3] F abrizio Sebastiani, “Mac hine learning in automated text categorization,” A CM computing surveys (CSUR) 34 , 1– 47 (2002). [4] O. Iv anciuc, “Applications of Supp ort V ector Machines in Chemistry,” in R eviews in Computational Chemistry , V ol. 23, edited b y Kenny Lipko witz and T om Cundari (Wiley , Hob oken, 2007) Chap. 6, pp. 291–400. [5] Alb ert P . Bart´ ok, Mik e C. Pa yne, Risi Kondor, and G´ abor Cs´ anyi, “Gaussian Approximation P otentials: The Accuracy of Quan tum Mec hanics, without the Elec- trons,” Phys. Rev. Lett. 104 , 136403 (2010) . [6] Matthias Rupp, Alexandre Tk atc henk o, Klaus-Rob ert M ¨ uller, and O. Anatole von Lilienfeld, “F ast and ac- curate mo deling of molecular atomization energies with mac hine learning,” Ph ys. Rev. Lett. 108 , 058301 (2012) . [7] Zachary D. P ozun, Katja Hansen, Daniel Sheppard, Matthias Rupp, Klaus-Rob ert M ¨ uller, and Graeme Henk elman, “Optimizing transition states via kernel- based mac hine learning,” The Journal of Chemical Ph ysics 136 , 174101 (2012) . [8] Katja Hansen, Gr´ egoire Monta v on, F ranzisk a Biegler, Siamac F azli, Matthias Rupp, Matthias Scheffler, O. Anatole von Lilienfeld, Alexandre Tk atc henk o, and Klaus-Rob ert M ¨ uller, “Assessmen t and V alida- tion of Machine Learning Methods for Predicting Molecular Atomization Energies,” Journal of Chem- ical Theory and Computation 9 , 3404–3419 (2013) , h ttp://pubs.acs.org/doi/p df/10.1021/ct400195d . [9] K. T. Sch¨ utt, H. Gla we, F. Brockherde, A. Sanna, K. R. M ¨ uller, and E. K. U. Gross, “How to represent crystal structures for machine learning: T ow ards fast prediction of electronic properties,” Ph ys. Rev. B 89 , 205118 (2014) . [10] John C. Snyder, Matthias Rupp, Katja Hansen, Klaus- Rob ert M ¨ uller, and Kieron Burke, “Finding Densit y F unctionals with Machine Learning,” Phys. Rev. Lett. 108 , 253002 (2012) . [11] John C. Sn yder, Matthias Rupp, Katja Hansen, Leo Blo oston, Klaus-Rob ert M ¨ uller, and Kieron Burk e, “Orbital-free Bond Breaking via Machine Learning,” J. Chem. Phys. 139 , 224104 (2013) . [12] Li Li, John C. Sn yder, Isab elle M. Pelasc hier, Jessica Huang, Uma-Naresh Niranjan, Paul Duncan, Matthias Rupp, Klaus-Rob ert M ¨ uller, and Kieron Burke, “Un- derstanding Machine-learned Density F unctionals,” sub- mitted and ArXiv:1404.1333 (2014) . [13] John Snyder, Sebastian Mik a, Kieron Burke, and Klaus- Rob ert M ¨ uller, “Kernels, Pre-Images and Optimization,” in Empiric al Infer enc e - F estschrift in Honor of Vladimir N. V apnik , edited b y Bernhard Schoelkopf, Zhiyuan Luo, and Vladimir V o vk (Springer, Heidelb erg, 2013). [14] John C. Snyder, Matthias Rupp, Klaus-Rob ert M ¨ uller, and Kieron Burk e, “Non-linear gradien t denoising: Find- ing accurate extrema from inaccurate functional deriv a- tiv es,” International Journal of Quantum Chemistry in preparation (2015). [15] K. Burke, “Exact conditions in tddft,” Lect. Notes Ph ys 706 , 181 (2006). [16] T revor Hastie, Robert Tibshirani, and Jerome F riedman, The Elements of Statistic al L e arning: Data Mining, In- fer enc e, and Pr e diction , 2nd ed. (Springer, New Y ork, 2009). [17] Ira N Levine, Quantum chemistry , V ol. 6 (P earson Pren- tice Hall Upp er Saddle Riv er, NJ, 2009). [18] R. M. Dreizler and E. K. U. Gross, Density F unctional The ory: An Appr o ach to the Quantum Many-Body Pr ob- lem (Springer–V erlag, Berlin, 1990). [19] P . Hohenberg and W. Kohn, “Inhomogeneous electron gas,” Phys. Rev. 136 , B864–B871 (1964) . [20] W. Kohn and L. J. Sham, “Self-consistent equations in- cluding exc hange and correlation effects,” Phys. Rev. 140 , A1133–A1138 (1965) . [21] Aurora Pribram-Jones, David A. Gross, and Kieron Burk e, “DFT: A Theory F ull of Holes?” Annual Review of Physical Chemistry (2014) . [22] W e will use log to denote log 10 here and throughout this w ork. [23] Carl Rasm ussen and Christopher Williams, Gaussian Pr o c esses for Machine L e arning (MIT Press, Cam bridge, 2006). [24] Alex J Smola, Bernhard Sch¨ olkopf, and Klaus-Rob ert M ¨ uller, “The connection b etw een regularization op era- tors and supp ort vector k ernels,” Neural netw orks 11 , 637–649 (1998). [25] John Mo o dy and Christian J. Darken, “F ast Learning in Net works of Locally-tuned Pro cessing Units,” Neural Comput. 1 , 281–294 (1989) . [26] D. Saad, On-line learning in neur al networks (Cambridge Univ ersity Press, New Y ork, 1998). [27] Saad D. and Solla S., “On-line learning in soft committee mac hines,” Phys. Rev. E 52 , 4225–4243 (1995) . [28] M. Biehl, P . Riegler, and C. W¨ ohler, “T ransien t dynam- ics of on-line learning in tw o-la yered neural net works,” Journal of Ph ysics A: Mathematical and General 29 , 4769–4780 (1996). [29] Kenji F ukumizu and Shun ichi Amari, “Lo cal minima and plateaus in hierarchical structures of multila yer p er- ceptrons.” Neural Netw orks 13 , 317–327 (2000) . [30] Haikun W ei and Shun ichi Amari, “Dynamics of learn- ing near singularities in radial basis function netw orks.” Neural Netw orks 21 , 989–1005 (2008) . [31] K-R M ¨ uller, M Finke, N Murata, K Sc hulten, and S Amari, “A numerical study on learning curves in sto c hastic multila yer feedforward netw orks,” Neural Computation 8 , 1085–1106 (1996). [32] C. F. von W eizs¨ ack er, “Zur theorie der kernmassen,” Zeitsc hrift f ¨ ur Physik A Hadrons and Nuclei 96 , 431–458 (1935) , 10.1007/BF01337700. [33] Attila Cangi, Donghyung Lee, Peter Elliott, Kieron Burk e, and E. K. U. Gross, “Electronic structure via p oten tial functional approximations,” Phys. Rev. Lett. 106 , 236404 (2011) . [34] F or large σ , if λ is small, there will b e numerical in- stabilit y in the computation of ( K + λ I ) − 1 . Thus, the λ = 3 . 2 × 10 − 14 curv e is not plotted for log σ > 5 . 5. 15 [35] In Ref. [ 10 ], the densities were treated as v ectors. Here, w e treated the densities as functions, so the length scale men tioned here is related to the length scale in Ref. [ 10 ] b y a factor of √ ∆x = 0 . 045.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment