Flow Distances on Open Flow Networks
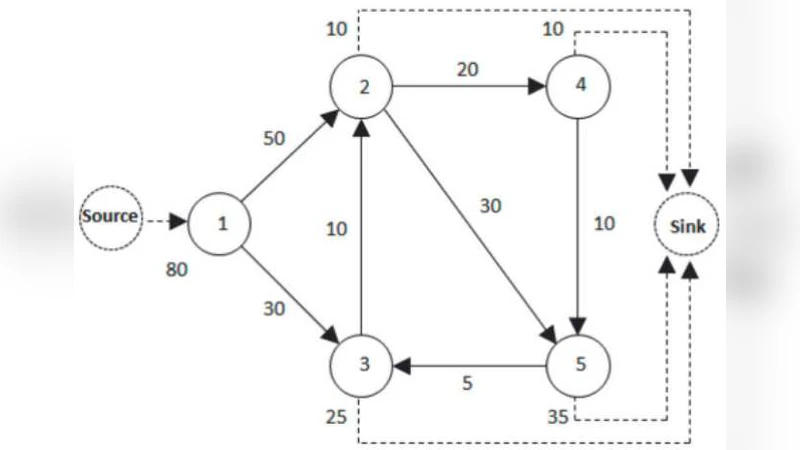
Open flow network is a weighted directed graph with a source and a sink, depicting flux distributions on networks in the steady state of an open flow system. Energetic food webs, economic input-output networks, and international trade networks, are open flow network models of energy flows between species, money or value flows between industrial sectors, and goods flows between countries, respectively. Flow distances (first-passage or total) between any given two nodes $i$ and $j$ are defined as the average number of transition steps of a random walker along the network from $i$ to $j$ under some conditions. They apparently deviate from the conventional random walk distance on a closed directed graph because they consider the openness of the flow network. Flow distances are explicitly expressed by underlying Markov matrix of a flow system in this paper. With this novel theoretical conception, we can visualize open flow networks, calculating centrality of each node, and clustering nodes into groups. We apply flow distances to two kinds of empirical open flow networks, including energetic food webs and economic input-output network. In energetic food webs example, we visualize the trophic level of each species and compare flow distances with other distance metrics on graph. In input-output network, we rank sectors according to their average distances away other sectors, and cluster sectors into different groups. Some other potential applications and mathematical properties are also discussed. To summarize, flow distance is a useful and powerful tool to study open flow systems.
💡 Research Summary
This paper introduces a novel framework for measuring distances in open flow networks—directed weighted graphs that include a designated source and sink to model systems where material, energy, or value continuously enters and leaves the network. Traditional graph‑theoretic distances such as shortest‑path length, resistance distance, or first‑passage time assume a closed system where a random walker cannot escape. In contrast, the authors explicitly incorporate the openness of the system by defining two types of flow‑based distances: first‑passage flow distance (FPD) and total flow distance (TFD). Both are expressed analytically in terms of the underlying Markov transition matrix derived from the flow matrix of the network.
The construction begins with an (N + 2) × (N + 2) flow matrix F, where rows and columns correspond to N ordinary nodes plus a source (node 0) and a sink (node N + 1). The element fᵢⱼ denotes the amount of material that moves from i to j per unit time. Assuming the system is in a steady state, every ordinary node satisfies inflow = outflow, guaranteeing a balanced network. From F the authors build a Markov matrix M by normalizing each row (excluding the sink column), so mᵢⱼ = fᵢⱼ / Σⱼ fᵢⱼ for j ≠ N + 1. The sink row consists of zeros, which is the key distinction from closed‑network Markov chains.
Two flow quantities are distinguished. The first‑passage flow φᵢⱼ counts particles that reach node j for the first time when starting from i; the total flow ρᵢⱼ counts all particles that ever visit j, including repeated visits (circulation flow ψᵢⱼ). Using the fundamental matrix U = (I − M)⁻¹ = I + M + M² + …, the authors derive compact expressions: ρᵢⱼ = φ₀ᵢ uᵢⱼ and φᵢⱼ = ρᵢⱼ / uⱼⱼ, where φ₀ᵢ is the flow from the source to i and uᵢⱼ are entries of U.
The distances are defined as expected step counts. The total flow distance tᵢⱼ = Σₖ k pₖᵢⱼ uses pₖᵢⱼ, the probability that a particle starting at i reaches j after exactly k steps (including revisits). By expressing pₖᵢⱼ = φ₀ᵢ (Mᵏ)ᵢⱼ / ρᵢⱼ and summing over k, the authors obtain tᵢⱼ = (M U²)ᵢⱼ / uᵢⱼ. The first‑passage distance lᵢⱼ = Σₖ k qₖᵢⱼ uses qₖᵢⱼ, the probability of first arrival after k steps. To isolate first arrivals, node j is temporarily turned into an absorbing sink, which leads to a modified transition matrix M^{−j} (row and column j removed). This yields lᵢⱼ = uⱼⱼ (M^{−j}U²^{−j})ᵢⱼ / uᵢⱼ, which simplifies to lᵢⱼ = tᵢⱼ − tⱼⱼ when uᵢⱼ ≠ 0. Hence the difference between the two distances is precisely the self‑circulation distance of node j.
Because lᵢⱼ is generally asymmetric, the authors propose a symmetric flow distance cᵢⱼ = 2 lᵢⱼ lⱼᵢ / (lᵢⱼ + lⱼᵢ). This formulation remains finite even when one direction is unreachable (infinite l). The symmetric distance enables clustering, centrality analysis, and other tasks that require metric properties.
The theoretical development is illustrated on a small seven‑node example (including source and sink). Matrices of first‑passage distances (L) and total flow distances (T) are computed, revealing many infinite entries where no directed path exists. Comparisons with classic shortest‑path lengths and with first‑passage distances computed on the closed version of the same network (source and sink removed) show that: (1) shortest‑path distances severely underestimate actual particle travel because they ignore longer, possibly more probable routes; (2) closed‑network first‑passage distances are larger than the open‑network counterparts because they neglect dissipation to the sink.
Two real‑world applications demonstrate the utility of the framework.
- Energetic food webs: Nodes represent species, edge weights are energy transfers. The first‑passage distance matrix visualizes trophic levels, and its correlation with other graph‑based distances is examined. The results confirm that lᵢⱼ captures both hierarchical (trophic) ordering and cyclic energy recycling.
- Economic input‑output networks: Nodes are industrial sectors, edge weights are monetary flows. The average first‑passage distance from a sector to all others serves as a novel centrality measure, highlighting sectors that are “close” to the rest of the economy. Using k‑means clustering on the distance matrix, sectors are grouped into functional clusters (e.g., core producers, intermediate processors, final consumers).
The paper discusses broader implications: the flow‑distance concept naturally integrates directionality, circulation, and loss, which are absent in traditional graph metrics. Computationally, the reliance on matrix operations (M, U, and their variants) allows efficient implementation even for large sparse networks, especially when leveraging iterative solvers for (I − M)⁻¹. Potential extensions include risk assessment in supply chains, analysis of ecological stability, and optimization of transport or communication networks where inflow/outflow dynamics are essential.
In summary, this work provides a rigorous, analytically tractable definition of distances tailored to open flow systems, demonstrates how these distances differ from conventional closed‑graph measures, and validates their practical relevance through ecological and economic case studies. The introduced metrics open new avenues for structural and dynamical analysis of a wide class of real‑world networks where openness is a defining feature.
Comments & Academic Discussion
Loading comments...
Leave a Comment