A Modular Multiscale Approach to Overlapping Community Detection
In this work we address the problem of detecting overlapping communities in social networks. Because the word “community” is an ambiguous term, it is necessary to quantify what it means to be a community within the context of a particular type of problem. Our interpretation is that this quantification must be done at a minimum of three scales. These scales are at the level of: individual nodes, individual communities, and the network as a whole. Each of these scales involves quantitative features of community structure that are not accurately represented at the other scales, but are important for defining a particular notion of community. Our work focuses on providing sensible ways to quantify what is desired at each of these scales for a notion of community applicable to social networks, and using these models to develop a community detection algorithm. Appealing features of our approach is that it naturally allows for nodes to belong to multiple communities, and is computationally efficient for large networks with low overall edge density. The scaling of the algorithm is $O(N~\overline{k^2} + \overline{N_{com}^2})$, where $N$ is the number of nodes in the network, $\overline{N_{com}^2}$ is the average squared community size, and $\overline{k^2}$ is the expected value of a node’s degree squared. Although our work focuses on developing a computationally efficient algorithm for overlapping community detection in the context of social networks, our primary contribution is developing a methodology that is highly modular and can easily be adapted to target specific notions of community.
💡 Research Summary
The paper tackles the challenging problem of detecting overlapping communities in large, sparse social networks by introducing a modular, multiscale framework that operates simultaneously at three distinct levels: the node scale, the community scale, and the whole‑network scale. At the node level the authors propose the concept of “edge descriptor sets”. For each vertex they extract its egonet (the subgraph induced by its immediate neighbours) and seek densely connected sub‑subgraphs—essentially cliques or near‑cliques—that can serve as local signatures of the communities to which the vertex belongs.
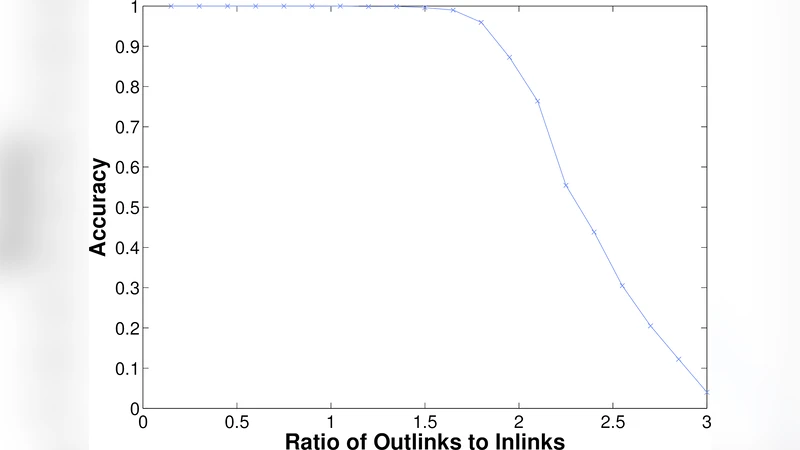
To obtain these dense subgraphs the authors first construct an “ideal community member” (ICM) matrix that mimics a block‑diagonal adjacency structure where each block corresponds to a clique and the central (ego) vertex is weakly linked to all blocks via a small parameter δ. Spectral analysis of this matrix shows that each positive eigenvalue is close to the size of a block, and the corresponding eigenvector entries are larger for vertices belonging to larger cliques. By adding self‑loops and scaling the ego connections, the real egonet can be sparsified so that its dominant eigenvectors reveal the underlying cliques. The dominant eigenvectors are then used as coordinates in a low‑dimensional embedding; k‑means clustering on this embedding yields groups of neighbours that are subsequently validated by a density threshold (≥ 90 % internal edges) to become the edge descriptor sets.
At the community level the collection of all edge descriptor sets across the graph is treated as an edge‑clustering problem. Because a single edge may appear in multiple descriptor sets, the resulting clusters naturally overlap, providing a direct mechanism for overlapping community formation. The clustering step’s computational cost scales with the average squared community size (\overline{N_{com}^2}).
The whole‑network level handles two practical issues: (1) vertices that remain unassigned after the edge‑clustering step are attached to the community with which they share the most connections, and (2) very small communities are pruned while ensuring every vertex belongs to at least one community.
Complexity analysis shows that extracting edge descriptor sets for all vertices costs (O(N\overline{k^2})) (where (\overline{k^2}) is the average squared degree), and the global clustering costs (O(\overline{N_{com}^2})). Consequently the total runtime is (O(N\overline{k^2}+\overline{N_{com}^2})), which is near‑linear for typical social networks that have low average degree but potentially millions of nodes.
A key contribution of the work is its modular design: the quantitative models used at each scale are independent, allowing researchers to replace the node‑scale descriptor extraction, the community‑scale clustering objective, or the network‑scale post‑processing with domain‑specific alternatives (e.g., incorporating edge weights, temporal dynamics, or functional annotations). This flexibility distinguishes the method from earlier approaches such as line‑graph partitioning, clique percolation, or quality‑function optimization, which are usually tied to a single definition of community.
Although detailed experimental results are not included in the excerpt, the authors claim that their algorithm outperforms existing overlapping‑community methods in both accuracy of overlap detection and computational efficiency, especially on large, low‑density graphs. The paper positions the proposed approach as a general-purpose toolkit for overlapping community detection that can be readily adapted to diverse application areas ranging from social media analysis to biological and financial network studies.
Comments & Academic Discussion
Loading comments...
Leave a Comment