Classification of Message Spreading in a Heterogeneous Social Network
Nowadays, social networks such as Twitter, Facebook and LinkedIn become increasingly popular. In fact, they introduced new habits, new ways of communication and they collect every day several information that have different sources. Most existing research works fo-cus on the analysis of homogeneous social networks, i.e. we have a single type of node and link in the network. However, in the real world, social networks offer several types of nodes and links. Hence, with a view to preserve as much information as possible, it is important to consider so-cial networks as heterogeneous and uncertain. The goal of our paper is to classify the social message based on its spreading in the network and the theory of belief functions. The proposed classifier interprets the spread of messages on the network, crossed paths and types of links. We tested our classifier on a real word network that we collected from Twitter, and our experiments show the performance of our belief classifier.
💡 Research Summary
The paper addresses the problem of classifying social media messages by analyzing how they spread through heterogeneous social networks, where nodes and links can belong to multiple types (e.g., professional, familial, friendly, undefined). While most prior work focuses on homogeneous networks with a single node and link type, the authors argue that real‑world platforms such as Twitter, Facebook, and LinkedIn exhibit rich, multi‑type structures that should be preserved for more accurate modeling.
To this end, they propose a two‑stage framework: (1) a propagation algorithm that simulates message diffusion across a heterogeneous graph, and (2) a classification algorithm that uses the theory of belief functions (evidence theory) to assign a message to one of several predefined categories (Spam, Professional, Familial). The propagation algorithm takes as input the number of iterations, a source node, a propagation strategy, and the heterogeneous network. For each active node, it computes the number of neighbors to be reached for each link type by multiplying the node’s out‑degree, a node‑specific propagation tendency parameter, and the proportion defined by the chosen strategy. Neighbors are then selected randomly, and the process repeats for the specified number of iterations, producing a propagation network (PrNet) that records which nodes receive the message at each hop (propagation level).
During the learning phase, a collection of PrNets generated for each strategy is processed to count, for every level, how many nodes were reached via each link type. These counts are accumulated, normalized into probability distributions (ProbaSet), and subsequently transformed into basic belief assignments (BBA) using a consonant transformation. Thus, for each strategy the system stores both a probabilistic model and an evidential model.
The classification phase mirrors the learning step on a new, unseen PrNet. It computes the distance between the new PrNet’s level‑wise probability distribution and each strategy’s stored distribution using Euclidean distance, and the distance between the new BBA and each stored BBA using the Jousselme distance. The strategy with the smallest distance at a given level is selected as the predicted class for that level, yielding a multi‑level classification output.
Experiments were conducted on a Twitter dataset collected with NodeXL, comprising 97 users and 350 directed edges. Four link types were assigned randomly to emulate heterogeneity. Three propagation strategies (Spam, Professional, Familial) were defined, each specifying the proportion of nodes reached per link type; a noise factor was added to simulate real‑world uncertainty. For each strategy, 100 propagation networks were generated for training and another 100 for testing. The number of propagation levels was fixed to three.
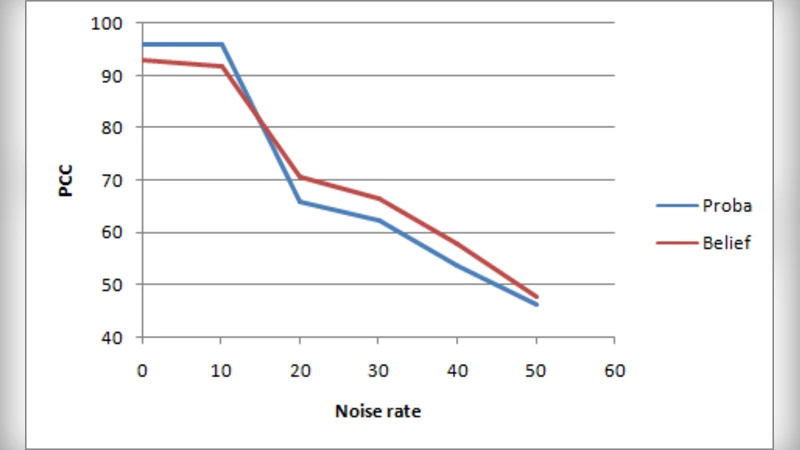
Results show that the evidential classifier’s percentage of correctly classified propagation networks (PCC) improves consistently with the propagation level, especially when the noise level exceeds 20 %. In contrast, the probabilistic classifier’s PCC plateaus after the second level and does not benefit as much from deeper propagation. At zero noise, the probabilistic approach attains about 96 % PCC while the evidential approach reaches 93 %; however, as noise increases, the evidential method surpasses the probabilistic one, demonstrating greater robustness to uncertainty.
Key contributions of the paper are:
- Introduction of a diffusion model that explicitly incorporates heterogeneous node and link types along with message‑specific propagation strategies.
- A pipeline that converts level‑wise propagation statistics into both probability distributions and belief function representations, enabling dual‑mode classification.
- Empirical evidence that belief‑function‑based classification outperforms traditional probabilistic methods under realistic noisy conditions and benefits from deeper diffusion histories.
The authors suggest future work such as learning link‑type weights dynamically, integrating textual content for multimodal classification, scaling the approach to real‑time streaming data, and validating the framework on other platforms (e.g., Facebook, Instagram). Such extensions could enhance applications in opinion mining, crisis detection, targeted marketing, and broader social network analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment