"Should I break up with my girlfriend? Will I find another?" Or: An Algorithm for the Forecasting of Romantic Options
The prospect of finding love may be scary but the prospect of committing to a relationship for the rest of your life is almost certainly scary. The secretary problem is a parallel to romantic decision making where an individual decides when to be satisfied with a selection choice in the face of uncertain future options. However, the secretary problem and its variations still do not provide a practical solution in a world where individual preference, goals, and societal context create a highly complex space of values that factor into decision making. In light of these complexities, we offer a general process that can determine the value of romantic options in a highly personal context. This algorithm is currently being developed into a service that will be available in 2015 for the general public.
💡 Research Summary
The paper “Should I break up with my girlfriend? Will I find another?” attempts to cast romantic decision‑making into a formal, quantitative framework by extending the classic secretary problem. The authors argue that existing matchmaking services and psychometric tests only identify potential partners but do not help users evaluate the long‑term value of staying in a current relationship versus remaining single or seeking a new partner. To fill this gap they propose the “Nanaya algorithm,” a multi‑stage process that incorporates personal psychological traits, demographic group membership, interaction frequencies, and historical relationship data.
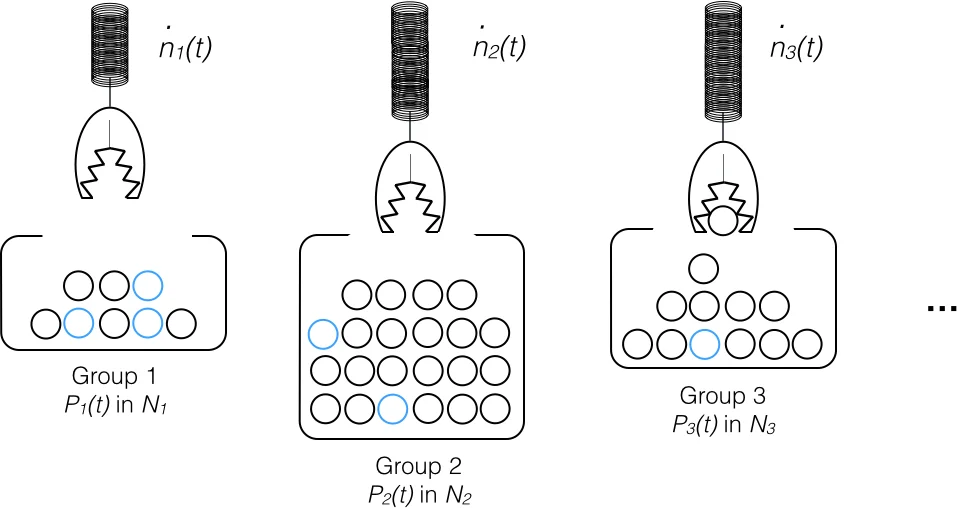
First, the user supplies a psychometric profile, desired partner trait windows, demographic categories (gender, age, location, ethnicity), and information about any existing relationship and current emotional state. From these inputs the algorithm identifies the sub‑populations (sub‑groups) the user interacts with. For each sub‑group it calculates a single‑encounter match probability (P_G(t)) by searching a database for individuals whose trait vectors fall within the user‑specified windows. The algorithm also models how the size of the windows may expand or contract over time (e.g., due to romantic desperation or neuroticism) and incorporates projected demographic shifts.
Second, a sociological model estimates the rate at which the user encounters members of each sub‑group, denoted (\dot n_G(t)). This rate depends on the user’s social activity patterns, past interaction history, and the size of the sub‑group. By combining (P_G(t)) and (\dot n_G(t)) the authors derive a cumulative probability of finding a match over time. They treat this as a modified urn problem, assuming large populations so that a binomial distribution approximates the cumulative probability.
Third, two utility functionals are defined. The relational utility between two individuals is expressed as a weighted sum of absolute differences between the user’s ideal trait vector and the partner’s trait vector across a high‑dimensional space (dimension (D>3)). This utility depreciates over time in a compound‑interest‑like fashion, reflecting relationship decay. The single‑state utility is derived from the user’s life‑goal questionnaire and current emotional self‑assessment, producing a “single space” value. Both utilities are measured in arbitrary units; only relative comparisons matter.
To evaluate possible futures, the algorithm runs a Monte‑Carlo simulation. It generates a synthetic set of suitors for each sub‑group by performing principal component analysis on the observed trait distribution and sampling accordingly. For each synthetic suitor the relational utility is computed, yielding a distribution of penalties (or negative utilities). The mean and standard deviation of these penalties are compared with the utility of the current partner (if any). The paper presents two illustrative cases: a 28‑year‑old male with an existing girlfriend, and a 51‑year‑old male who is single. In the first case the projected utility of staying with the girlfriend exceeds the expected utility of any new match, despite relatively high probabilities of finding a high‑quality partner. In the second case the model predicts higher utility from remaining single given the user’s social context.
The authors acknowledge several limitations. The model relies on strong assumptions: large, static populations; accurate estimation of single‑encounter probabilities; and reliable psychometric data. The utility functions are highly subjective, and the Monte‑Carlo generation of suitors lacks empirical validation. Moreover, the paper provides only a handful of case studies, making generalization uncertain. Data privacy, the reliability of personality assessments, and bias correction in demographic databases are identified as practical challenges for the planned 2015 public service.
In summary, the paper offers an ambitious interdisciplinary framework that merges optimal stopping theory, probabilistic sociology, and utility economics to forecast romantic options. While the conceptual structure is novel, the implementation details, validation procedures, and sensitivity analyses are insufficient for immediate real‑world deployment. Future work should focus on gathering real user data, refining probability estimates for small or dynamic sub‑populations, and rigorously testing the utility models against longitudinal relationship outcomes.
Comments & Academic Discussion
Loading comments...
Leave a Comment