Polyphonic Music Generation by Modeling Temporal Dependencies Using a RNN-DBN
In this paper, we propose a generic technique to model temporal dependencies and sequences using a combination of a recurrent neural network and a Deep Belief Network. Our technique, RNN-DBN, is an amalgamation of the memory state of the RNN that allows it to provide temporal information and a multi-layer DBN that helps in high level representation of the data. This makes RNN-DBNs ideal for sequence generation. Further, the use of a DBN in conjunction with the RNN makes this model capable of significantly more complex data representation than an RBM. We apply this technique to the task of polyphonic music generation.
💡 Research Summary
The paper introduces a novel generative model called RNN‑DBN, which integrates a recurrent neural network (RNN) with a deep belief network (DBN) to capture both temporal dependencies and high‑level hierarchical representations in sequential data. The authors argue that while RNNs excel at modeling time‑series through their internal memory, a single-layer Restricted Boltzmann Machine (RBM) – as used in earlier RNN‑RBM approaches – is insufficient for representing the complex, high‑dimensional structure of polyphonic music. By replacing the RBM with a multi‑layer DBN, the model gains expressive power, while the RNN supplies a dynamic context that conditions the DBN’s parameters at each time step.
Model Architecture
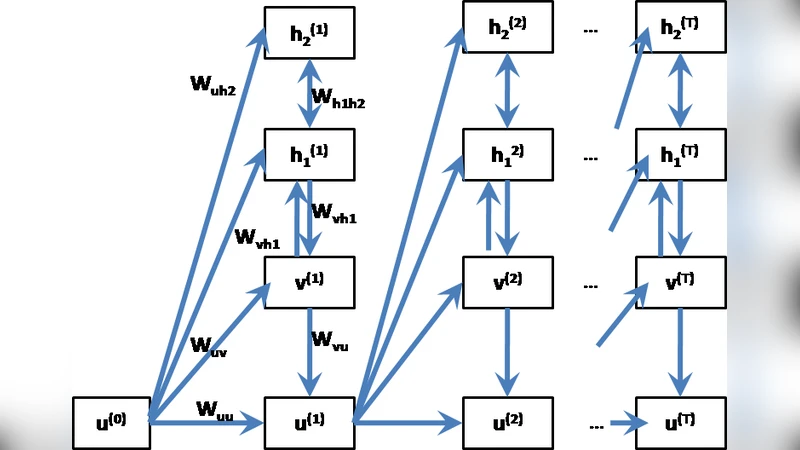
The RNN component computes a hidden state u(t) from the current visible vector v(t) (a binary piano‑roll of 88 notes) and the previous hidden state u(t‑1) using a sigmoid activation:
u(t) = σ(Wvu·v(t) + Wuu·u(t‑1) + bu).
These hidden states are then used to bias the DBN layers. The DBN consists of two hidden layers, each with 150 binary units, stacked on top of the 88‑unit visible layer. The biases of the first and second DBN hidden layers (b_h1, b_h2) and the visible bias (b_v) are functions of u(t), allowing the DBN to adapt its generative distribution conditioned on the temporal context supplied by the RNN.
Training Procedure
Training proceeds in a hybrid fashion:
- Forward‑propagate the RNN to obtain u(t) for each time step.
- Condition the DBN’s biases on u(t) and train each DBN layer greedily as an RBM using Contrastive Divergence (CD‑k).
- Compute log‑likelihood gradients for the DBN parameters.
- Back‑propagate these gradients through time (BPTT) to update the RNN parameters.
The authors also discuss practical enhancements such as initializing DBN weights with independently trained RBMs, pre‑training the RNN with cross‑entropy loss via stochastic gradient descent or Hessian‑free optimization, and applying gradient clipping and Nesterov momentum to stabilize training.
Experimental Setup
Four publicly available polyphonic datasets were used: JSB Chorales, MuseData, Nottingham, and Piano‑Midi.de. No preprocessing (e.g., key transposition or tempo normalization) was applied; raw binary piano‑roll sequences served as input. The model configuration was fixed across datasets: 2‑layer DBN (150 units per hidden layer), 150‑unit RNN, and 88‑unit visible layer. Performance was measured by log‑likelihood (LL) on held‑out test sequences, a standard metric for probabilistic sequence models.
Results
Table 1 shows that RNN‑DBN achieves LL scores comparable to or better than state‑of‑the‑art baselines such as RNN‑RBM, RNN‑NADE, and Recurrent Temporal RBM (RTRBM). For example, on the JSB Chorales dataset RNN‑DBN attains –5.68 LL, surpassing RNN‑RBM (–7.27) and RTRBM (–6.35). Similar trends are observed on MuseData, Nottingham, and Piano‑Midi.de. The authors attribute the remaining performance gap to the lack of preprocessing; they hypothesize that normalizing key and tempo would further improve the quality of generated music.
Analysis and Contributions
The key contribution is the seamless coupling of temporal dynamics (RNN) with deep hierarchical density estimation (DBN). This synergy enables the model to generate rich, non‑repetitive melodies while preserving long‑range musical structure. The paper also highlights practical considerations: the importance of proper initialization, the benefit of Hessian‑free fine‑tuning for the RNN, and the role of advanced optimization tricks (gradient clipping, Nesterov momentum). Limitations include high computational cost, sensitivity to hyper‑parameters, and restriction to binary piano‑roll representation.
Future Work
The authors outline several directions: exploring more sophisticated pre‑training regimes, applying the framework to other sequential domains (e.g., text, motion capture), incorporating additional musical attributes such as dynamics and articulation, and building interactive composition tools that leverage the model’s generative capabilities in real time.
In summary, the RNN‑DBN model advances the state of polyphonic music generation by marrying the memory of recurrent networks with the expressive depth of deep belief networks, achieving competitive log‑likelihood scores without any handcrafted feature engineering. The work opens avenues for broader applications of hybrid recurrent‑deep generative models across diverse sequence‑generation tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment