Computationally Efficient Implementation of a Hamming Code Decoder using a Graphics Processing Unit
This paper presents a computationally efficient implementation of a Hamming code decoder on a graphics processing unit (GPU) to support real-time software-defined radio (SDR), which is a software alternative for realizing wireless communication. The Hamming code algorithm is challenging to parallelize effectively on a GPU because it works on sparsely located data items with several conditional statements, leading to non-coalesced, long latency, global memory access, and huge thread divergence. To address these issues, we propose an optimized implementation of the Hamming code on the GPU to exploit the higher parallelism inherent in the algorithm. Experimental results using a compute unified device architecture (CUDA)-enabled NVIDIA GeForce GTX 560, including 335 cores, revealed that the proposed approach achieved a 99x speedup versus the equivalent CPU-based implementation.
💡 Research Summary
The paper presents a highly optimized implementation of a Hamming code decoder on a graphics processing unit (GPU) aimed at supporting real‑time software‑defined radio (SDR) applications. Traditional hardware solutions such as ASICs are inflexible for emerging standards, and general‑purpose processors (GPPs) or digital signal processors (DSPs) cannot meet the computational demands of modern SDR workloads. GPUs, with their massive parallelism, offer a promising alternative, but the Hamming decoding algorithm poses specific challenges for GPU execution.
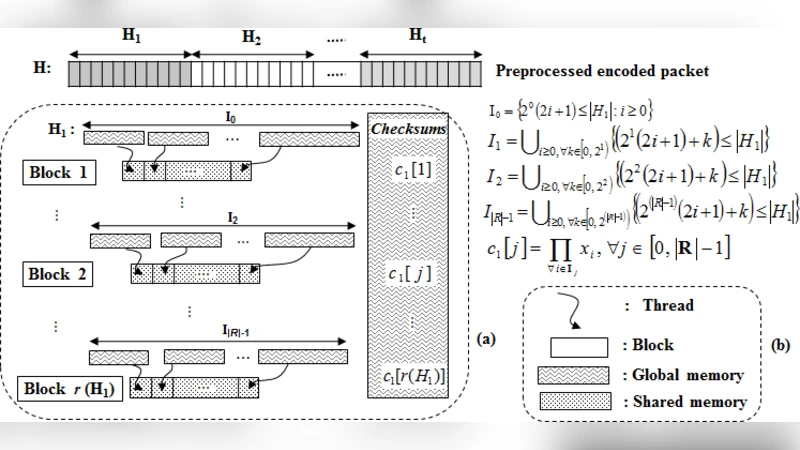
Hamming decoding reverses the encoding process by splitting an incoming packet into t segments, computing parity (checksum) bits for each segment, detecting and correcting errors, and finally removing redundancy. The algorithm accesses bits at non‑contiguous indices (sets I₀…I_{R‑1}) and contains many conditional branches, which leads to non‑coalesced global memory accesses, high latency, and severe thread divergence on a GPU.
To overcome these obstacles, the authors propose three key optimizations:
-
CPU‑side pre‑processing and data re‑ordering – Before transferring data to the GPU, the sparse parity bits are gathered into contiguous clusters (h₁, h₂, …) and the packet is rebuilt so that each segment occupies a continuous memory region. This transformation enables coalesced reads from global memory, dramatically increasing memory bandwidth utilization.
-
Asynchronous data transfer (ADT) – The pipeline consists of three independent tasks: packet send (PS) from host to device, device kernel execution (DKE), and packet receive (PR) from device to host. By using CUDA streams and overlapping these tasks, the authors hide most of the transfer latency. Compared with synchronous data transfer (SDT), ADT reduces the total execution time by at least a factor of two, especially when processing many packets.
-
Two‑kernel design with shared‑memory optimization –
Checksum kernel: Each CUDA block is assigned to compute one parity bit. The relevant bits of a segment are first copied into shared memory, then a reduction‑tree XOR operation is performed. The kernel is carefully crafted to avoid shared‑memory bank conflicts by distributing data across different banks.
Error‑correction kernel: Using the checksum vector, this kernel identifies erroneous bit positions, toggles them, and removes the redundancy bits. All heavy computations are performed in shared memory, minimizing costly global memory accesses.
The experimental platform comprises a Windows 7 32‑bit host with a 4‑core 3.40 GHz Intel CPU and an NVIDIA GeForce GTX 560 (1.6 GHz, 336 CUDA cores, 1 GB device memory). Tests were conducted on packet sizes ranging from 400 bytes to 2000 bytes and error‑tolerance levels t = 2 … 6. Results show that the GPU implementation maintains almost constant execution time regardless of packet size, while the CPU implementation scales linearly with both packet length and error tolerance. As t increases, the packet is split into more, smaller segments; the GPU benefits from higher parallelism, whereas the CPU suffers from increased sequential processing overhead.
Performance figures reveal speed‑ups from 13× (small packets, low t) up to 99× (largest packet, highest t). For example, a 1600‑byte packet with t = 6 is decoded 81 times faster on the GPU than on the CPU. The authors attribute this dramatic gain to (i) coalesced memory accesses after pre‑processing, (ii) overlapped host‑device communication via ADT, and (iii) the efficient use of shared memory and reduction trees that eliminate bank conflicts and thread divergence.
In conclusion, the study demonstrates that a carefully engineered GPU Hamming decoder can meet the stringent latency requirements of modern SDR and high‑speed communication systems. The three optimization techniques—data re‑ordering, asynchronous transfer, and shared‑memory‑centric kernels—are not specific to Hamming codes and can be extended to other forward error correction schemes. Future work may explore scaling to newer GPU architectures (Volta, Ampere), handling multiple code lengths simultaneously, and integrating the decoder into full‑stack SDR platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment