Deep Speech: Scaling up end-to-end speech recognition
We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional systems also tend to perform poorly when used in noisy environments. In contrast, our system does not need hand-designed components to model background noise, reverberation, or speaker variation, but instead directly learns a function that is robust to such effects. We do not need a phoneme dictionary, nor even the concept of a “phoneme.” Key to our approach is a well-optimized RNN training system that uses multiple GPUs, as well as a set of novel data synthesis techniques that allow us to efficiently obtain a large amount of varied data for training. Our system, called Deep Speech, outperforms previously published results on the widely studied Switchboard Hub5'00, achieving 16.0% error on the full test set. Deep Speech also handles challenging noisy environments better than widely used, state-of-the-art commercial speech systems.
💡 Research Summary
The paper introduces Deep Speech, an end‑to‑end speech‑recognition system that replaces the traditional multi‑stage pipeline (feature extraction, acoustic modeling, pronunciation dictionaries, HMM decoding) with a single deep recurrent neural network (RNN). The network takes raw spectrogram frames as input and directly predicts a probability distribution over characters (a‑z, space, apostrophe, blank) at each time step. Its architecture consists of five layers: three non‑recurrent fully‑connected layers that process each time slice with a context window, a bidirectional recurrent layer using clipped ReLU activations (instead of LSTM/GRU for computational simplicity), and a final non‑recurrent layer followed by a softmax output. Training employs Connectionist Temporal Classification (CTC) loss, allowing the model to learn from unaligned transcripts. Optimization uses Nesterov’s accelerated gradient with a momentum of 0.99 and scheduled learning‑rate decay. To curb over‑fitting, dropout (5‑10%) is applied only to feed‑forward layers, and audio jitter (±5 ms shifts) is used as a data‑augmentation technique. During inference, multiple independently trained RNNs are ensembled by averaging their output probabilities.
A large‑scale N‑gram language model, trained on 220 million phrases (≈495 k vocabulary), is integrated at decoding time. The decoding objective combines the log‑probability from the RNN, the log‑probability from the language model, and a length penalty, weighted by hyper‑parameters α and β tuned via cross‑validation. Beam search with a beam width of 1 000–8 000 is employed to find the best character sequence.
Data collection is a central contribution. The authors assembled 5 000 hours of read speech from 9 600 speakers (their own Baidu dataset) and combined it with public corpora (WSJ, Switchboard, Fisher). To improve robustness in noisy environments, they synthetically generated noisy utterances by superimposing clean speech with a wide variety of background noises (including reverberation and Lombard effect) at varying signal‑to‑noise ratios. This synthetic augmentation dramatically expands the effective training set without requiring costly manual labeling of noisy recordings.
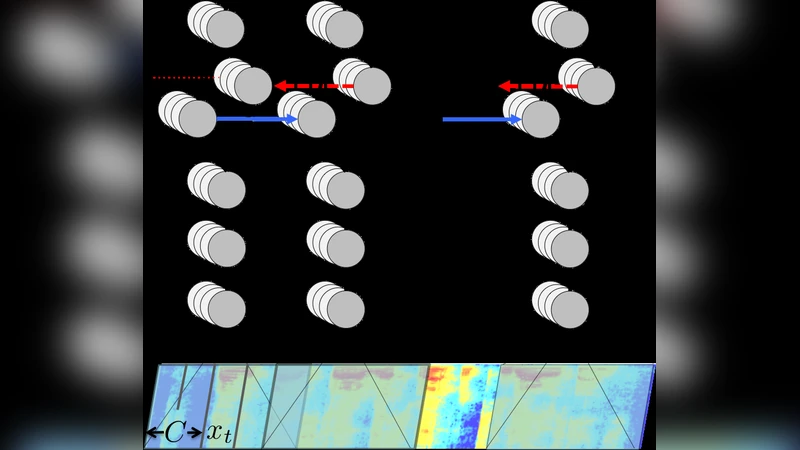
Training efficiency is achieved through two levels of parallelism. Data parallelism distributes mini‑batches across multiple GPUs; each GPU processes thousands of examples simultaneously by stacking them into wide matrices. To handle variable‑length utterances, examples are sorted by length and padded within each batch. Model parallelism addresses the sequential nature of the recurrent layer: the bidirectional recurrent computation is split along the time axis, with the first half of the sequence processed on one GPU (forward pass) and the second half on another GPU (backward pass). At the midpoint the GPUs exchange intermediate activations and swap roles, minimizing inter‑GPU communication. An additional optimization, striding, reduces the number of recurrent steps by a factor of two, effectively halving the computational load.
Experimental results show that Deep Speech achieves a word error rate (WER) of 16.0 % on the full Switchboard Hub5’00 test set, surpassing previously published benchmarks. On a proprietary noisy‑speech test set, the system attains 19.1 % WER, compared to 30.5 % for leading commercial recognizers. These gains are attributed to the massive labeled dataset, effective synthetic noise augmentation, and the highly optimized multi‑GPU training pipeline.
In conclusion, the work demonstrates that with sufficient data and scalable training infrastructure, an end‑to‑end deep learning model can outperform complex traditional speech‑recognition pipelines while being conceptually simpler. The paper paves the way for future research on deeper recurrent or transformer‑based architectures trained under similar large‑scale, parallel conditions, and suggests that further performance improvements are likely as computational resources continue to grow.
Comments & Academic Discussion
Loading comments...
Leave a Comment