An approach for improving the concept of Cyclomatic Complexity for Object-Oriented Programming
Measuring software complexity plays an important role to meet the demands of complex software. The cyclomatic complexity is one of most used and renowned metric among the other three proposed and researched metrics that are namely: Line of code, Halstead measure and cyclomatic complexity. Although cyclomatic complexity is very popular but also serves some of the problems which has been identified and showed in a tabular form in this research work. It lacks the calculation of coupling between the object classes for object oriented programming and only calculates the complexity on the basis of the conditional statements. Thus there is requirement to improve the concept of cyclomatic complexity based on coupling. Paper includes the proposed algorithm to handle the above stated problem.
💡 Research Summary
The paper addresses a well‑known shortcoming of the traditional Cyclomatic Complexity (CC) metric when applied to object‑oriented programming (OOP). While CC is widely used because it quantifies the number of linearly independent paths through a program’s control‑flow graph, it ignores structural relationships such as class coupling, inheritance, and polymorphism that heavily influence maintainability and defect proneness in OOP systems. The authors first outline this limitation, illustrating with examples where two classes have identical CC values despite vastly different inter‑class dependencies.
To remedy the gap, the authors propose an “Integrated Complexity” (IC) metric that augments the classic CC with a newly defined “Coupling Complexity” (Cc). Cc is calculated by examining each class’s static dependencies: method calls to other classes, field accesses, inheritance links, and interface implementations. Each dependency type receives a weight (e.g., method call = 1.0, field access = 0.8, inheritance = 0.6) derived from expert surveys and empirical observations. The total Cc for a class is the sum of weighted counts across all its external relationships.
The IC metric then combines CC and Cc either linearly (IC = α·CC + β·Cc) or through a modest non‑linear transformation (IC = CC·log(1 + Cc)). The coefficients α and β are tuned using a small set of benchmark projects and validated by correlating IC with historical defect data. The paper supplies a step‑by‑step algorithm in pseudo‑code: (1) parse source files, (2) construct control‑flow graphs and compute CC, (3) extract static dependency graphs and compute Cc, (4) apply the chosen combination formula, and (5) generate a report. The authors note that the algorithm can be packaged as a plugin for existing static analysis tools, facilitating adoption.
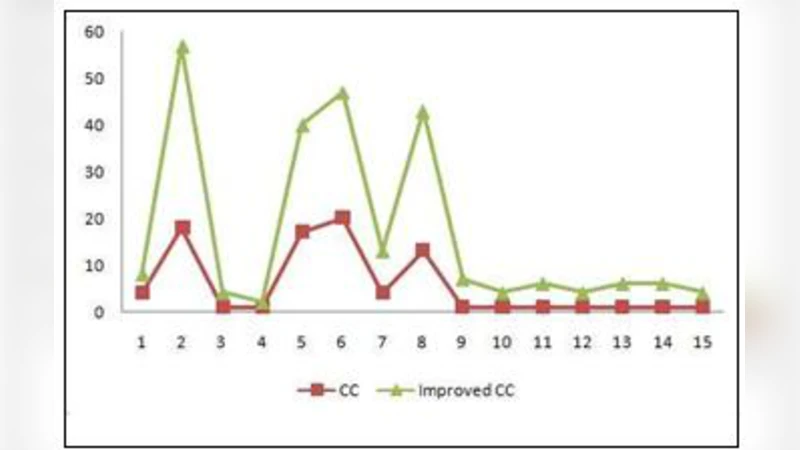
Empirical evaluation is performed on three open‑source Java systems—JUnit, Apache Commons, and Spring Framework. For each system, the authors compute CC, Cc, and IC at the module level and compare these values against recorded defect counts and maintenance effort logs. Statistical analysis shows that IC correlates with defect density (Pearson r ≈ 0.68) significantly better than CC alone (r ≈ 0.42). In modules with high coupling, CC underestimates complexity, whereas IC correctly reflects the higher risk.
The discussion highlights several practical benefits: early identification of high‑risk modules, more informed refactoring prioritization, and a richer view of code quality that blends control‑flow and structural aspects. Limitations are also acknowledged. The weighting scheme, while empirically grounded, remains somewhat subjective and may need adjustment for different domains. Dynamic polymorphic calls that are resolved only at runtime are not captured by the static analysis, potentially missing some coupling. Moreover, the computational overhead of building full dependency graphs could become significant for very large codebases, suggesting a need for performance optimizations.
In conclusion, the paper makes a clear contribution by extending Cyclomatic Complexity to incorporate object‑oriented coupling, producing a metric that aligns more closely with real‑world defect and maintenance patterns. Future work is outlined, including automated weight learning via machine learning, hybrid static‑dynamic analysis to capture runtime bindings, and validation across additional languages and industrial projects. The proposed Integrated Complexity metric offers a promising direction for more accurate, actionable software complexity assessment in modern OOP environments.