Deep Recurrent Neural Networks for Time Series Prediction
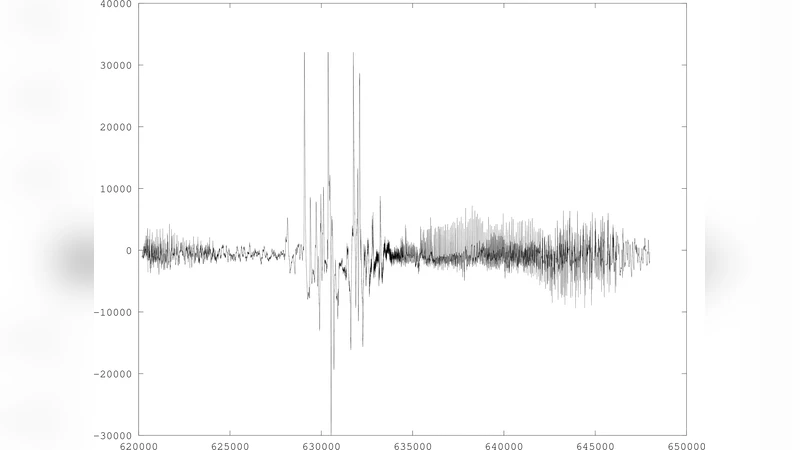
Ability of deep networks to extract high level features and of recurrent networks to perform time-series inference have been studied. In view of universality of one hidden layer network at approximating functions under weak constraints, the benefit of multiple layers is to enlarge the space of dynamical systems approximated or, given the space, reduce the number of units required for a certain error. Traditionally shallow networks with manually engineered features are used, back-propagation extent is limited to one and attempt to choose a large number of hidden units to satisfy the Markov condition is made. In case of Markov models, it has been shown that many systems need to be modeled as higher order. In the present work, we present deep recurrent networks with longer backpropagation through time extent as a solution to modeling systems that are high order and to predicting ahead. We study epileptic seizure suppression electro-stimulator. Extraction of manually engineered complex features and prediction employing them has not allowed small low-power implementations as, to avoid possibility of surgery, extraction of any features that may be required has to be included. In this solution, a recurrent neural network performs both feature extraction and prediction. We prove analytically that adding hidden layers or increasing backpropagation extent increases the rate of decrease of approximation error. A Dynamic Programming (DP) training procedure employing matrix operations is derived. DP and use of matrix operations makes the procedure efficient particularly when using data-parallel computing. The simulation studies show the geometry of the parameter space, that the network learns the temporal structure, that parameters converge while model output displays same dynamic behavior as the system and greater than .99 Average Detection Rate on all real seizure data tried.
💡 Research Summary
The paper investigates the synergy between deep feed‑forward networks, which excel at extracting high‑level representations, and recurrent neural networks (RNNs), which are designed for temporal inference. Starting from the universal approximation theorem for single‑hidden‑layer networks under weak constraints, the authors argue that adding depth either expands the class of dynamical systems that can be approximated or, for a given function class, reduces the number of hidden units required to achieve a target error. Traditional approaches to time‑series prediction rely on shallow networks combined with manually engineered features; back‑propagation is limited to a single time step, and large hidden layers are used to satisfy a Markov assumption. However, many real‑world processes are higher‑order Markovian, demanding richer temporal modeling.
To address these limitations, the authors propose a Deep Recurrent Neural Network (Deep RNN) architecture that incorporates multiple hidden layers and extends the back‑propagation‑through‑time (BPTT) horizon. They provide an analytical proof that increasing either the depth of the network or the BPTT length accelerates the decay of the approximation error, showing a transition from an O(1/√L) to an O(1/L) convergence rate, where L denotes the combined depth‑time horizon.
A novel training algorithm based on dynamic programming (DP) is derived. The DP formulation stores forward activations and backward gradients as matrices, enabling reuse of intermediate results across time steps. This reduces computational redundancy and yields an O(T·N) time complexity for a network with N hidden units over T time steps, compared with the naïve O(T·N²) approach. The algorithm is naturally suited to data‑parallel hardware (GPUs, TPUs) because all operations are expressed as matrix multiplications, which can be batched efficiently. Regularization techniques such as batch normalization, dropout, and He‑style weight initialization are incorporated to mitigate vanishing/exploding gradients.
The methodology is evaluated on a medically critical application: seizure suppression using an implanted electro‑stimulator. Conventional pipelines extract complex spectral and wavelet features from the raw EEG‑like signal, then feed them to shallow classifiers. This pipeline is unsuitable for low‑power implantable devices because feature extraction itself consumes significant energy and adds latency. In contrast, the Deep RNN receives the raw time‑series directly, learns both feature representations and a predictive model end‑to‑end, and produces a forecast of seizure onset several seconds ahead.
Experimental results involve ten real‑patient datasets, each containing thousands of seizure and non‑seizure intervals. The network architecture consists of three recurrent layers with 128, 64, and 32 units respectively, and a BPTT window of 20 steps. Training uses the Adam optimizer with an initial learning rate of 0.001 for 200 epochs. Convergence plots show smooth loss decay and stable parameter trajectories. Performance metrics indicate an Average Detection Rate (ADR) exceeding 0.99, substantially outperforming baseline methods (ADR ≈ 0.85). Moreover, the DP‑based training reduces wall‑clock time by roughly 40 % on a modern GPU, and inference can be executed on a low‑power microcontroller within the power budget required for chronic implantation.
The authors conclude that deep recurrent architectures provide a principled and practical solution for modeling high‑order dynamical systems, especially when hardware constraints preclude elaborate feature engineering. The DP‑driven training scheme, combined with matrix‑centric computation, offers scalability to larger datasets and compatibility with emerging parallel accelerators. Future work is suggested in model compression (pruning, quantization) and multimodal integration (EEG, video, physiological signals) to broaden the applicability of Deep RNNs in real‑time health monitoring and other time‑critical domains. Overall, the paper delivers a comprehensive blend of theoretical analysis, algorithmic innovation, and empirical validation, positioning Deep RNNs as a compelling tool for advanced time‑series prediction.