Representation of Evolutionary Algorithms in FPGA Cluster for Project of Large-Scale Networks
Many problems are related to network projects, such as electric distribution, telecommunication and others. Most of them can be represented by graphs, which manipulate thousands or millions of nodes, becoming almost an impossible task to obtain real-time solutions. Many efficient solutions use Evolutionary Algorithms (EA), where researches show that performance of EAs can be substantially raised by using an appropriate representation, such as the Node-Depth Encoding (NDE). The objective of this work was to partition an implementation on single-FPGA (Field-Programmable Gate Array) based on NDE from 512 nodes to a multi-FPGAs approach, expanding the system to 4096 nodes.
💡 Research Summary
The paper addresses the challenge of solving large‑scale network design problems, specifically the degree‑constrained minimum spanning tree (DC‑MST), which becomes NP‑hard when a degree limit is imposed on each node. Traditional polynomial‑time algorithms such as Prim or Kruskal are ineffective under these constraints, prompting the use of evolutionary algorithms (EAs) that can explore the combinatorial search space heuristically. The authors build on previous work that introduced a hardware accelerator called NDEWG, which implements an EA using the Node‑Depth Encoding (NDE) representation. NDE encodes a spanning tree as a linear list of (node, depth) pairs ordered by a depth‑first traversal, enabling compact storage and fast manipulation. The key genetic operator, Preserve Ancestor Operator (PAO), modifies two parent trees while preserving ancestor relationships and respecting the degree bound, thereby generating feasible offspring without costly feasibility checks.
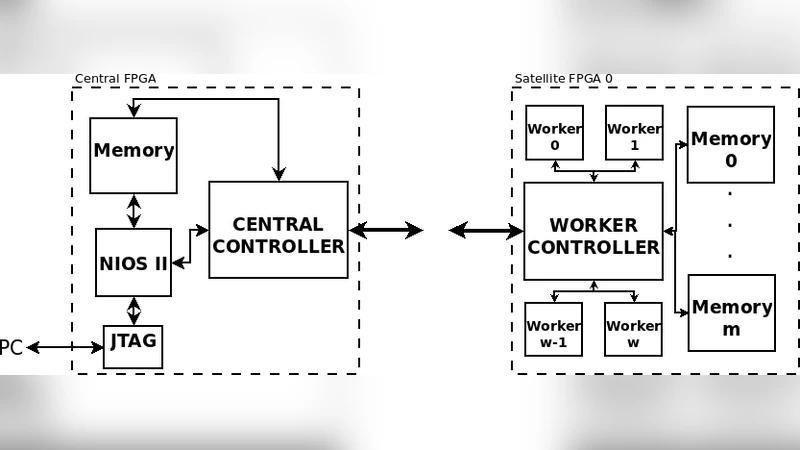
In the original single‑FPGA implementation (Altera Cyclone II and later Stratix IV GX), the system could handle up to 512 nodes (later 1024) but was limited by the 32‑bit system bus width and on‑chip memory capacity. To scale to larger problem instances, the authors propose a multi‑FPGA architecture organized as a star network: one Central FPGA manages the global population of spanning trees and schedules work, while multiple Satellite FPGAs host collections of parallel processing elements called Workers. Each Worker executes the PAO operator independently with different random seeds, evaluates the resulting tree weight, and reports improvements back to the Central node.
Communication between Central and Satellite modules is realized via 10 Gbps Ethernet interfaces using XAUI PHYs. To hide the low‑level protocol details, the authors develop a Network Abstraction System (NAS) that presents Avalon Memory‑Mapped master/slave front‑ends to the FPGA logic and translates transactions into a streaming Avalon bus that feeds the Ethernet MAC. Two Stratix V GX development kits (5SGXEA7) are linked through dual XAUI‑to‑SFP+ HSMC boards and full‑duplex SFP+ optical modules, forming the physical interconnect.
Simulation results (ignoring memory and interconnect delays) show that adding Satellite modules increases logic utilization and slightly reduces maximum clock frequency (from ~174 MHz for a single Satellite to ~123 MHz for eight Satellites), while the average iteration time per EA cycle remains in the sub‑microsecond range (≈0.09–0.14 µs). On actual hardware, the average iteration time rises dramatically to about 85 µs, indicating that the NAS and Ethernet stack dominate the latency. The system successfully processes graphs up to 4096 nodes; attempts to reach 8192 nodes fail due to insufficient on‑chip memory, suggesting that external high‑capacity memory or more efficient memory management would be required for further scaling.
A performance comparison with the earlier NDEWG‑32 (single‑FPGA, 32‑bit bus) and a software baseline (Intel Core 2 Quad Q6600 running a parallel OpenMP C implementation) shows that the FPGA cluster outperforms the CPU for problem sizes up to 1024 nodes. However, the scalability advantage diminishes as network communication overhead becomes the bottleneck, and the monolithic nature of the original design limits resource growth.
The authors conclude that parallelized EAs implemented on FPGA clusters are promising for real‑world NP‑hard network problems such as power‑distribution reconfiguration, which can involve up to 100 000 nodes. Nonetheless, significant work remains to improve the multi‑FPGA approach: the NAS must be streamlined to reduce latency, higher‑bandwidth or lower‑overhead interconnects should be explored, and memory constraints need to be addressed, possibly through external DRAM or on‑chip memory compression techniques. Future research will focus on these optimizations to enable truly large‑scale, real‑time network optimization on reconfigurable hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment