Learning unbiased features
A key element in transfer learning is representation learning; if representations can be developed that expose the relevant factors underlying the data, then new tasks and domains can be learned readily based on mappings of these salient factors. We propose that an important aim for these representations are to be unbiased. Different forms of representation learning can be derived from alternative definitions of unwanted bias, e.g., bias to particular tasks, domains, or irrelevant underlying data dimensions. One very useful approach to estimating the amount of bias in a representation comes from maximum mean discrepancy (MMD) [5], a measure of distance between probability distributions. We are not the first to suggest that MMD can be a useful criterion in developing representations that apply across multiple domains or tasks [1]. However, in this paper we describe a number of novel applications of this criterion that we have devised, all based on the idea of developing unbiased representations. These formulations include: a standard domain adaptation framework; a method of learning invariant representations; an approach based on noise-insensitive autoencoders; and a novel form of generative model.
💡 Research Summary
The paper “Learning unbiased features” proposes a unified framework for obtaining representations that are unbiased with respect to tasks, domains, or irrelevant data variations. The authors argue that traditional representation learning often over‑fits to specific biases (e.g., a particular domain or transformation) and that a more generalizable representation should minimize such biases. To quantify bias, they adopt the Maximum Mean Discrepancy (MMD), a kernel‑based two‑sample statistic that measures the distance between probability distributions. When the kernel induces a universal reproducing kernel Hilbert space, MMD equals zero if and only if the two distributions are identical, making it a natural penalty for aligning feature distributions across different conditions.
Four distinct applications of the MMD‑based penalty are explored:
-
Domain Adaptation – Using the Amazon product‑review sentiment dataset (four domains: books, DVD, electronics, kitchen), the authors train a two‑hidden‑layer neural network with an MMD penalty applied to a hidden layer to align source and target feature distributions. Compared against linear and RBF SVMs, Transfer Component Analysis (TCA), and a neural net without MMD, the MMD‑augmented model (NN MMD) consistently achieves higher target accuracies, even when using simple word‑count features instead of TF‑IDF. This demonstrates that MMD can effectively reduce domain‑specific bias while learning both features and classifier jointly.
-
Learning Invariant Features – The task is face identity recognition under varying illumination. Using the Extended Yale‑B dataset, five lighting conditions are treated as separate domains. The authors minimize the sum of MMD between each domain’s hidden representations and the overall average distribution. A Gaussian kernel MMD applied to the second hidden layer raises test accuracy from 72 % (no MMD) to about 82 %, and PCA visualizations show that images of the same person cluster together despite lighting changes. This result confirms that MMD can enforce invariance to complex physical transformations without explicit modeling (e.g., Lambertian reflectance).
-
Noise‑Insensitive Autoencoders – Standard autoencoders, denoising autoencoders (DAE), and contractive autoencoders (CAE) are compared on MNIST. The authors add an MMD penalty on the latent layer, sampling perturbed hidden units at each update. They evaluate invariance by training an SVM to distinguish clean from noisy test representations; lower classification accuracy indicates more noise‑invariant features. The MMD‑augmented autoencoder achieves the lowest accuracy (≈73 %), outperforming DAE (≈82 %) and CAE (≈78 %). Surprisingly, DAE performs worst, highlighting that reconstruction‑based denoising does not guarantee distributional invariance.
-
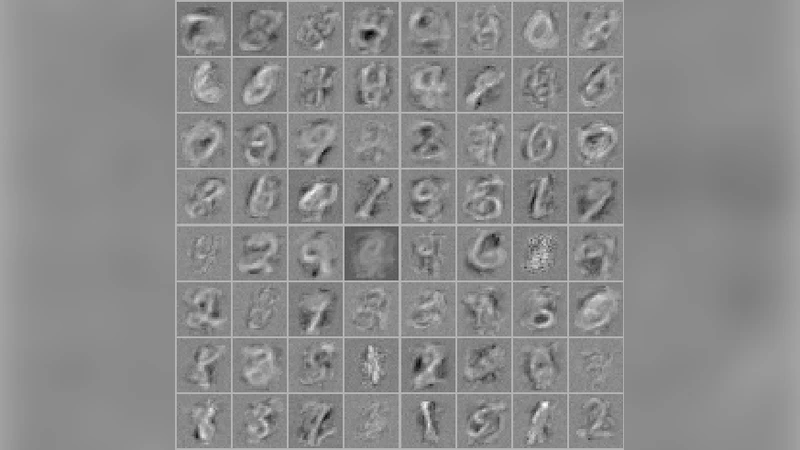
Generative Deep Models – Instead of the adversarial minimax objective used in GANs, the authors directly minimize MMD between real data samples and samples generated by a stochastic deep model (a top‑layer latent variable with a fixed prior passed through a deterministic decoder). Training on 1,000 MNIST digits, the model learns meaningful filters and produces realistic digit samples, demonstrating that a single, well‑behaved objective can replace the unstable adversarial game.
Across all experiments, the MMD penalty consistently reduces unwanted bias, improves transfer performance, and yields representations that are more robust to domain shifts, illumination changes, and noise. The paper’s strengths include a clear theoretical justification for using MMD, a versatile implementation that works for both supervised and unsupervised settings, and thorough empirical validation on diverse tasks. Limitations involve the O(N²) computational cost of exact MMD, sensitivity to kernel choice and bandwidth, and the need for careful hyper‑parameter tuning. Future directions suggested include scalable approximations of MMD (e.g., random Fourier features), multi‑bias simultaneous minimization, and extending the framework to fully unsupervised domain discovery.
In summary, the work establishes MMD as a powerful, unifying tool for learning unbiased representations, offering a practical alternative to adversarial or reconstruction‑based methods and opening avenues for more robust transfer learning across heterogeneous data environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment