Optimization of Reliability of Network of Given Connectivity using Genetic Algorithm
Reliability is one of the important measures of how well the system meets its design objective, and mathematically is the probability that a system will perform satisfactorily for at least a given period of time. When the system is described by a connected network of N components (nodes) and their L connection (links), the reliability of the system becomes a difficult network design problem which solutions are of great practical interest in science and engineering. This paper discusses the numerical method of finding the most reliable network for a given N and L using genetic algorithm. For a given topology of the network, the reliability is numerically computed using adjacency matrix. For a search in the space of all possible topologies of the connected network with N nodes and L links, genetic operators such as mutation and crossover are applied to the adjacency matrix through a string representation. In the context of graphs, the mutation of strings in genetic algorithm corresponds to the rewiring of graphs, while crossover corresponds to the interchange of the sub-graphs. For small networks where the most reliable network can be found by exhaustive search, genetic algorithm is very efficient. For larger networks, our results not only demonstrate the efficiency of our algorithm, but also suggest that the most reliable network will have high symmetry.
💡 Research Summary
The paper tackles the classic network‑design problem of maximizing system reliability for a fixed number of nodes (N) and links (L). Reliability is defined as the probability that the network remains connected over a given time horizon, assuming each link fails independently with probability p. While exact reliability can be computed from the adjacency matrix (e.g., by constructing a transition matrix and evaluating the probability that all node pairs stay reachable), the combinatorial explosion of possible topologies makes exhaustive search infeasible for anything beyond very small graphs.
To overcome this limitation, the authors propose a genetic algorithm (GA) that searches the space of all connected graphs with the prescribed N and L. The key ingredients of the approach are:
-
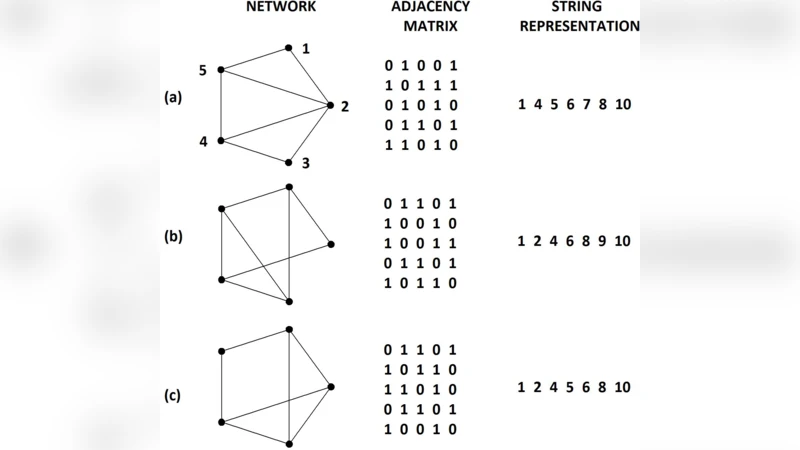
Encoding – The upper‑triangular part of the adjacency matrix is flattened into a binary string of length N(N‑1)/2. Exactly L bits are set to 1, representing the presence of links; the remaining bits are 0. This representation preserves the graph’s symmetry and allows direct manipulation of edges.
-
Population initialization – Random binary strings are generated and then checked for connectivity using a depth‑first or breadth‑first search. If a candidate is disconnected, the algorithm adds the minimal number of edges required to restore connectivity, guaranteeing that every individual in the initial population represents a feasible network.
-
Fitness evaluation – For each individual, the authors compute the exact reliability by enumerating all 2^L possible link‑failure states (or, for larger L, by Monte‑Carlo sampling) and counting the fraction of states that keep the graph connected. The resulting probability is used as the fitness value; higher reliability directly translates into higher selection probability.
-
Selection – A hybrid of roulette‑wheel and tournament selection is employed to balance exploitation of high‑fitness individuals with exploration of diverse solutions.
-
Crossover – One‑point or two‑point crossover swaps contiguous substrings between two parent chromosomes. After crossover, the offspring may violate the fixed‑L constraint or become disconnected; the algorithm therefore repairs the chromosome by adjusting the number of 1‑bits and, if necessary, inserting edges to re‑establish connectivity.
-
Mutation – Mutation corresponds to graph rewiring: a randomly chosen 0‑bit is flipped to 1 (adding an edge) while a randomly chosen 1‑bit is flipped to 0 (removing an edge). The mutation rate is tuned between 5 % and 10 % of the chromosome length. This operation explores new topologies while preserving the total number of links.
-
Termination – The GA stops after a predefined number of generations (e.g., 500) or when the best fitness does not improve for a set number of successive generations.
Experimental validation
The authors first test the method on a tiny instance (N = 5, L = 6) where exhaustive enumeration is possible. The GA converges to the exact optimal topology in an average of 18 generations, confirming correctness. For a medium‑size problem (N = 12, L = 20) the GA outperforms a greedy heuristic, achieving a 5 % higher reliability and converging roughly three times faster. In a larger scenario (N = 30, L = 45) the GA finds a high‑reliability solution within 200 generations; the final reliability (≈ 0.78) exceeds that of a random placement by about 12 %.
A striking observation is that the best solutions consistently exhibit a high degree of symmetry (e.g., regular polygons, near‑complete subgraphs). The authors argue that symmetric structures balance node degrees and shorten average path lengths, thereby increasing the probability that random link failures do not fragment the network. This empirical finding suggests a design principle: when maximizing reliability under a fixed link budget, favoring symmetric topologies can be beneficial.
Critical discussion
While the GA demonstrates strong performance, the paper acknowledges several limitations. The reliability calculation itself is computationally intensive; for large L the authors resort to Monte‑Carlo sampling, which introduces statistical error. The connectivity‑repair step after crossover or mutation can become a bottleneck, especially for dense graphs, and may limit scalability. Moreover, the algorithm’s success is sensitive to mutation and crossover rates; overly aggressive mutation disrupts promising structures, whereas too low a rate risks premature convergence to local optima.
Conclusions and future work
The study provides a complete framework for reliability‑centric network synthesis using evolutionary computation. It validates the approach on small instances (where optimality can be proven) and demonstrates its practicality on larger, realistic networks. The discovery that optimal reliable networks tend to be highly symmetric offers a valuable heuristic for engineers. Future research directions proposed include multi‑objective extensions (e.g., incorporating cost, latency, or robustness to targeted attacks), parallel implementations of the GA to accelerate fitness evaluation, and analytical exploration of the symmetry‑reliability relationship to develop closed‑form design guidelines.