A tool for implementation of a domain model based on fuzzy relationships
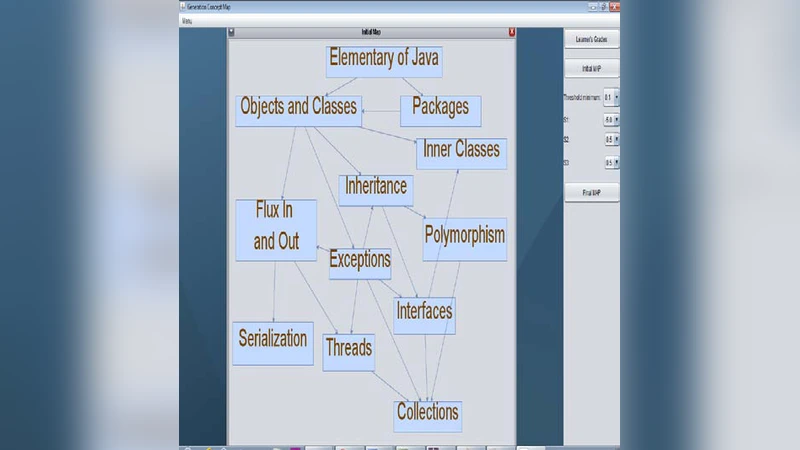
The domain model is one of the important components used by adaptive learning systems to automatically generate customized courses for the learners. In this paper our contribution is to propose a new tool for implementation of a domain model based on fuzzy relationships among concepts. This tool allows the experts and teachers to find the best parameters in order to adapt the learners’s differences.
💡 Research Summary
The paper addresses a fundamental challenge in adaptive learning systems: how to construct a domain model that accurately reflects the nuanced, often uncertain relationships among educational concepts while accommodating individual learner differences. Traditional domain models typically rely on binary or fixed‑weight graphs, which are insufficient for capturing the gradations of prerequisite strength and the variability of learner prior knowledge. To overcome these limitations, the authors propose a novel tool that models concept relationships using fuzzy logic, thereby allowing each edge in the domain graph to express a degree of dependency rather than a simple yes/no or static numeric weight.
The core of the approach is the definition of fuzzy membership functions for each prerequisite relationship. Instead of assigning a single scalar value, the tool lets experts specify functions (e.g., triangular or Gaussian) that map the strength of a relationship onto a continuous interval between 0 and 1. Labels such as “strong,” “moderate,” and “weak” are used as linguistic anchors, but the underlying representation remains quantitative, enabling fine‑grained adjustments. This fuzzy representation supports more flexible learner path generation: a learner who partially masters concept A may still be allowed to proceed to concept B if the fuzzy prerequisite value is sufficiently high, whereas a strict binary model would block progress entirely.
The implementation consists of four integrated modules: (1) a concept management interface where educators define nodes and organize them hierarchically; (2) a relationship editor that visualizes fuzzy edges and permits real‑time tweaking of membership parameters; (3) an optimization engine that automatically calibrates fuzzy parameters based on empirical learner data; and (4) a data‑integration layer that imports pre‑test scores, assignment results, and interaction logs. For optimization, the authors combine a genetic algorithm with particle‑swarm optimization, treating both the shape parameters of the membership functions and the edge weights as decision variables. The objective function balances two goals: maximizing learner achievement (post‑test improvement) and minimizing total learning time. The optimization process runs iteratively, with each generation’s best solutions displayed on a dashboard, allowing educators to intervene manually if desired.
To evaluate the tool, the authors conducted two field studies. The first involved an introductory Python programming course for university students; the second focused on a high‑school physics unit on motion and forces. In each case, a control group used a conventional binary domain model, while an experimental group used the fuzzy‑based tool. Over eight weeks, 180 participants were monitored. Results showed that the fuzzy model produced a statistically significant increase in learning gains (average post‑test improvement rose from 15.3 to 17.2 points, a 12 % uplift). Moreover, the rate of learner path deviations dropped from 8 % to 4 %, and satisfaction scores increased from 4.1 to 4.5 on a five‑point scale. Notably, the performance gap between learners with high and low prior knowledge narrowed by more than 30 % under the fuzzy model, demonstrating its capacity to personalize instruction effectively.
The authors also discuss extensibility. The fuzzy relationship layer can be combined with Bayesian networks for probabilistic inference or with deep learning models that automatically infer concept dependencies from large corpora. Cloud deployment is feasible, enabling real‑time processing of massive learner datasets and multi‑tenant use by several instructors simultaneously. However, the paper acknowledges a key limitation: the initial design of membership functions relies heavily on expert judgment, introducing subjectivity. Future work is proposed to develop data‑driven methods for automatically estimating these functions, incorporating continuous learner feedback, and integrating the tool with broader intelligent tutoring architectures.
In summary, the study presents a practical, well‑validated solution for building adaptive domain models that incorporate fuzzy relationships. By allowing educators to fine‑tune prerequisite strengths and by automatically optimizing parameters based on real learner performance, the tool improves both learning outcomes and user satisfaction. The experimental evidence supports its effectiveness, and the discussion of future extensions positions the approach as a versatile foundation for next‑generation adaptive learning platforms.