IPMACC: Open Source OpenACC to CUDA/OpenCL Translator
In this paper we introduce IPMACC, a framework for translating OpenACC applications to CUDA or OpenCL. IPMACC is composed of set of translators translating OpenACC for C applications to CUDA or OpenCL. The framework uses the system compiler (e.g. nvcc) for generating final accelerator’s binary. The framework can be used for extending the OpenACC API, executing OpenACC applications, or obtaining CUDA or OpenCL code which is equivalent to OpenACC code. We verify correctness of our framework under several benchmarks included from Rodinia Benchmark Suit and CUDA SDK. We also compare the performance of CUDA version of the benchmarks to OpenACC version which is compiled by our framework. By comparing CUDA and OpenACC versions, we discuss the limitations of OpenACC in achieving a performance near to highly-optimized CUDA version.
💡 Research Summary
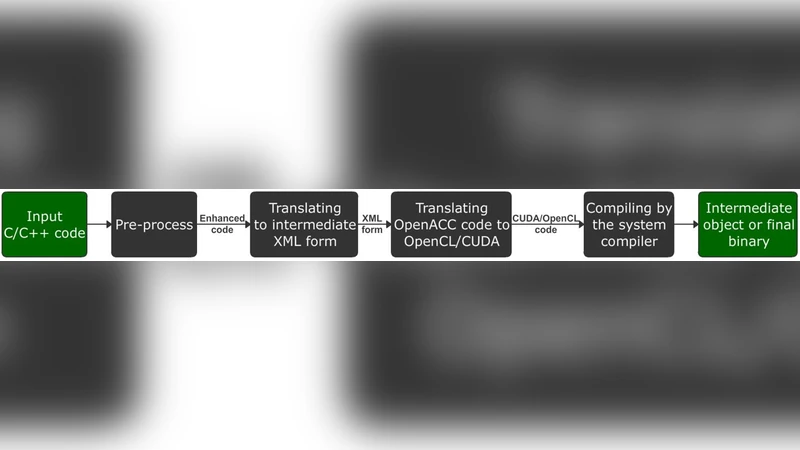
The paper presents IPMACC, an open‑source framework that translates C/C++ programs annotated with OpenACC directives into CUDA or OpenCL source code and ultimately into executable binaries. The motivation stems from the limited support and optimization capabilities of existing OpenACC compilers, especially when targeting heterogeneous GPUs. IPMACC’s compilation flow consists of four major stages.
Stage 1 – Pre‑processing normalizes the input source using uncrustify and validates OpenACC pragma syntax with custom scanners, ensuring that control structures are fully bracketed and that nested directives obey the OpenACC specification.
Stage 2 – Intermediate XML Generation converts the normalized source into an XML representation containing only three tag types: raw C code, OpenACC pragmas, and for‑loops. This representation cleanly separates host code from accelerator‑related regions, simplifying subsequent transformations.
Stage 3 – Target Code Generation is the core of the framework and proceeds through nine sequential sub‑steps. First, OpenACC regions are replaced by dummy function calls while preserving the original host code. The abstract syntax tree (AST) of the host code is then built to retrieve type information, array sizes, and declarations of user‑defined functions needed inside accelerator regions. Scope analysis identifies the declarations required for each region. Kernel bodies are constructed by mapping OpenACC parallelism levels (gang, worker, vector, thread) to CUDA concepts (kernel, thread‑block, warp, thread). Data‑management pragmas are translated into explicit memory allocation, copy‑in/out, and pointer exchange calls. Reduction clauses are implemented using a known algorithm for multi‑block aggregation. Finally, dummy calls are replaced with concrete kernel launch code, forward declarations are added, and the transformed source is written to disk with an appropriate suffix (e.g., .cu).
Stage 4 – Final Object/Binary Generation invokes the system compiler (nvcc for CUDA, g++ for OpenCL) to produce the final binary, controlled by IPMACC’s command‑line flags.
The authors validate correctness using a subset of benchmarks from the NVIDIA CUDA SDK and the Rodinia suite, covering applications such as Back‑Propagation, BFS, Dyadic Convolution, Hotspot, Matrix Multiplication, N‑Body, Needleman‑Wunsch, Path‑Finder, and SRAD. Each benchmark is compiled in three forms: a serial C version, a hand‑optimized CUDA version, and an OpenACC version generated by IPMACC. Execution times are measured with NVIDIA’s nvprof, reporting memory transfer, kernel execution, and kernel launch overhead separately; each measurement is the harmonic mean of 30 runs.
Performance results show that, while memory transfer times are comparable between OpenACC and CUDA, the OpenACC versions generally suffer from longer kernel launch and execution times. For example, the CUDA implementation of Back‑Propagation interleaves CPU and GPU work, reducing overall launch overhead, whereas the OpenACC version keeps all stages on the GPU, incurring higher launch costs but lower transfer costs. BFS exhibits slower execution in OpenACC due to a global boolean reduction that forces serialization, whereas the CUDA version avoids this by initializing the flag on the host and using divergent control flow to protect writes. In some cases (e.g., the “Nearest” kernel) execution times are similar, indicating that the OpenACC translation can be efficient when the algorithm maps naturally to the GPU.
The paper concludes that IPMACC successfully automates the translation of OpenACC programs to CUDA/OpenCL, providing a useful tool for developers who wish to prototype on OpenACC and later obtain low‑level GPU code. However, limitations remain: the current implementation handles only fixed‑size arrays and static memory allocations, does not automatically exploit shared memory or warp‑level primitives, and may generate sub‑optimal thread‑block configurations. Consequently, for performance‑critical applications, manual CUDA tuning is still required. The framework’s modular design, however, allows future extensions to incorporate more sophisticated optimizations and support for dynamic memory patterns.
Comments & Academic Discussion
Loading comments...
Leave a Comment