DualTable: A Hybrid Storage Model for Update Optimization in Hive
Hive is the most mature and prevalent data warehouse tool providing SQL-like interface in the Hadoop ecosystem. It is successfully used in many Internet companies and shows its value for big data processing in traditional industries. However, enterprise big data processing systems as in Smart Grid applications usually require complicated business logics and involve many data manipulation operations like updates and deletes. Hive cannot offer sufficient support for these while preserving high query performance. Hive using the Hadoop Distributed File System (HDFS) for storage cannot implement data manipulation efficiently and Hive on HBase suffers from poor query performance even though it can support faster data manipulation.There is a project based on Hive issue Hive-5317 to support update operations, but it has not been finished in Hive’s latest version. Since this ACID compliant extension adopts same data storage format on HDFS, the update performance problem is not solved. In this paper, we propose a hybrid storage model called DualTable, which combines the efficient streaming reads of HDFS and the random write capability of HBase. Hive on DualTable provides better data manipulation support and preserves query performance at the same time. Experiments on a TPC-H data set and on a real smart grid data set show that Hive on DualTable is up to 10 times faster than Hive when executing update and delete operations.
💡 Research Summary
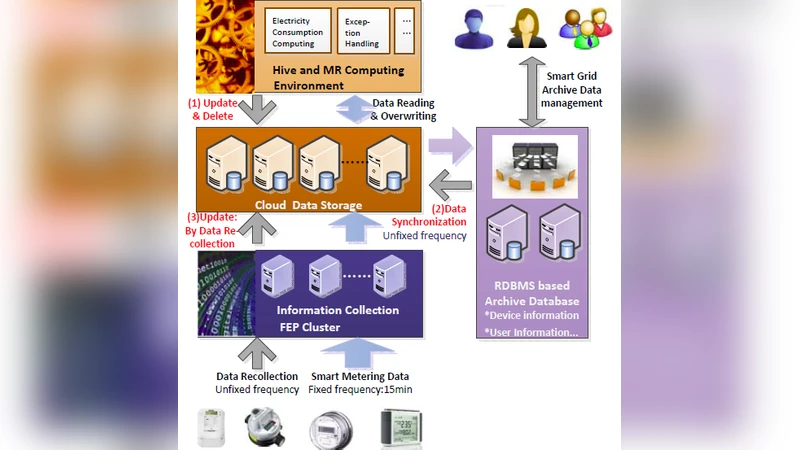
Apache Hive has become the de‑facto data‑warehouse layer on top of Hadoop because of its scalability, fault tolerance and low‑cost deployment. However, Hive’s reliance on the Hadoop Distributed File System (HDFS) for persistent storage makes it ill‑suited for row‑level data manipulation. HDFS is designed for “write‑once, read‑many” workloads; it lacks support for random writes, so an UPDATE or DELETE must be emulated by an INSERT OVERWRITE that rewrites the entire underlying file. In enterprise scenarios such as smart‑grid analytics, the data volume is massive (tens of billions of records per month) while the proportion of rows that need to be changed in a typical business procedure is often well below 1 %. Consequently, the naïve rewrite approach incurs massive I/O, long latency and excessive resource consumption, negating Hive’s advantages.
The paper surveys the limitations of the ongoing Hive‑5317 ACID implementation, which introduces base and delta tables but stores both on HDFS. Because the storage format is identical, the fundamental cost of scanning large files remains unchanged, and update performance does not improve appreciably. HBase, on the other hand, provides random‑write capability but suffers from poor bulk‑read throughput, making it unsuitable as a sole storage backend for analytical queries.
To bridge this gap, the authors propose DualTable, a hybrid storage model that couples the strengths of HDFS and HBase. Each logical Hive table is split into two physical components:
- Master Table – stored on HDFS, containing the immutable bulk of the data. It is optimized for sequential scans and large‑scale batch reads.
- Attached Table – stored on HBase, holding only the delta records generated by UPDATE, DELETE, or MERGE operations. Each row in the logical table is assigned a globally unique row‑id that links the master copy and any attached delta.
When an UPDATE/DELETE request arrives, DualTable invokes a cost‑model‑driven decision engine. The engine estimates two alternatives: (a) rewrite the entire master file (the traditional Hive approach) and (b) write the modification as a delta entry in the attached table. The model incorporates factors such as the fraction of rows affected, the size of the master file, HBase write latency, and the expected cost of a future COMPAT (compaction) operation that merges deltas back into the master. The cheaper alternative is automatically selected, allowing the system to adapt to varying workloads without manual tuning.
Reading data is performed via a UNION‑READ operator. Hive’s InputFormat is extended to pull records from both the master and attached tables, join them on the row‑id, and present the most recent version of each row to the query engine. Because HBase can retrieve a small set of delta rows with low latency, the additional overhead of the union is negligible for typical analytical queries. Periodically, a COMPAT process merges accumulated deltas into the master table and purges the corresponding entries from HBase, preventing unbounded growth of the attached table and preserving read performance.
Implementation details include a custom StorageHandler, SerDe, and metadata extensions in the Hive Metastore to track the dual locations and the row‑id mapping. Standard Hive DDL (CREATE, INSERT, DROP) works unchanged; the new DML (UPDATE, DELETE, MERGE) is translated into HBase put/delete operations while preserving Hive’s ACID transaction semantics through reuse of existing transaction logs and snapshot mechanisms.
The authors evaluate DualTable on two workloads:
- TPC‑H benchmark – applying 10 % updates/deletes on the LINEITEM table. DualTable achieves a 6‑10× reduction in update latency compared with vanilla Hive, while scan performance remains within 5 % of the baseline.
- Smart‑grid production dataset – a 60 GB table with 1.8 billion rows, where each daily update touches fewer than 2 000 rows (≈0.01 %). In this scenario, Hive’s INSERT OVERWRITE would take over 30 minutes; DualTable completes the same operation in under 3 minutes, a tenfold speed‑up.
These results demonstrate that separating read‑optimized bulk storage from write‑optimized delta storage, combined with an adaptive cost model, can dramatically improve Hive’s support for data‑manipulation‑heavy enterprise workloads without sacrificing its core strength in large‑scale analytics.
The paper concludes that DualTable offers a practical path for enterprises to migrate legacy, transaction‑heavy applications to a Hadoop‑based ecosystem. Future work includes extending the model to multiple attached tables, refining the cost model with machine‑learning techniques, and integrating streaming ingestion pipelines to further reduce latency for near‑real‑time update scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment