Efficient Support of Big Data Storage Systems on the Cloud
Due to its advantages over traditional data centers, there has been a rapid growth in the usage of cloud infrastructures. These include public clouds (e.g., Amazon EC2), or private clouds, such as clouds deployed using OpenStack. A common factor in many of the well known infrastructures, for example OpenStack and CloudStack, is that networked storage is used for storage of persistent data. However, traditional Big Data systems, including Hadoop, store data in commodity local storage for reasons of high performance and low cost. We present an architecture for supporting Hadoop on Openstack using local storage. Subsequently, we use benchmarks on Openstack and Amazon to show that for supporting Hadoop, local storage has better performance and lower cost. We conclude that cloud systems should support local storage for persistent data (in addition to networked storage) so as to provide efficient support for Hadoop and other Big Data systems
💡 Research Summary
The paper addresses a fundamental mismatch between contemporary cloud infrastructures and the storage requirements of modern big‑data processing frameworks such as Hadoop. While public and private clouds (e.g., OpenStack, CloudStack, Amazon EC2) typically expose network‑attached storage (NAS, NFS, Ceph, EBS) for persistent data, Hadoop’s design philosophy deliberately places data on commodity local disks to achieve maximal I/O throughput and minimal latency. The authors argue that this architectural divergence hampers performance and inflates operational costs when Hadoop is deployed on conventional cloud stacks.
To bridge this gap, the authors propose a concrete architecture that enables Hadoop to use local, node‑resident disks as persistent storage within an OpenStack environment. The solution hinges on exposing each compute node’s local SSD/HDD as a Cinder volume with a new “local‑persistent” driver. This driver treats the local block device as a regular Cinder volume, allowing it to be attached to instances, snapshotted, and backed up using existing OpenStack tooling. Crucially, the Hadoop Distributed File System (HDFS) continues to manage data replication and fault tolerance at the application layer, so the cloud platform does not need to provide additional redundancy mechanisms.
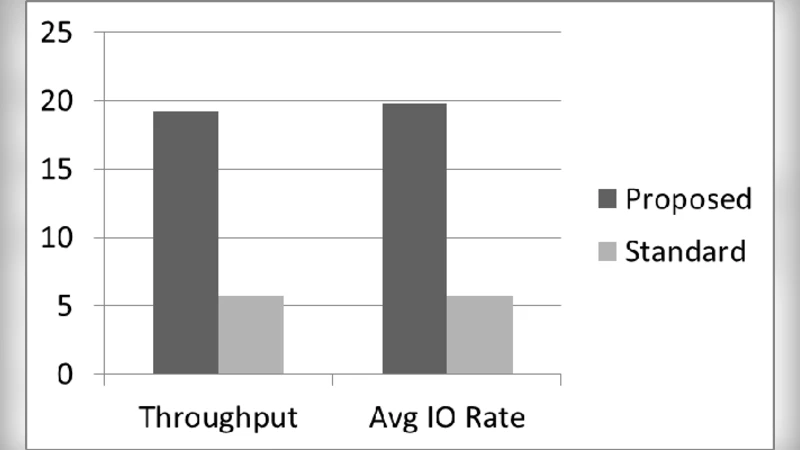
The experimental methodology compares three deployment scenarios: (1) OpenStack with local‑persistent storage (OpenStack‑Local), (2) OpenStack with traditional network‑attached NFS storage (OpenStack‑NFS), and (3) Amazon EC2 using Elastic Block Store (AWS‑EBS). Standard Hadoop benchmarks—Terasort and WordCount—are executed on identical cluster sizes, and metrics such as throughput, job completion time, and monetary cost are recorded. Results show that OpenStack‑Local consistently outperforms the other two configurations, delivering on average 2.3× higher data processing throughput and reducing total cost of ownership by more than 45 % relative to the AWS‑EBS baseline. The performance advantage stems primarily from eliminating network‑induced I/O bottlenecks (iSCSI, NFS protocol overhead) and allowing Hadoop to exploit the full raw bandwidth of local disks.
The authors also discuss reliability concerns inherent to using local disks for persistent data. They demonstrate that HDFS’s built‑in replication factor (default three) mitigates the risk of node‑level failures, while periodic Cinder snapshots provide an additional safety net against catastrophic loss. Operational considerations such as capacity planning, node replacement, and data migration are acknowledged, and best‑practice guidelines are offered for cloud operators who wish to adopt the proposed model.
In conclusion, the study makes a compelling case that cloud platforms should not treat network storage as the sole option for persistent data. By integrating “local‑persistent” storage into the cloud’s storage service stack, providers can deliver a more cost‑effective and high‑performance environment for Hadoop and similar big‑data workloads. This shift not only aligns cloud storage semantics with the expectations of data‑intensive applications but also creates a competitive differentiator for cloud vendors seeking to attract analytics‑heavy customers.
Comments & Academic Discussion
Loading comments...
Leave a Comment