Linking GloVe with word2vec
The Global Vectors for word representation (GloVe), introduced by Jeffrey Pennington et al. is reported to be an efficient and effective method for learning vector representations of words. State-of-the-art performance is also provided by skip-gram w…
Authors: Tianze Shi, Zhiyuan Liu
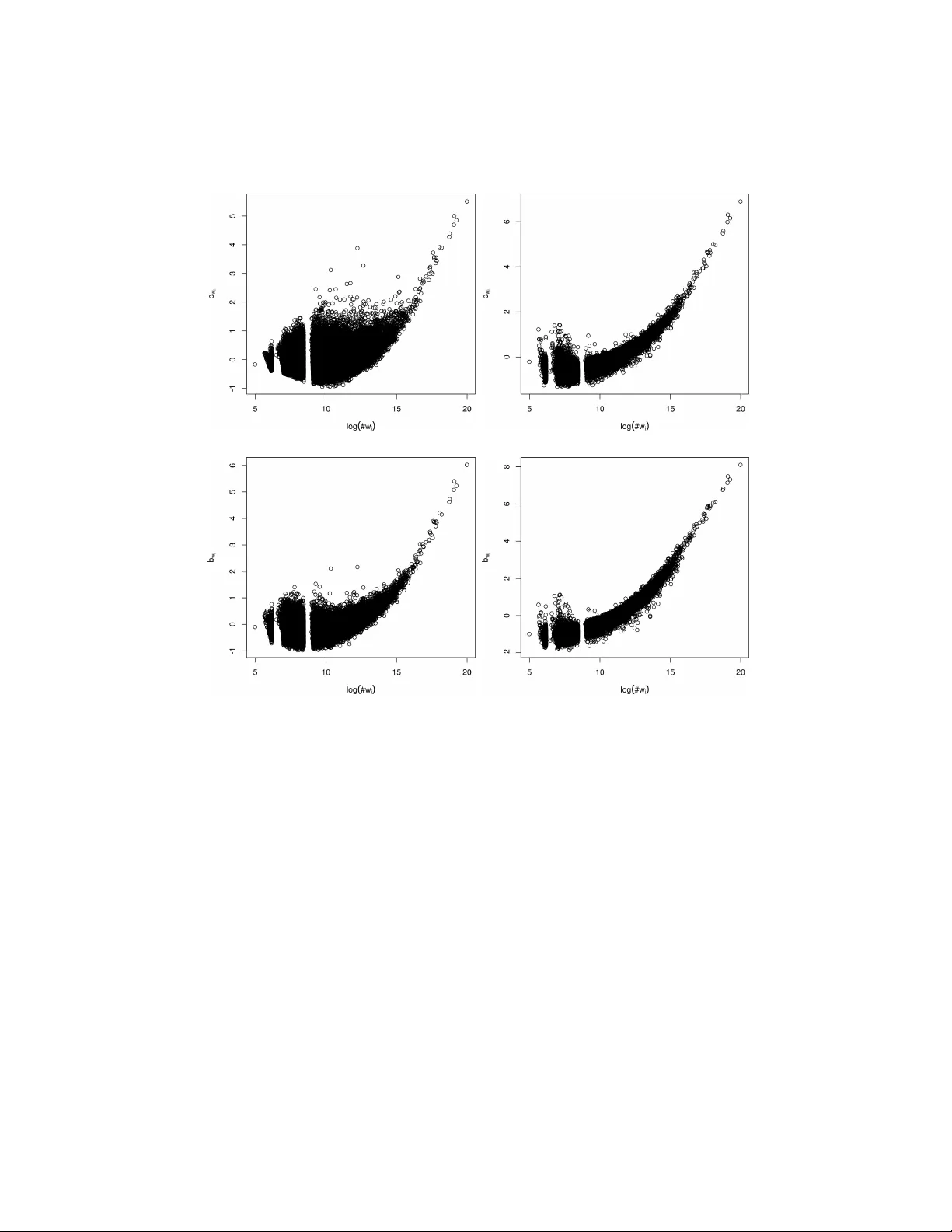
Linking GloV e with word2vec Tianze Shi and Zhiyuan Liu stz11@mails.tsinghua.edu.cn, liuzy@tsinghua.edu.cn No v em b er 20, 2014 The Global V ectors for w ord representation (GloV e), in troduced by Jeffrey P ennington et al. [3] 1 is reported to b e an efficien t and effectiv e metho d for learning v ector representations of words. State-of-the-art performance is also pro vided by skip-gram with negativ e-sampling (SGNS) [2] implemented in the word2vec to ol 2 . In this note, w e explain the similarities betw een the training ob jectives of the t wo models, and show that the ob jectiv e of SGNS is similar to the ob jectiv e of a sp ecialized form of GloV e, though their cost functions are defined differen tly . 1 In tro duction and Notation By representing w ords as vectors, similarities b et w een words and other v aluable features can b e calculated directly with v ector arithmetics. The goal of word em b edding algorithms is to find v ectors for the w ords and their con texts in the corpus to meet some pre-defined criterion (e.g. to predict the surrounding con text of a giv en word), where the con texts are often defined as the w ords surrounding a giv en word. Let the word and context v o cabularies b e V W and V C resp ectiv ely . F or each w ord w ∈ V W and eac h con text c ∈ V C , the goal is to find a vector ~ w ∈ R d and ~ c ∈ R d , where d denotes the vector dimension. Em beddings of all words in the v o cabulary can b e combined into a k V W k × d matrix W , with the i th row W i b eing the embedding of the i th word in the vocabulary . Similarly , a k V C k × d matrix C gathers all the em b eddings of the contexts, with C j represen ting the em b edding of the j th con text. W ord-con text pairs are denoted as ( w, c ), and #( w, c ) coun ts all observ ations of ( w , c ) from the corpus. W e use #( w ) = Σ c #( w , c ) and #( c ) = Σ w #( w , c ) to refer to the count of o ccurrences of a word (context) in all word-con text pairs. Either Σ c #( c ) or Σ w #( w ) ma y represen t the count of all word-con text pairs. 1 http://nlp.stanford.edu/projects/glove/ 2 https://code.google.com/p/word2vec/ 1 2 T raining Ob jectiv es of the Tw o Mo dels 2.1 GloV e GloV e explicitly factorizes the w ord-context co-o ccurrence matrix. The follow- ing equation giv es the lo cal cost function of GloV e mo del. l G ( w i , c j ) = f (# ( w i , c j )) W i · C T j + b W i + b C j − log # ( w i , c j ) 2 , (1) where b W i and b C j are the unknown bias terms only relev an t to the words and con texts respectively . f ( x ) is a weigh ting function whic h down-w eigh ts rare co-o ccurrences. The function chosen by Pennington et al. is f ( x ) = ( ( x/x max ) α x < x max 1 otherwise (2) The cost function is minimized by optimizing W i · C T j to log # ( w i , c j ) − b W i − b C j , an ideal solution to whic h is given by W i · C T j = log # ( w i , c j ) − b W i − b C j (3) for eac h row in W and C . 2.2 Skip-gram with Negativ e Sampling (SGNS) As shown by Levy and Goldb erg [1], SGNS implicitly factorizes a word-con text matrix, whose cells are the shifted point-wise mutual information (PMI). The lo cal ob jective for a given word-con text pair is l S ( w i , c j ) = # ( w i , c j ) log σ W i · C T j + k · # ( w i ) · # ( c j ) Σ w #( w ) log σ − W i · C T j , (4) where σ ( x ) = 1 1+ e − x and k is the num ber of “negative” samples. T o optimize the ob jective, we find its partial deriv ativ e with resp ect to x := W i · C T j and compare it to zero: ∂ l S ∂ x = # ( w i , c j ) σ ( − x ) − k · # ( w i ) · # ( c j ) Σ w #( w ) σ ( x ) = 0 . (5) This equation is solv ed by W i · C T j = P M I ( w i , c j ) − log k = log #( w i , c j ) − log #( w i ) − log #( c j ) + log Σ w #( w ) − log k. (6) 2 2.3 Similarities b et w een the Tw o Ob jectiv es By comparing Equation 3 and 6, we find that they sho w somewhat similar forms. The log #( w i ) and log #( c j ) terms in Equation 6 can b e absorb ed into the bias terms b W i and b C j resp ectiv ely , and the log Σ w #( w ) − log k term is indep endent of i and j and can b e viewed as a global bias term, which may b e divided into the w ord and context bias terms. The bias terms in the GloV e ob jective function are unknown and are to b e determined by matrix factorization algorithms. They ma y or may not conv erge to the v alues given in the SGNS ob jective function. F rom this p ersp ective, the GloV e mo del is more general and has a wider domain for optimization. 2.4 Differences b et w een the Tw o Ob jectiv es The GloV e model and the SGNS mo del are differen t in the follo wing tw o asp ects. First, they define differen t cost functions though they share similar ob jec- tiv es, which ma y affect the p erformance when the vector dimensionalit y is not high enough. They are also different in w eighting strategies. With a well-c hosen w eight- ing function f ( x ), the GloV e mo del down-w eigh ts the significance of rare word- con text pairs and pays no attention to the unobserved pairs. Explicitly ex- pressed in “negative-sampling”, the SGNS mo del gains its success b y assuming that randomly-chosen word-con text pairs takes little or even no app earance in the corpus. Mean while, Levy and Goldb erg [1] also p oint out that rare words are do wn-weigh ted in SGNS’s ob jective shown in Equation 4. The c hoice of weigh ting function f ( x ) neglecting the unobserved w ord-con text pairs is for the sake of efficiency and also a v oiding the app earance of undefined log(0). Whether defining an ob jective for the unobserv ed w ord-con text pairs and taking adv an tage of the “negative-sampling” can improv e the p erformance remains an op en question. 3 Observ ations of the Bias T erms in the GloV e Mo del Curious ab out the optimized v alues of the bias terms in the GloV e model and the v alidity of “fixing the bias terms” to b e log #( w i ) and log #( c j ) in the SGNS mo del, we observe the trained bias terms in GloV e and compare them to the fixed term in SGNS. W e train the GloV e mo del on a Wikip edia dump with 1 . 5 billion tokens and build a vocabulary of words o ccurring no less than 100 times in the corpus. W e set x max to b e 10 or 100 and α to b e 3 / 4 in the weigh ting function f ( x ). W ord- con text pairs are counted symmetrically using the same techniques giv en by [3]. W e run 50 iterations to train 300-dimensional v ectors for words and contexts. Figure 1 shows the Pearson correlation b etw een b W i and log #( w i ), b et ween b C j and log #( c j ) and b etw een b W i + b C j and log #( w i ) + log #( c j ) with different 3 0 10 20 30 40 50 0.0 0.2 0.4 0.6 0.8 1.0 Iteration R 2 cor ( b W i , log ( #w i )) cor ( b C j , log ( #c j )) cor ( b W i + b C j , log ( #w i ) + log ( #c j )) (a) x max = 100 0 10 20 30 40 50 0.0 0.2 0.4 0.6 0.8 1.0 Iteration R 2 cor ( b W i , log ( #w i )) cor ( b C j , log ( #c j )) cor ( b W i + b C j , log ( #w i ) + log ( #c j )) (b) x max = 10 Figure 1: P earson correlation co efficient R 2 as a function of the num b er of iterations. x max v alues. Figure 2 depicts the distribution of b W i with resp ect to log #( w i ) after the first iteration and after all 50 iterations. The tw o bands in the graph may b e due to truncation of less frequen t words. W e see that b W i correlates well to log #( w i ) after 50 iterations, and that less w eighting effect (with smaller x max ) results in a higher correlation. Though not explicitly written in the ob jectiv e function, GloV e is actually optimizing W i · C T j to wards a shifted-PMI, just like what is done in the SGNS mo del. 4 Discussion W e show that interestingly , GloV e and SGNS, one explicitly factorizing a co- o ccurrence matrix and one implicitly factorizing a shifted-PMI matrix, are ac- tually sharing similar ob jectives, though not completely the same. The training ob jective of SGNS is similar to the one of a specialized form of GloV e. Their differences mainly come from differen t cost functions and weigh ting strategies. F urther we observ e that in empirical exp erimen ts, the bias terms in the GloV e mo del tend to con v erge to w ard the corresp onding terms in the SGNS mo del. W e supp ose that this may b e a go o d appro ximation for the globally optimized v alue. F uture inv estigation may fo cus on the choices of the weigh ting function and their effect on the t wo mo dels. 4 (a) x max = 100 , iter = 1 , R = 0 . 366 (b) x max = 100 , iter = 50 , R = 0 . 773 (c) x max = 10 , iter = 1 , R = 0 . 316 (d) x max = 10 , iter = 50 , R = 0 . 892 Figure 2: Distribution of b W i as a function of log #( w i ) after the first iteration and after all 50 iterations. Pearson correlation co efficients R are giv en. References [1] Omer Levy and Y oav Goldb erg. Neural w ord embedding as implicit ma- trix factorization. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , pages 2177–2185, 2014. [2] T omas Mik olov, Ily a Sutsk ever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed represen tations of w ords and phrases and their compositionality . In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , pages 3111– 3119, 2013. [3] Jeffrey Pennington, Ric hard So c her, and Christopher D Manning. Glov e: Global v ectors for w ord represen tation. In Confer enc e on Empiric al Metho ds on Natur al L anguage Pr o c essing (EMNLP) , pages 1532–1543, 2014. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment