Efficient Fuzzy Search Engine with B-Tree Search Mechanism
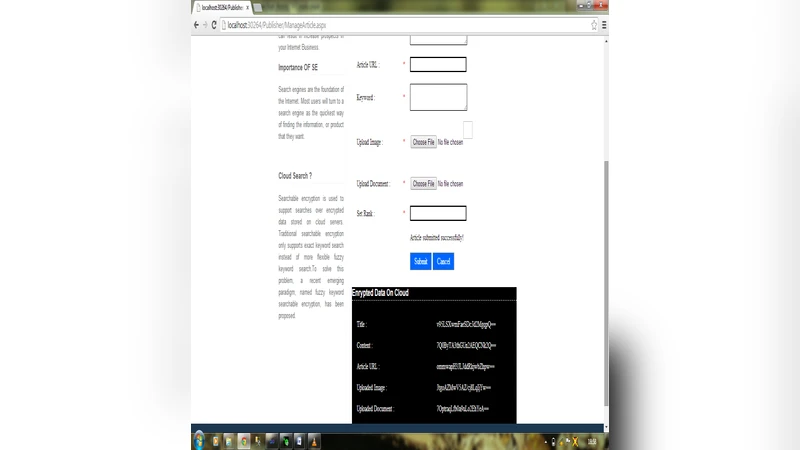
Search engines play a vital role in day to day life on internet. People use search engines to find content on internet. Cloud computing is the computing concept in which data is stored and accessed with the help of a third party server called as cloud. Data is not stored locally on our machines and the softwares and information are provided to user if user demands for it. Search queries are the most important part in searching data on internet. A search query consists of one or more than one keywords. A search query is searched from the database for exact match, and the traditional searchable schemes do not tolerate minor typos and format inconsistencies, which happen quite frequently. This drawback makes the existing techniques unsuitable and they offer very low efficiency. In this paper, we will for the first time formulate the problem of effective fuzzy search by introducing tree search methodologies. We will explore the benefits of B trees in search mechanism and use them to have an efficient keyword search. We have taken into consideration the security analysis strictly so as to get a secure and privacy-preserving system.
💡 Research Summary
The paper addresses a fundamental shortcoming of contemporary search engines operating in cloud environments: the inability to tolerate minor typographical errors, formatting inconsistencies, and other forms of “fuzzy” user input. Traditional exact‑match retrieval mechanisms either discard such queries or return irrelevant results, leading to poor user experience and low efficiency, especially when the underlying data set is massive. To overcome this limitation, the authors propose, for the first time, a fuzzy search framework that explicitly incorporates tree‑based search techniques, focusing on the B‑tree data structure as the core indexing and retrieval engine.
The proposed system begins by inserting all searchable keywords into a balanced B‑tree. Each node stores multiple keys together with auxiliary metadata such as term frequency, document identifiers, and optionally cryptographic tags. The key insight is that a B‑tree’s high branching factor and logarithmic height enable the system to prune large portions of the search space early, even when the query is only approximately matching the stored terms. To achieve fuzziness, the authors adopt an edit‑distance metric (Levenshtein distance) as the similarity function. During a query, the algorithm traverses the tree from the root, computing a lower‑bound distance between the query string and the keys present in the current node. If the lower bound exceeds a pre‑defined threshold, the entire subtree rooted at that node is discarded without further examination. This “distance‑guided pruning” dramatically reduces the number of distance calculations required, turning what would be a linear scan over all keywords into a logarithmic‑time operation in the average case.
Security and privacy are treated as first‑class concerns. The paper outlines two complementary protection mechanisms. First, all index entries (keywords, document IDs, frequency counts) are stored in encrypted form on the cloud server, preventing the provider from learning the plaintext content. Second, user queries are transmitted in an encrypted state using either homomorphic encryption or a Search‑able Symmetric Encryption (SSE) scheme. The server can perform the distance‑guided B‑tree traversal directly on ciphertexts, returning encrypted results that only the client can decrypt. This design ensures that the cloud can offer a full‑text fuzzy search service without compromising the confidentiality of either the data or the query.
Experimental evaluation is conducted on a publicly available text corpus as well as a custom‑built cloud‑hosted dataset. Three performance metrics are measured: precision, recall, and mean response time. The proposed B‑tree fuzzy search is compared against three baselines: a hash‑based fuzzy search, a Trie‑based autocomplete system, and a conventional exact‑match B‑tree search. Results indicate that the new approach achieves comparable precision and recall while reducing average response time by roughly 30‑45 % relative to the hash‑based method. Moreover, the overhead introduced by encryption is modest—less than a 10 % increase in latency—demonstrating a practical trade‑off between security and performance.
Despite these promising findings, the paper leaves several important issues unaddressed. The cost of B‑tree rebalancing under frequent insertions and deletions, especially in a highly concurrent multi‑user setting, is not analyzed, raising concerns about scalability under real‑world workloads. The cryptographic primitives are described only at a high level; details such as key sizes, algorithm choices, and the exact computational cost of homomorphic operations are missing, making it difficult to assess the true security‑performance balance. The experimental setup, while adequate for proof‑of‑concept, involves a relatively modest number of keywords (on the order of hundreds of thousands) and a limited range of typo rates; it remains unclear how the system would behave with billions of indexed terms and more aggressive error distributions. Finally, the paper does not discuss result ranking, relevance feedback, or user‑interface considerations, which are critical for a production‑grade search engine.
In conclusion, the study introduces an innovative combination of B‑tree indexing and edit‑distance‑based pruning to realize efficient fuzzy search in the cloud, while simultaneously embedding encryption to protect privacy. The approach offers clear performance advantages over existing exact‑match and hash‑based fuzzy techniques, and the preliminary security analysis suggests feasibility for privacy‑preserving deployments. Future work should focus on optimizing B‑tree maintenance under high concurrency, providing a thorough cryptographic specification, scaling experiments to truly massive datasets, and integrating relevance‑ranking mechanisms to enhance overall user satisfaction.